 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM-SEVIQ: A Multi-band Stereo Event Visual-Inertial Quadruped-based Dataset for Perception under Rapid Motion and Challenging Illumination
Jan 06, 2026Agile locomotion in legged robots poses significant challenges for visual perception. Traditional frame-based cameras often fail in these scenarios for producing blurred images, particularly under low-light conditions. In contrast, event cameras capture changes in brightness asynchronously, offering low latency, high temporal resolution, and high dynamic range. These advantages make them suitable for robust perception during rapid motion and under challenging illumination. However, existing event camera datasets exhibit limitations in stereo configurations and multi-band sensing domains under various illumination conditions. To address this gap, we present M-SEVIQ, a multi-band stereo event visual and inertial quadruped dataset collected using a Unitree Go2 equipped with stereo event cameras, a frame-based camera, an inertial measurement unit (IMU), and joint encoders. This dataset contains more than 30 real-world sequences captured across different velocity levels, illumination wavelengths, and lighting conditions. In addition, comprehensive calibration data, including intrinsic, extrinsic, and temporal alignments, are provided to facilitate accurate sensor fusion and benchmarking. Our M-SEVIQ can be used to support research in agile robot perception, sensor fusion, semantic segmentation and multi-modal vision in challenging environments.
A2I-Calib: An Anti-noise Active Multi-IMU Spatial-temporal Calibration Framework for Legged Robots
Mar 10, 2025



Recently, multi-node inertial measurement unit (IMU)-based odometry for legged robots has gained attention due to its cost-effectiveness, power efficiency, and high accuracy. However, the spatial and temporal misalignment between foot-end motion derived from forward kinematics and foot IMU measurements can introduce inconsistent constraints, resulting in odometry drift. Therefore, accurate spatial-temporal calibration is crucial for the multi-IMU systems. Although existing multi-IMU calibration methods have addressed passive single-rigid-body sensor calibration, they are inadequate for legged systems. This is due to the insufficient excitation from traditional gaits for calibration, and enlarged sensitivity to IMU noise during kinematic chain transformations. To address these challenges, we propose A$^2$I-Calib, an anti-noise active multi-IMU calibration framework enabling autonomous spatial-temporal calibration for arbitrary foot-mounted IMUs. Our A$^2$I-Calib includes: 1) an anti-noise trajectory generator leveraging a proposed basis function selection theorem to minimize the condition number in correlation analysis, thus reducing noise sensitivity, and 2) a reinforcement learning (RL)-based controller that ensures robust execution of calibration motions. Furthermore, A$^2$I-Calib is validated on simulation and real-world quadruped robot platforms with various multi-IMU settings, which demonstrates a significant reduction in noise sensitivity and calibration errors, thereby improving the overall multi-IMU odometry performance.
THE-SEAN: A Heart Rate Variation-Inspired Temporally High-Order Event-Based Visual Odometry with Self-Supervised Spiking Event Accumulation Networks
Mar 07, 2025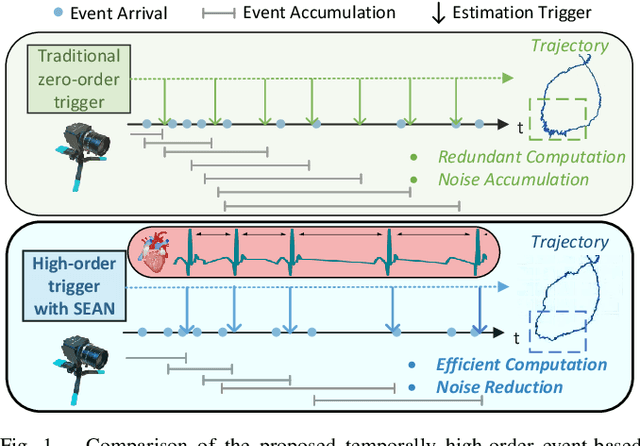
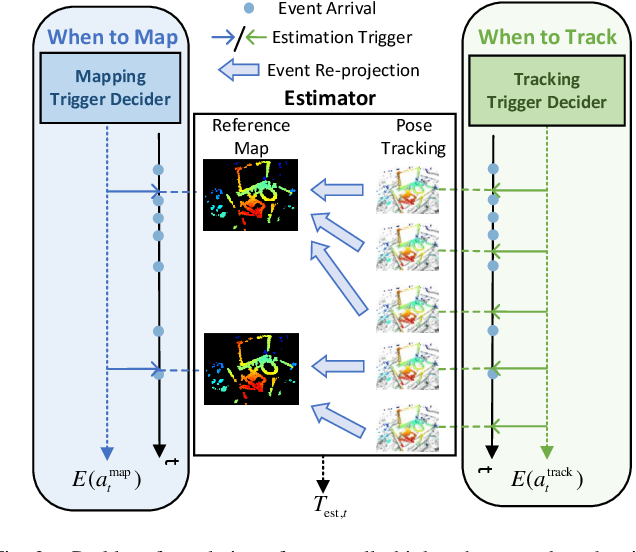
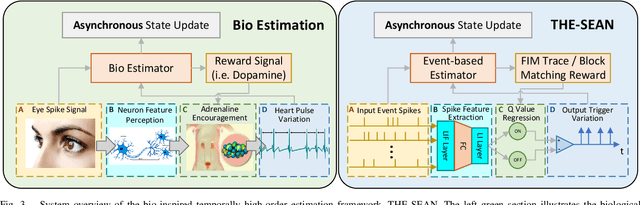
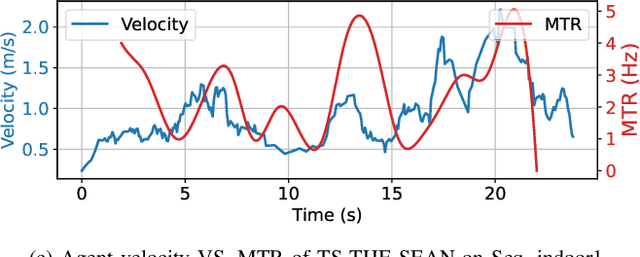
Event-based visual odometry has recently gained attention for its high accuracy and real-time performance in fast-motion systems. Unlike traditional synchronous estimators that rely on constant-frequency (zero-order) triggers, event-based visual odometry can actively accumulate information to generate temporally high-order estimation triggers. However, existing methods primarily focus on adaptive event representation after estimation triggers, neglecting the decision-making process for efficient temporal triggering itself. This oversight leads to the computational redundancy and noise accumulation. In this paper, we introduce a temporally high-order event-based visual odometry with spiking event accumulation networks (THE-SEAN). To the best of our knowledge, it is the first event-based visual odometry capable of dynamically adjusting its estimation trigger decision in response to motion and environmental changes. Inspired by biological systems that regulate hormone secretion to modulate heart rate, a self-supervised spiking neural network is designed to generate estimation triggers. This spiking network extracts temporal features to produce triggers, with rewards based on block matching points and Fisher information matrix (FIM) trace acquired from the estimator itself. Finally, THE-SEAN is evaluated across several open datasets, thereby demonstrating average improvements of 13\% in estimation accuracy, 9\% in smoothness, and 38\% in triggering efficiency compared to the state-of-the-art methods.
IMOST: Incremental Memory Mechanism with Online Self-Supervision for Continual Traversability Learning
Sep 21, 2024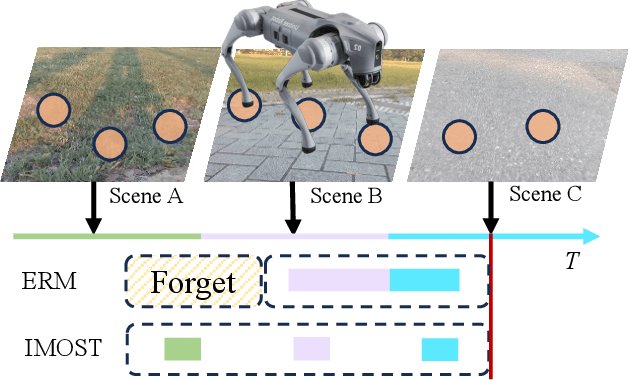
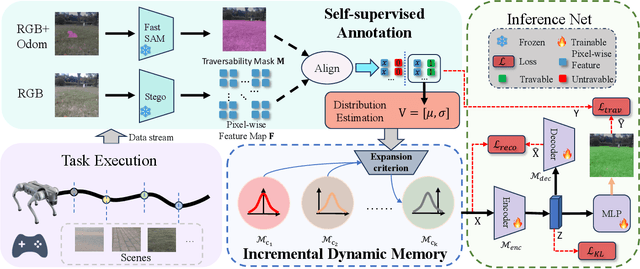


Traversability estimation is the foundation of path planning for a general navigation system. However, complex and dynamic environments pose challenges for the latest methods using self-supervised learning (SSL) technique. Firstly, existing SSL-based methods generate sparse annotations lacking detailed boundary information. Secondly, their strategies focus on hard samples for rapid adaptation, leading to forgetting and biased predictions. In this work, we propose IMOST, a continual traversability learning framework composed of two key modules: incremental dynamic memory (IDM) and self-supervised annotation (SSA). By mimicking human memory mechanisms, IDM allocates novel data samples to new clusters according to information expansion criterion. It also updates clusters based on diversity rule, ensuring a representative characterization of new scene. This mechanism enhances scene-aware knowledge diversity while maintaining a compact memory capacity. The SSA module, integrating FastSAM, utilizes point prompts to generate complete annotations in real time which reduces training complexity. Furthermore, IMOST has been successfully deployed on the quadruped robot, with performance evaluated during the online learning process. Experimental results on both public and self-collected datasets demonstrate that our IMOST outperforms current state-of-the-art method, maintains robust recognition capabilities and adaptability across various scenarios. The code is available at https://github.com/SJTU-MKH/OCLTrav.
TON-VIO: Online Time Offset Modeling Networks for Robust Temporal Alignment in High Dynamic Motion VIO
Mar 19, 2024Temporal misalignment (time offset) between sensors is common in low cost visual-inertial odometry (VIO) systems. Such temporal misalignment introduces inconsistent constraints for state estimation, leading to a significant positioning drift especially in high dynamic motion scenarios. In this article, we focus on online temporal calibration to reduce the positioning drift caused by the time offset for high dynamic motion VIO. For the time offset observation model, most existing methods rely on accurate state estimation or stable visual tracking. For the prediction model, current methods oversimplify the time offset as a constant value with white Gaussian noise. However, these ideal conditions are seldom satisfied in real high dynamic scenarios, resulting in the poor performance. In this paper, we introduce online time offset modeling networks (TON) to enhance real-time temporal calibration. TON improves the accuracy of time offset observation and prediction modeling. Specifically, for observation modeling, we propose feature velocity observation networks to enhance velocity computation for features in unstable visual tracking conditions. For prediction modeling, we present time offset prediction networks to learn its evolution pattern. To highlight the effectiveness of our method, we integrate the proposed TON into both optimization-based and filter-based VIO systems. Simulation and real-world experiments are conducted to demonstrate the enhanced performance of our approach. Additionally, to contribute to the VIO community, we will open-source the code of our method on: https://github.com/Franky-X/FVON-TPN.