 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMax-Affine Spline Insights Into Deep Network Pruning
Paper and Code
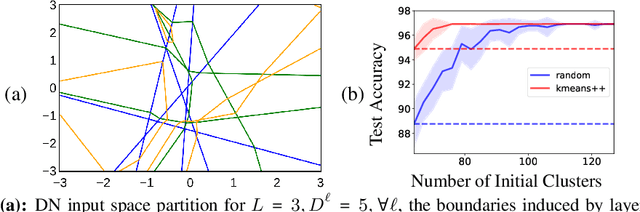
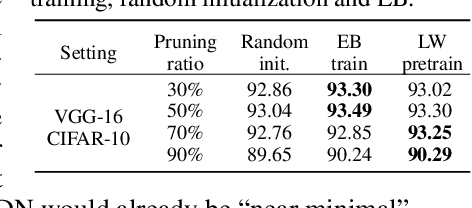

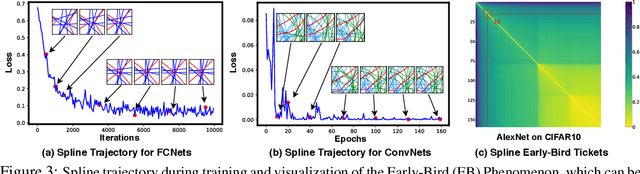
In this paper, we study the importance of pruning in Deep Networks (DNs) and motivate it based on the current absence of data aware weight initialization. Current DN initializations, focusing primarily at maintaining first order statistics of the feature maps through depth, force practitioners to overparametrize a model in order to reach high performances. This overparametrization can then be pruned a posteriori, leading to a phenomenon known as "winning tickets". However, the pruning literature still relies on empirical investigations, lacking a theoretical understanding of (1) how pruning affects the decision boundary, (2) how to interpret pruning, (3) how to design principled pruning techniques, and (4) how to theoretically study pruning. To tackle those questions, we propose to employ recent advances in the theoretical analysis of Continuous Piecewise Affine (CPA) DNs. From this viewpoint, we can study the DNs' input space partitioning and detect the early-bird (EB) phenomenon, guide practitioners by identifying when to stop the first training step, provide interpretability into current pruning techniques, and develop a principled pruning criteria towards efficient DN training. Finally, we conduct extensive experiments to show the effectiveness of the proposed spline pruning criteria in terms of both layerwise and global pruning over state-of-the-art pruning methods.