 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMI-DETR: A Strong Baseline for Moving Infrared Small Target Detection with Bio-Inspired Motion Integration
Mar 05, 2026Infrared small target detection (ISTD) is challenging because tiny, low-contrast targets are easily obscured by complex and dynamic backgrounds. Conventional multi-frame approaches typically learn motion implicitly through deep neural networks, often requiring additional motion supervision or explicit alignment modules. We propose Motion Integration DETR (MI-DETR), a bio-inspired dual-pathway detector that processes one infrared frame per time step while explicitly modeling motion. First, a retina-inspired cellular automaton (RCA) converts raw frame sequences into a motion map defined on the same pixel grid as the appearance image, enabling parvocellular-like appearance and magnocellular-like motion pathways to be supervised by a single set of bounding boxes without extra motion labels or alignment operations. Second, a Parvocellular-Magnocellular Interconnection (PMI) Block facilitates bidirectional feature interaction between the two pathways, providing a biologically motivated intermediate interconnection mechanism. Finally, a RT-DETR decoder operates on features from the two pathways to produce detection results. Surprisingly, our proposed simple yet effective approach yields strong performance on three commonly used ISTD benchmarks. MI-DETR achieves 70.3% mAP@50 and 72.7% F1 on IRDST-H (+26.35 mAP@50 over the best multi-frame baseline), 98.0% mAP@50 on DAUB-R, and 88.3% mAP@50 on ITSDT-15K, demonstrating the effectiveness of biologically inspired motion-appearance integration. Code is available at https://github.com/nliu-25/MI-DETR.
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
Jun 05, 2025In recent years, Multimodal Large Language Models (MLLMs) have been extensively utilized for multimodal reasoning tasks, including Graphical User Interface (GUI) automation. Unlike general offline multimodal tasks, GUI automation is executed in online interactive environments, necessitating step-by-step decision-making based on real-time status of the environment. This task has a lower tolerance for decision-making errors at each step, as any mistakes may cumulatively disrupt the process and potentially lead to irreversible outcomes like deletions or payments. To address these issues, we introduce a pre-operative critic mechanism that provides effective feedback prior to the actual execution, by reasoning about the potential outcome and correctness of actions. Specifically, we propose a Suggestion-aware Gradient Relative Policy Optimization (S-GRPO) strategy to construct our pre-operative critic model GUI-Critic-R1, incorporating a novel suggestion reward to enhance the reliability of the model's feedback. Furthermore, we develop a reasoning-bootstrapping based data collection pipeline to create a GUI-Critic-Train and a GUI-Critic-Test, filling existing gaps in GUI critic data. Static experiments on the GUI-Critic-Test across both mobile and web domains reveal that our GUI-Critic-R1 offers significant advantages in critic accuracy compared to current MLLMs. Dynamic evaluation on GUI automation benchmark further highlights the effectiveness and superiority of our model, as evidenced by improved success rates and operational efficiency.
HSTrack: Bootstrap End-to-End Multi-Camera 3D Multi-object Tracking with Hybrid Supervision
Nov 11, 2024



In camera-based 3D multi-object tracking (MOT), the prevailing methods follow the tracking-by-query-propagation paradigm, which employs track queries to manage the lifecycle of identity-consistent tracklets while object queries handle the detection of new-born tracklets. However, this intertwined paradigm leads the inter-temporal tracking task and the single-frame detection task utilize the same model parameters, complicating training optimization. Drawing inspiration from studies on the roles of attention components in transformer-based decoders, we identify that the dispersing effect of self-attention necessitates object queries to match with new-born tracklets. This matching strategy diverges from the detection pre-training phase, where object queries align with all ground-truth targets, resulting in insufficient supervision signals. To address these issues, we present HSTrack, a novel plug-and-play method designed to co-facilitate multi-task learning for detection and tracking. HSTrack constructs a parallel weight-share decoder devoid of self-attention layers, circumventing competition between different types of queries. Considering the characteristics of cross-attention layer and distinct query types, our parallel decoder adopt one-to-one and one-to-many label assignment strategies for track queries and object queries, respectively. Leveraging the shared architecture, HSTrack further improve trackers for spatio-temporal modeling and quality candidates generation. Extensive experiments demonstrate that HSTrack consistently delivers improvements when integrated with various query-based 3D MOT trackers. For example, HSTrack improves the state-of-the-art PF-Track method by $+2.3\%$ AMOTA and $+1.7\%$ mAP on the nuScenes dataset.
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Apr 18, 2024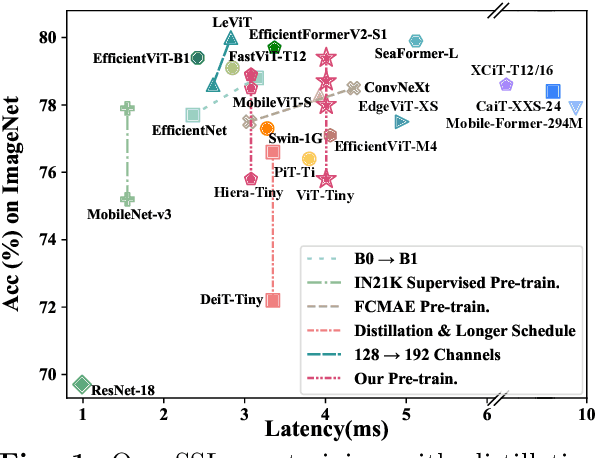
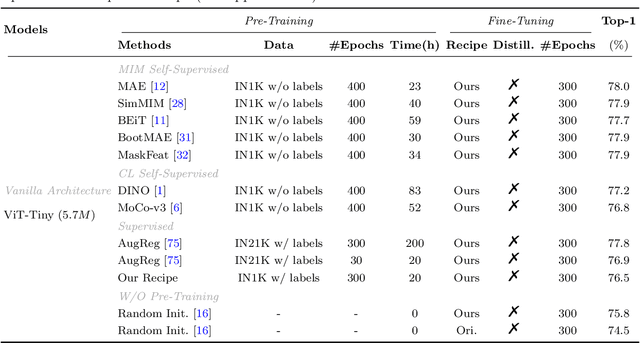

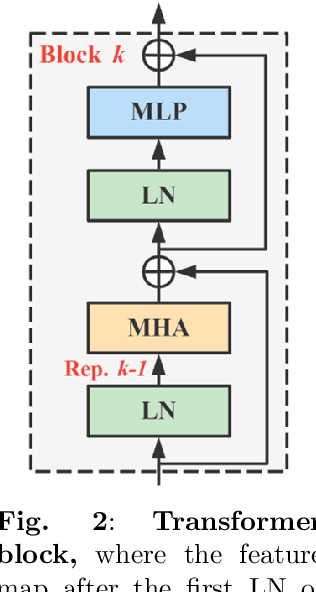
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) in computer vision has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the extremely simple ViTs' fine-tuning performance with a small-scale architecture can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology with sophisticated components introduced. By carefully adapting various typical MIM pre-training methods to this lightweight regime and comparing them with the contrastive learning (CL) pre-training on various downstream image classification and dense prediction tasks, we systematically observe different behaviors between MIM and CL with respect to the downstream fine-tuning data scales. Furthermore, we analyze the frozen features under linear probing evaluation and also the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory fine-tuning performance on data-insufficient downstream tasks. This finding is naturally a guide to choosing appropriate distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments on various vision tasks demonstrate the effectiveness of our observation-analysis-solution flow. In particular, our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design (5.7M/6.5M) can achieve 79.4%/78.9% top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K semantic segmentation task (42.8% mIoU) and LaSOT visual tracking task (66.1% AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
ZoomTrack: Target-aware Non-uniform Resizing for Efficient Visual Tracking
Oct 16, 2023



Recently, the transformer has enabled the speed-oriented trackers to approach state-of-the-art (SOTA) performance with high-speed thanks to the smaller input size or the lighter feature extraction backbone, though they still substantially lag behind their corresponding performance-oriented versions. In this paper, we demonstrate that it is possible to narrow or even close this gap while achieving high tracking speed based on the smaller input size. To this end, we non-uniformly resize the cropped image to have a smaller input size while the resolution of the area where the target is more likely to appear is higher and vice versa. This enables us to solve the dilemma of attending to a larger visual field while retaining more raw information for the target despite a smaller input size. Our formulation for the non-uniform resizing can be efficiently solved through quadratic programming (QP) and naturally integrated into most of the crop-based local trackers. Comprehensive experiments on five challenging datasets based on two kinds of transformer trackers, \ie, OSTrack and TransT, demonstrate consistent improvements over them. In particular, applying our method to the speed-oriented version of OSTrack even outperforms its performance-oriented counterpart by 0.6% AUC on TNL2K, while running 50% faster and saving over 55% MACs. Codes and models are available at https://github.com/Kou-99/ZoomTrack.
Recursive Least-Squares Estimator-Aided Online Learning for Visual Tracking
Dec 28, 2021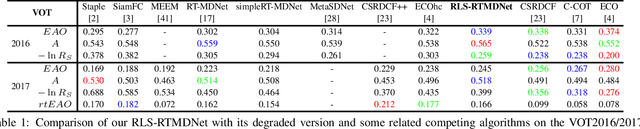

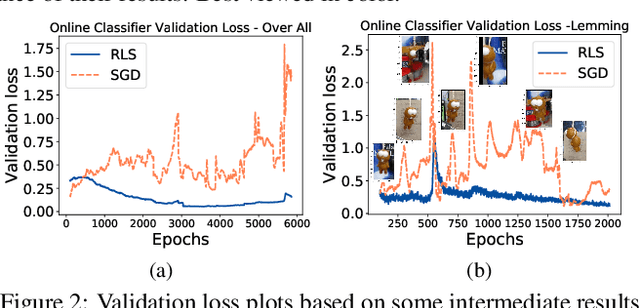
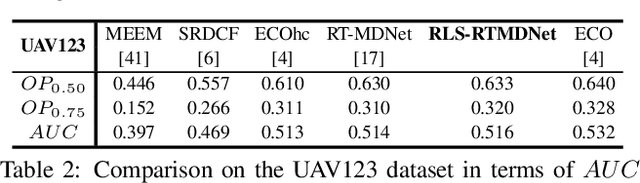
Tracking visual objects from a single initial exemplar in the testing phase has been broadly cast as a one-/few-shot problem, i.e., one-shot learning for initial adaptation and few-shot learning for online adaptation. The recent few-shot online adaptation methods incorporate the prior knowledge from large amounts of annotated training data via complex meta-learning optimization in the offline phase. This helps the online deep trackers to achieve fast adaptation and reduce overfitting risk in tracking. In this paper, we propose a simple yet effective recursive least-squares estimator-aided online learning approach for few-shot online adaptation without requiring offline training. It allows an in-built memory retention mechanism for the model to remember the knowledge about the object seen before, and thus the seen data can be safely removed from training. This also bears certain similarities to the emerging continual learning field in preventing catastrophic forgetting. This mechanism enables us to unveil the power of modern online deep trackers without incurring too much extra computational cost. We evaluate our approach based on two networks in the online learning families for tracking, i.e., multi-layer perceptrons in RT-MDNet and convolutional neural networks in DiMP. The consistent improvements on several challenging tracking benchmarks demonstrate its effectiveness and efficiency.
Max-Affine Spline Insights Into Deep Network Pruning
Jan 07, 2021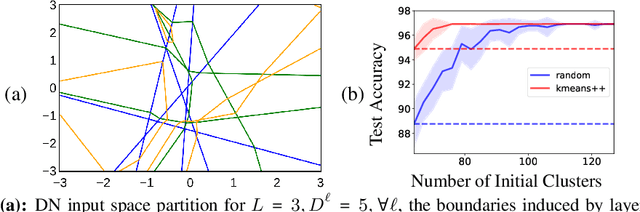
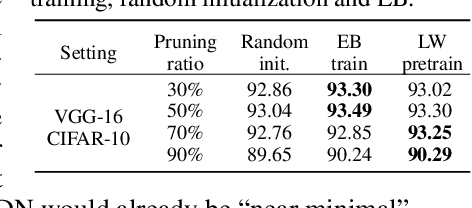

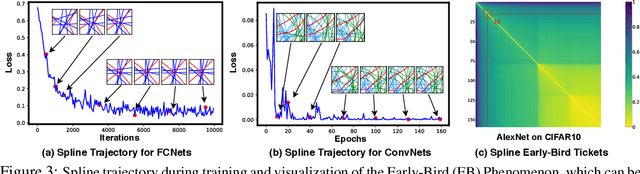
In this paper, we study the importance of pruning in Deep Networks (DNs) and motivate it based on the current absence of data aware weight initialization. Current DN initializations, focusing primarily at maintaining first order statistics of the feature maps through depth, force practitioners to overparametrize a model in order to reach high performances. This overparametrization can then be pruned a posteriori, leading to a phenomenon known as "winning tickets". However, the pruning literature still relies on empirical investigations, lacking a theoretical understanding of (1) how pruning affects the decision boundary, (2) how to interpret pruning, (3) how to design principled pruning techniques, and (4) how to theoretically study pruning. To tackle those questions, we propose to employ recent advances in the theoretical analysis of Continuous Piecewise Affine (CPA) DNs. From this viewpoint, we can study the DNs' input space partitioning and detect the early-bird (EB) phenomenon, guide practitioners by identifying when to stop the first training step, provide interpretability into current pruning techniques, and develop a principled pruning criteria towards efficient DN training. Finally, we conduct extensive experiments to show the effectiveness of the proposed spline pruning criteria in terms of both layerwise and global pruning over state-of-the-art pruning methods.