 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLYFE: Review and Benchmark of Personalized Glucose Predictive Models in Type-1 Diabetes
Paper and Code
Jun 29, 2020
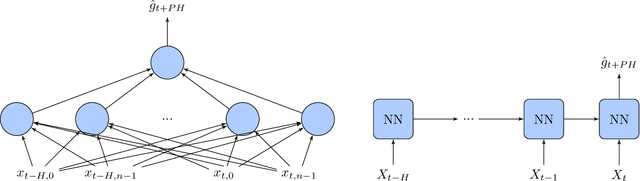
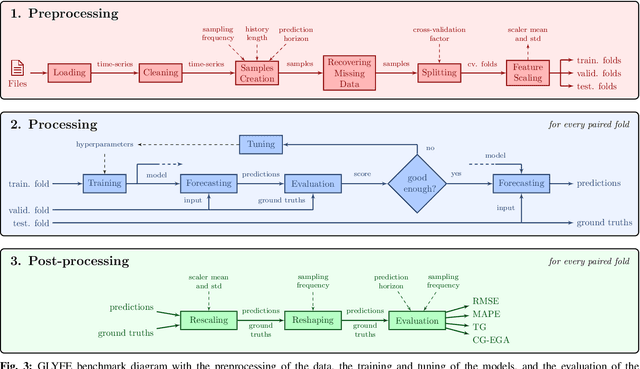
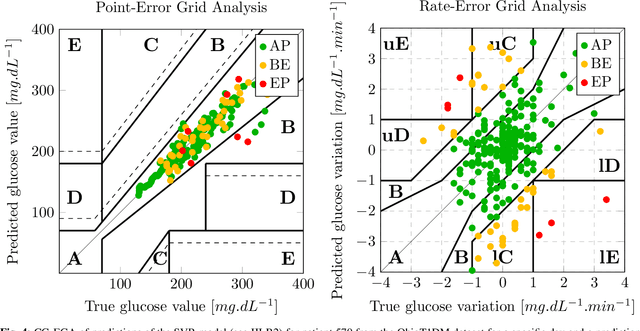
Due to the sensitive nature of diabetes-related data, preventing them from being shared between studies, progress in the field of glucose prediction is hard to assess. To address this issue, we present GLYFE (GLYcemia Forecasting Evaluation), a benchmark of machine-learning-based glucose-predictive models. To ensure the reproducibility of the results and the usability of the benchmark in the future, we provide extensive details about the data flow. Two datasets are used, the first comprising 10 in-silico adults from the UVA/Padova Type 1 Diabetes Metabolic Simulator (T1DMS) and the second being made of 6 real type-1 diabetic patients coming from the OhioT1DM dataset. The predictive models are personalized to the patient and evaluated on 3 different prediction horizons (30, 60, and 120 minutes) with metrics assessing their accuracy and clinical acceptability. The results of nine different models coming from the glucose-prediction literature are presented. First, they show that standard autoregressive linear models are outclassed by kernel-based non-linear ones and neural networks. In particular, the support vector regression model stands out, being at the same time one of the most accurate and clinically acceptable model. Finally, the relative performances of the models are the same for both datasets. This shows that, even though data simulated by T1DMS are not fully representative of real-world data, they can be used to assess the forecasting ability of the glucose-predictive models. Those results serve as a basis of comparison for future studies. In a field where data are hard to obtain, and where the comparison of results from different studies is often irrelevant, GLYFE gives the opportunity of gathering researchers around a standardized common environment.