 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Transformer for Early Alzheimer's Detection: Integration of Handwriting-Based 2D Images and 1D Signal Features
Oct 14, 2024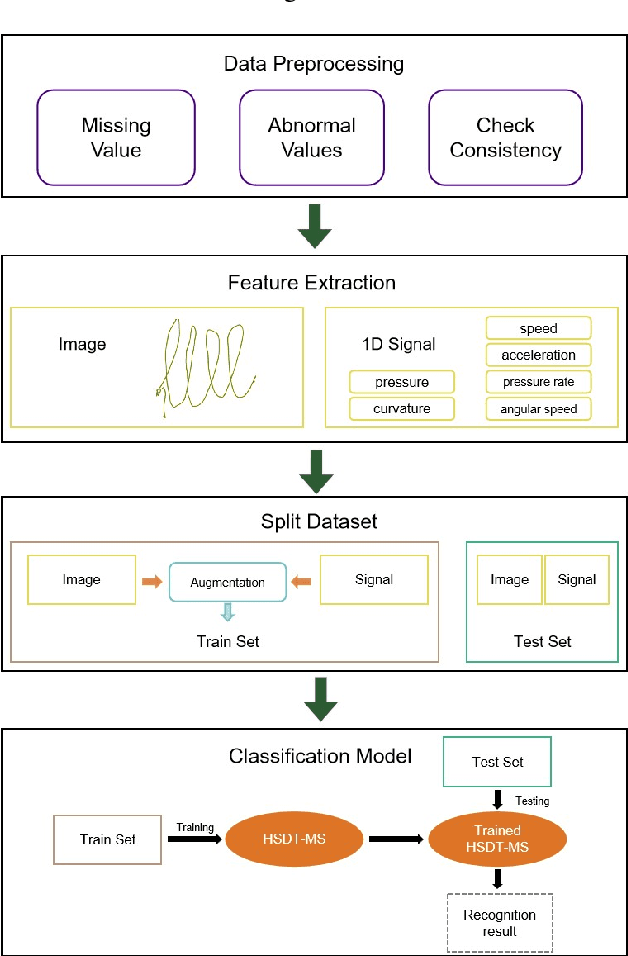
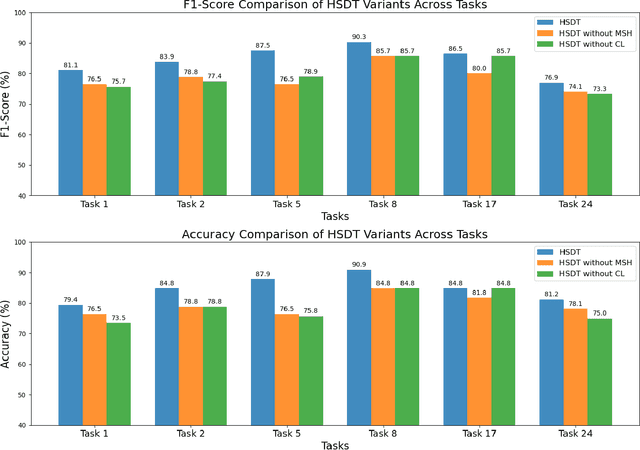


Alzheimer's Disease (AD) is a prevalent neurodegenerative condition where early detection is vital. Handwriting, often affected early in AD, offers a non-invasive and cost-effective way to capture subtle motor changes. State-of-the-art research on handwriting, mostly online, based AD detection has predominantly relied on manually extracted features, fed as input to shallow machine learning models. Some recent works have proposed deep learning (DL)-based models, either 1D-CNN or 2D-CNN architectures, with performance comparing favorably to handcrafted schemes. These approaches, however, overlook the intrinsic relationship between the 2D spatial patterns of handwriting strokes and their 1D dynamic characteristics, thus limiting their capacity to capture the multimodal nature of handwriting data. Moreover, the application of Transformer models remains basically unexplored. To address these limitations, we propose a novel approach for AD detection, consisting of a learnable multimodal hybrid attention model that integrates simultaneously 2D handwriting images with 1D dynamic handwriting signals. Our model leverages a gated mechanism to combine similarity and difference attention, blending the two modalities and learning robust features by incorporating information at different scales. Our model achieved state-of-the-art performance on the DARWIN dataset, with an F1-score of 90.32\% and accuracy of 90.91\% in Task 8 ('L' writing), surpassing the previous best by 4.61% and 6.06% respectively.
SUMix: Mixup with Semantic and Uncertain Information
Jul 10, 2024
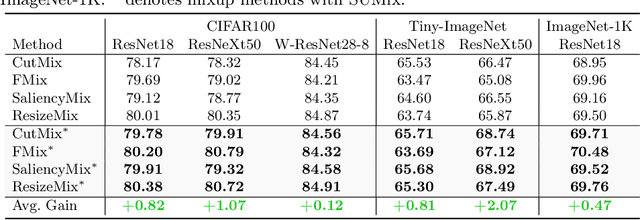
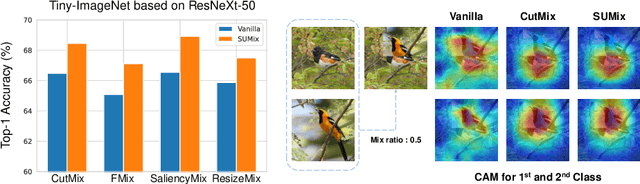
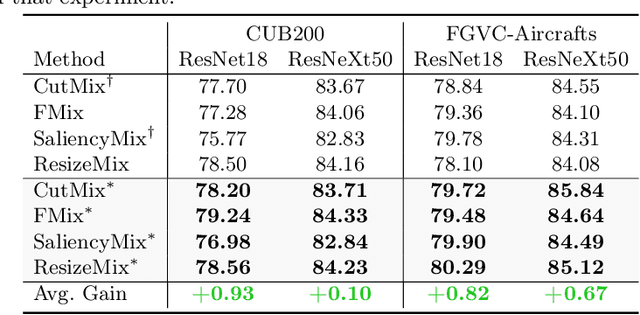
Mixup data augmentation approaches have been applied for various tasks of deep learning to improve the generalization ability of deep neural networks. Some existing approaches CutMix, SaliencyMix, etc. randomly replace a patch in one image with patches from another to generate the mixed image. Similarly, the corresponding labels are linearly combined by a fixed ratio $\lambda$ by l. The objects in two images may be overlapped during the mixing process, so some semantic information is corrupted in the mixed samples. In this case, the mixed image does not match the mixed label information. Besides, such a label may mislead the deep learning model training, which results in poor performance. To solve this problem, we proposed a novel approach named SUMix to learn the mixing ratio as well as the uncertainty for the mixed samples during the training process. First, we design a learnable similarity function to compute an accurate mix ratio. Second, an approach is investigated as a regularized term to model the uncertainty of the mixed samples. We conduct experiments on five image benchmarks, and extensive experimental results imply that our method is capable of improving the performance of classifiers with different cutting-based mixup approaches. The source code is available at https://github.com/JinXins/SUMix.