 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSTrack: Bootstrap End-to-End Multi-Camera 3D Multi-object Tracking with Hybrid Supervision
Nov 11, 2024



In camera-based 3D multi-object tracking (MOT), the prevailing methods follow the tracking-by-query-propagation paradigm, which employs track queries to manage the lifecycle of identity-consistent tracklets while object queries handle the detection of new-born tracklets. However, this intertwined paradigm leads the inter-temporal tracking task and the single-frame detection task utilize the same model parameters, complicating training optimization. Drawing inspiration from studies on the roles of attention components in transformer-based decoders, we identify that the dispersing effect of self-attention necessitates object queries to match with new-born tracklets. This matching strategy diverges from the detection pre-training phase, where object queries align with all ground-truth targets, resulting in insufficient supervision signals. To address these issues, we present HSTrack, a novel plug-and-play method designed to co-facilitate multi-task learning for detection and tracking. HSTrack constructs a parallel weight-share decoder devoid of self-attention layers, circumventing competition between different types of queries. Considering the characteristics of cross-attention layer and distinct query types, our parallel decoder adopt one-to-one and one-to-many label assignment strategies for track queries and object queries, respectively. Leveraging the shared architecture, HSTrack further improve trackers for spatio-temporal modeling and quality candidates generation. Extensive experiments demonstrate that HSTrack consistently delivers improvements when integrated with various query-based 3D MOT trackers. For example, HSTrack improves the state-of-the-art PF-Track method by $+2.3\%$ AMOTA and $+1.7\%$ mAP on the nuScenes dataset.
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Apr 18, 2024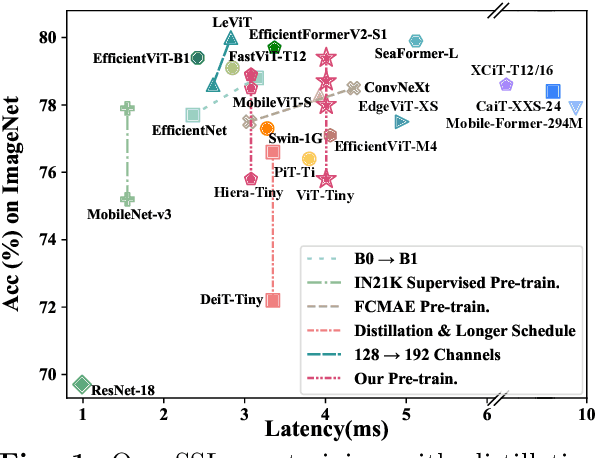
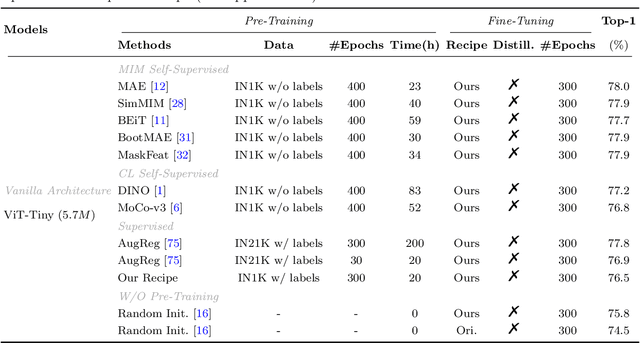

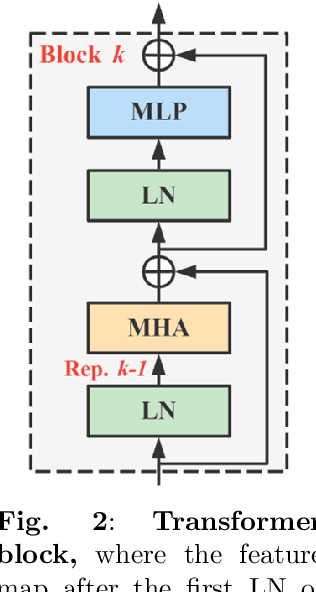
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) in computer vision has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the extremely simple ViTs' fine-tuning performance with a small-scale architecture can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology with sophisticated components introduced. By carefully adapting various typical MIM pre-training methods to this lightweight regime and comparing them with the contrastive learning (CL) pre-training on various downstream image classification and dense prediction tasks, we systematically observe different behaviors between MIM and CL with respect to the downstream fine-tuning data scales. Furthermore, we analyze the frozen features under linear probing evaluation and also the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory fine-tuning performance on data-insufficient downstream tasks. This finding is naturally a guide to choosing appropriate distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments on various vision tasks demonstrate the effectiveness of our observation-analysis-solution flow. In particular, our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design (5.7M/6.5M) can achieve 79.4%/78.9% top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K semantic segmentation task (42.8% mIoU) and LaSOT visual tracking task (66.1% AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.