 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelax DARTS: Relaxing the Constraints of Differentiable Architecture Search for Eye Movement Recognition
Sep 18, 2024



Eye movement biometrics is a secure and innovative identification method. Deep learning methods have shown good performance, but their network architecture relies on manual design and combined priori knowledge. To address these issues, we introduce automated network search (NAS) algorithms to the field of eye movement recognition and present Relax DARTS, which is an improvement of the Differentiable Architecture Search (DARTS) to realize more efficient network search and training. The key idea is to circumvent the issue of weight sharing by independently training the architecture parameters $\alpha$ to achieve a more precise target architecture. Moreover, the introduction of module input weights $\beta$ allows cells the flexibility to select inputs, to alleviate the overfitting phenomenon and improve the model performance. Results on four public databases demonstrate that the Relax DARTS achieves state-of-the-art recognition performance. Notably, Relax DARTS exhibits adaptability to other multi-feature temporal classification tasks.
SUMix: Mixup with Semantic and Uncertain Information
Jul 10, 2024
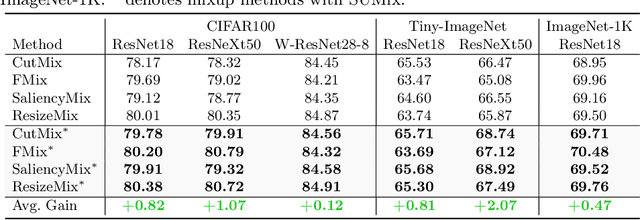
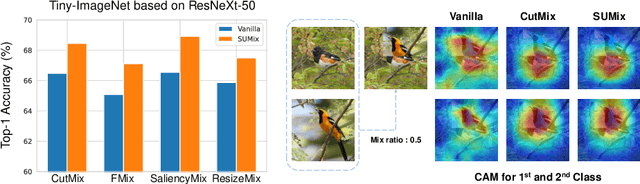
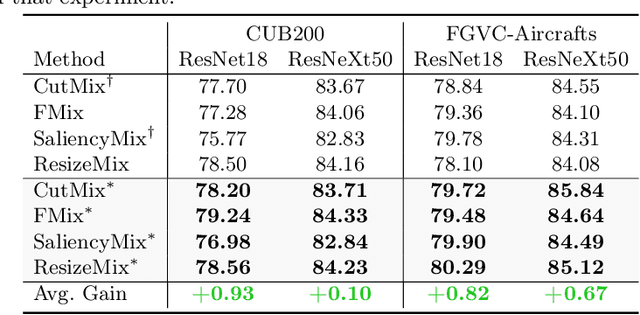
Mixup data augmentation approaches have been applied for various tasks of deep learning to improve the generalization ability of deep neural networks. Some existing approaches CutMix, SaliencyMix, etc. randomly replace a patch in one image with patches from another to generate the mixed image. Similarly, the corresponding labels are linearly combined by a fixed ratio $\lambda$ by l. The objects in two images may be overlapped during the mixing process, so some semantic information is corrupted in the mixed samples. In this case, the mixed image does not match the mixed label information. Besides, such a label may mislead the deep learning model training, which results in poor performance. To solve this problem, we proposed a novel approach named SUMix to learn the mixing ratio as well as the uncertainty for the mixed samples during the training process. First, we design a learnable similarity function to compute an accurate mix ratio. Second, an approach is investigated as a regularized term to model the uncertainty of the mixed samples. We conduct experiments on five image benchmarks, and extensive experimental results imply that our method is capable of improving the performance of classifiers with different cutting-based mixup approaches. The source code is available at https://github.com/JinXins/SUMix.
StarLKNet: Star Mixup with Large Kernel Networks for Palm Vein Identification
May 21, 2024



As a representative of a new generation of biometrics, vein identification technology offers a high level of security and convenience. Convolutional neural networks (CNNs), a prominent class of deep learning architectures, have been extensively utilized for vein identification. Since their performance and robustness are limited by small Effective Receptive Fields (e.g. 3$\times$3 kernels) and insufficient training samples, however, they are unable to extract global feature representations from vein images in an effective manner. To address these issues, we propose StarLKNet, a large kernel convolution-based palm-vein identification network, with the Mixup approach. Our StarMix learns effectively the distribution of vein features to expand samples. To enable CNNs to capture comprehensive feature representations from palm-vein images, we explored the effect of convolutional kernel size on the performance of palm-vein identification networks and designed LaKNet, a network leveraging large kernel convolution and gating mechanism. In light of the current state of knowledge, this represents an inaugural instance of the deployment of a CNN with large kernels in the domain of vein identification. Extensive experiments were conducted to validate the performance of StarLKNet on two public palm-vein datasets. The results demonstrated that StarMix provided superior augmentation, and LakNet exhibited more stable performance gains compared to mainstream approaches, resulting in the highest recognition accuracy and lowest identification error.