 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarLKNet: Star Mixup with Large Kernel Networks for Palm Vein Identification
May 21, 2024



As a representative of a new generation of biometrics, vein identification technology offers a high level of security and convenience. Convolutional neural networks (CNNs), a prominent class of deep learning architectures, have been extensively utilized for vein identification. Since their performance and robustness are limited by small Effective Receptive Fields (e.g. 3$\times$3 kernels) and insufficient training samples, however, they are unable to extract global feature representations from vein images in an effective manner. To address these issues, we propose StarLKNet, a large kernel convolution-based palm-vein identification network, with the Mixup approach. Our StarMix learns effectively the distribution of vein features to expand samples. To enable CNNs to capture comprehensive feature representations from palm-vein images, we explored the effect of convolutional kernel size on the performance of palm-vein identification networks and designed LaKNet, a network leveraging large kernel convolution and gating mechanism. In light of the current state of knowledge, this represents an inaugural instance of the deployment of a CNN with large kernels in the domain of vein identification. Extensive experiments were conducted to validate the performance of StarLKNet on two public palm-vein datasets. The results demonstrated that StarMix provided superior augmentation, and LakNet exhibited more stable performance gains compared to mainstream approaches, resulting in the highest recognition accuracy and lowest identification error.
Integration of Clinical Criteria into the Training of Deep Models: Application to Glucose Prediction for Diabetic People
Sep 23, 2020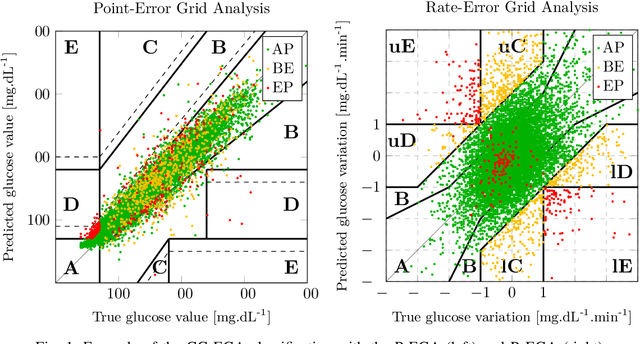


Standard objective functions used during the training of neural-network-based predictive models do not consider clinical criteria, leading to models that are not necessarily clinically acceptable. In this study, we look at this problem from the perspective of the forecasting of future glucose values for diabetic people. In this study, we propose the coherent mean squared glycemic error (gcMSE) loss function. It penalizes the model during its training not only of the prediction errors, but also on the predicted variation errors which is important in glucose prediction. Moreover, it makes possible to adjust the weighting of the different areas in the error space to better focus on dangerous regions. In order to use the loss function in practice, we propose an algorithm that progressively improves the clinical acceptability of the model, so that we can achieve the best tradeoff possible between accuracy and given clinical criteria. We evaluate the approaches using two diabetes datasets, one having type-1 patients and the other type-2 patients. The results show that using the gcMSE loss function, instead of a standard MSE loss function, improves the clinical acceptability of the models. In particular, the improvements are significant in the hypoglycemia region. We also show that this increased clinical acceptability comes at the cost of a decrease in the average accuracy of the model. Finally, we show that this tradeoff between accuracy and clinical acceptability can be successfully addressed with the proposed algorithm. For given clinical criteria, the algorithm can find the optimal solution that maximizes the accuracy while at the same meeting the criteria.
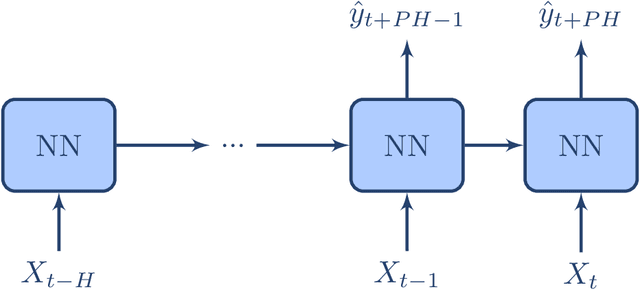
Enhancing the Interpretability of Deep Models in Heathcare Through Attention: Application to Glucose Forecasting for Diabetic People
Sep 08, 2020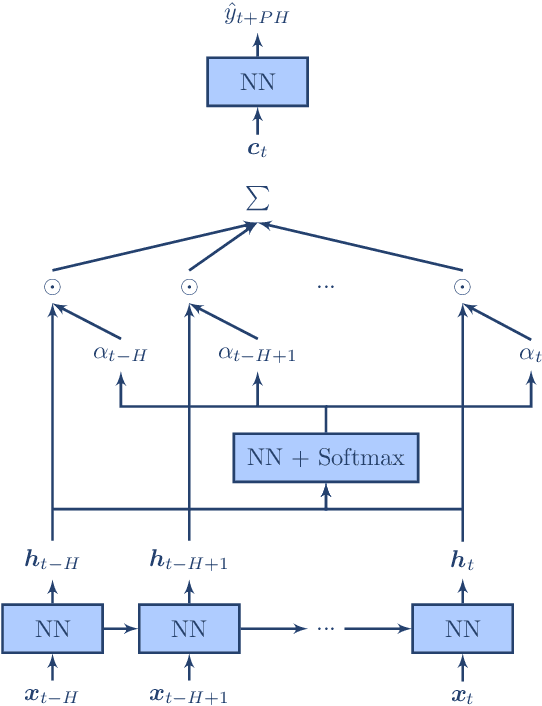
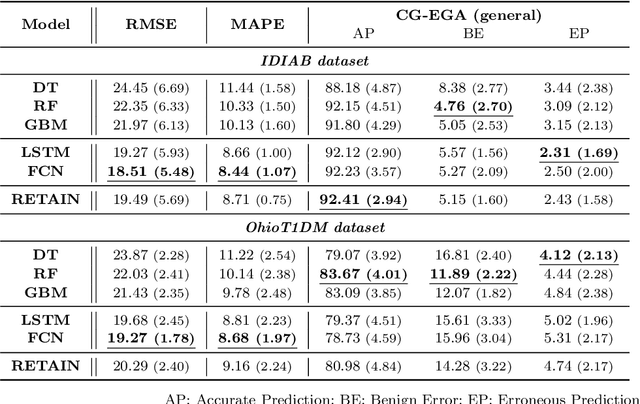
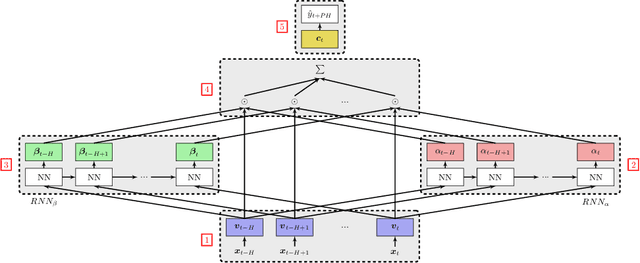

The adoption of deep learning in healthcare is hindered by their "black box" nature. In this paper, we explore the RETAIN architecture for the task of glusose forecasting for diabetic people. By using a two-level attention mechanism, the recurrent-neural-network-based RETAIN model is interpretable. We evaluate the RETAIN model on the type-2 IDIAB and the type-1 OhioT1DM datasets by comparing its statistical and clinical performances against two deep models and three models based on decision trees. We show that the RETAIN model offers a very good compromise between accuracy and interpretability, being almost as accurate as the LSTM and FCN models while remaining interpretable. We show the usefulness of its interpretable nature by analyzing the contribution of each variable to the final prediction. It revealed that signal values older than one hour are not used by the RETAIN model for the 30-minutes ahead of time prediction of glucose. Also, we show how the RETAIN model changes its behavior upon the arrival of an event such as carbohydrate intakes or insulin infusions. In particular, it showed that the patient's state before the event is particularily important for the prediction. Overall the RETAIN model, thanks to its interpretability, seems to be a very promissing model for regression or classification tasks in healthcare.
Interpreting Deep Glucose Predictive Models for Diabetic People Using RETAIN
Sep 08, 2020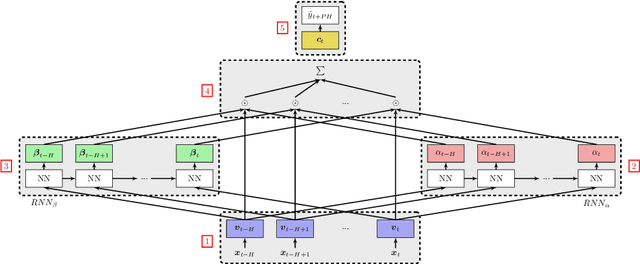

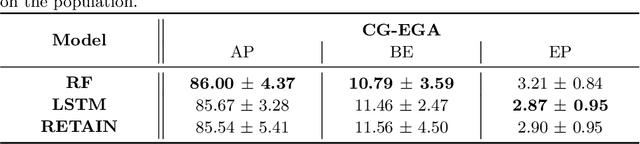

Progress in the biomedical field through the use of deep learning is hindered by the lack of interpretability of the models. In this paper, we study the RETAIN architecture for the forecasting of future glucose values for diabetic people. Thanks to its two-level attention mechanism, the RETAIN model is interpretable while remaining as efficient as standard neural networks. We evaluate the model on a real-world type-2 diabetic population and we compare it to a random forest model and a LSTM-based recurrent neural network. Our results show that the RETAIN model outperforms the former and equals the latter on common accuracy metrics and clinical acceptability metrics, thereby proving its legitimacy in the context of glucose level forecasting. Furthermore, we propose tools to take advantage of the RETAIN interpretable nature. As informative for the patients as for the practitioners, it can enhance the understanding of the predictions made by the model and improve the design of future glucose predictive models.
Prediction-Coherent LSTM-based Recurrent Neural Network for Safer Glucose Predictions in Diabetic People
Sep 08, 2020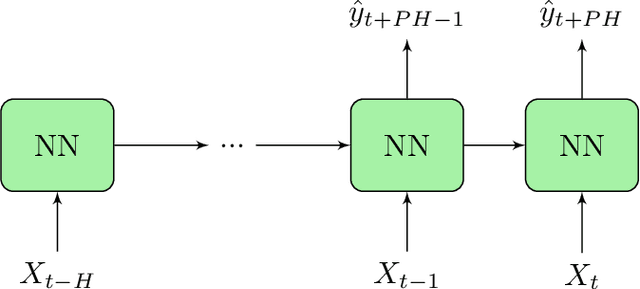
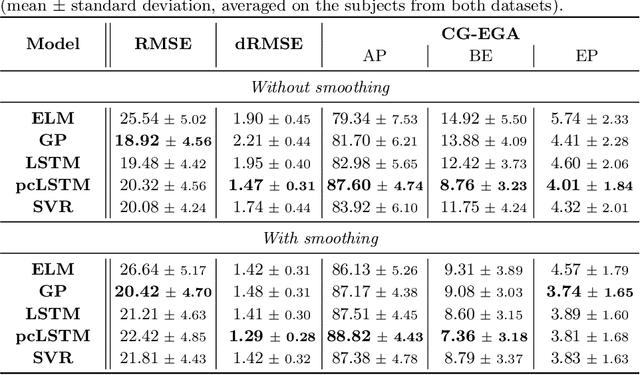
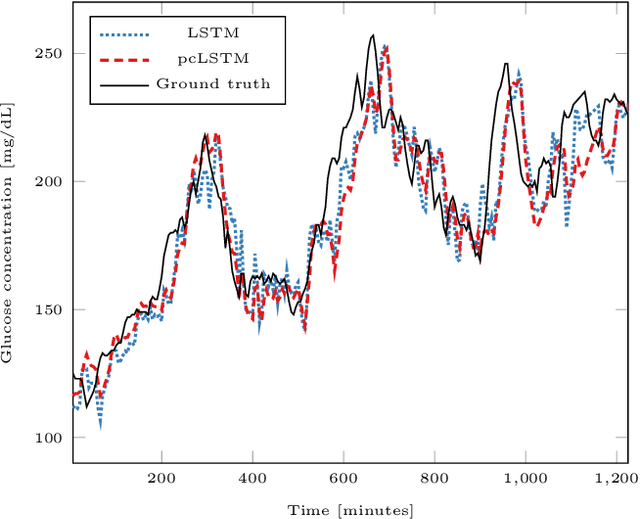
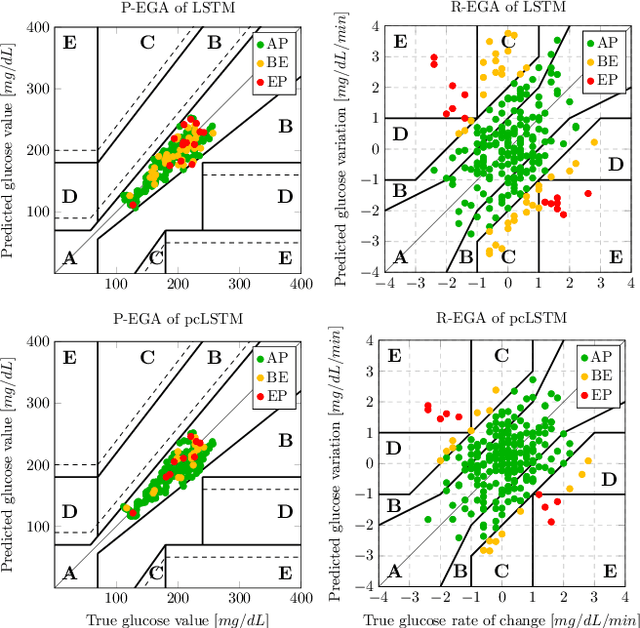
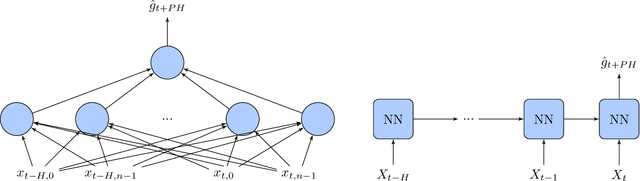
In the context of time-series forecasting, we propose a LSTM-based recurrent neural network architecture and loss function that enhance the stability of the predictions. In particular, the loss function penalizes the model, not only on the prediction error (mean-squared error), but also on the predicted variation error. We apply this idea to the prediction of future glucose values in diabetes, which is a delicate task as unstable predictions can leave the patient in doubt and make him/her take the wrong action, threatening his/her life. The study is conducted on type 1 and type 2 diabetic people, with a focus on predictions made 30-minutes ahead of time. First, we confirm the superiority, in the context of glucose prediction, of the LSTM model by comparing it to other state-of-the-art models (Extreme Learning Machine, Gaussian Process regressor, Support Vector Regressor). Then, we show the importance of making stable predictions by smoothing the predictions made by the models, resulting in an overall improvement of the clinical acceptability of the models at the cost in a slight loss in prediction accuracy. Finally, we show that the proposed approach, outperforms all baseline results. More precisely, it trades a loss of 4.3\% in the prediction accuracy for an improvement of the clinical acceptability of 27.1\%. When compared to the moving average post-processing method, we show that the trade-off is more efficient with our approach.
GLYFE: Review and Benchmark of Personalized Glucose Predictive Models in Type-1 Diabetes
Jun 29, 2020
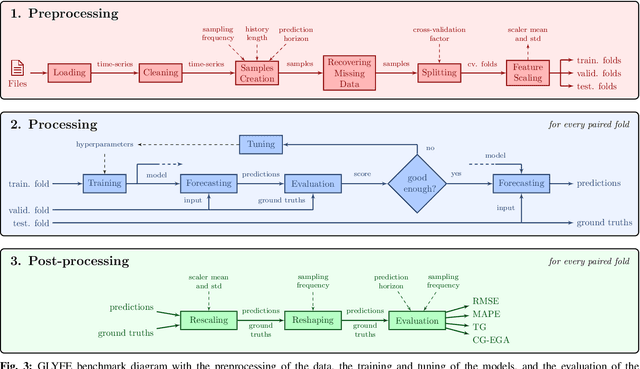
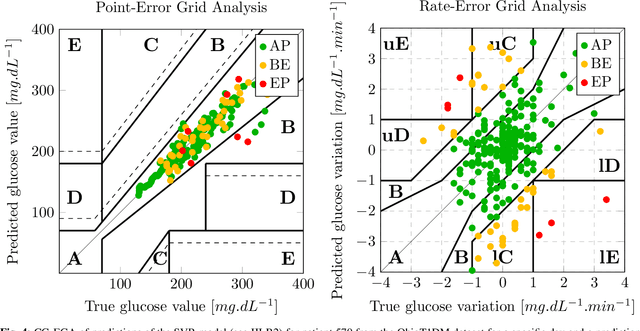
Due to the sensitive nature of diabetes-related data, preventing them from being shared between studies, progress in the field of glucose prediction is hard to assess. To address this issue, we present GLYFE (GLYcemia Forecasting Evaluation), a benchmark of machine-learning-based glucose-predictive models. To ensure the reproducibility of the results and the usability of the benchmark in the future, we provide extensive details about the data flow. Two datasets are used, the first comprising 10 in-silico adults from the UVA/Padova Type 1 Diabetes Metabolic Simulator (T1DMS) and the second being made of 6 real type-1 diabetic patients coming from the OhioT1DM dataset. The predictive models are personalized to the patient and evaluated on 3 different prediction horizons (30, 60, and 120 minutes) with metrics assessing their accuracy and clinical acceptability. The results of nine different models coming from the glucose-prediction literature are presented. First, they show that standard autoregressive linear models are outclassed by kernel-based non-linear ones and neural networks. In particular, the support vector regression model stands out, being at the same time one of the most accurate and clinically acceptable model. Finally, the relative performances of the models are the same for both datasets. This shows that, even though data simulated by T1DMS are not fully representative of real-world data, they can be used to assess the forecasting ability of the glucose-predictive models. Those results serve as a basis of comparison for future studies. In a field where data are hard to obtain, and where the comparison of results from different studies is often irrelevant, GLYFE gives the opportunity of gathering researchers around a standardized common environment.
Adversarial Multi-Source Transfer Learning in Healthcare: Application to Glucose Prediction for Diabetic People
Jun 29, 2020
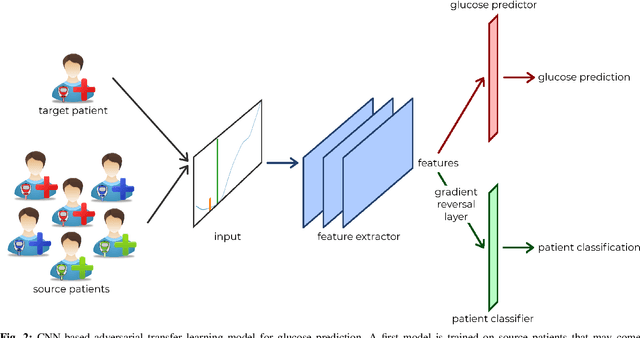
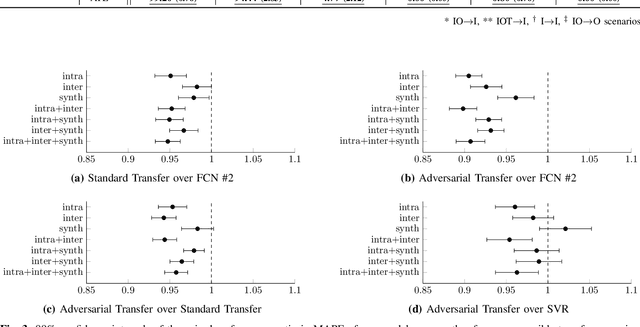

Deep learning has yet to revolutionize general practices in healthcare, despite promising results for some specific tasks. This is partly due to data being in insufficient quantities hurting the training of the models. To address this issue, data from multiple health actors or patients could be combined by capitalizing on their heterogeneity through the use of transfer learning. To improve the quality of the transfer between multiple sources of data, we propose a multi-source adversarial transfer learning framework that enables the learning of a feature representation that is similar across the sources, and thus more general and more easily transferable. We apply this idea to glucose forecasting for diabetic people using a fully convolutional neural network. The evaluation is done by exploring various transfer scenarios with three datasets characterized by their high inter and intra variability. While transferring knowledge is beneficial in general, we show that the statistical and clinical accuracies can be further improved by using of the adversarial training methodology, surpassing the current state-of-the-art results. In particular, it shines when using data from different datasets, or when there is too little data in an intra-dataset situation. To understand the behavior of the models, we analyze the learnt feature representations and propose a new metric in this regard. Contrary to a standard transfer, the adversarial transfer does not discriminate the patients and datasets, helping the learning of a more general feature representation. The adversarial training framework improves the learning of a general feature representation in a multi-source environment, enhancing the knowledge transfer to an unseen target. The proposed method can help improve the efficiency of data shared by different health actors in the training of deep models.