 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEBT: Drawing Early-Bird Tickets in Graph Convolutional Network Training
Mar 01, 2021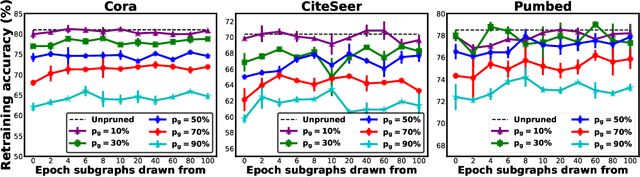

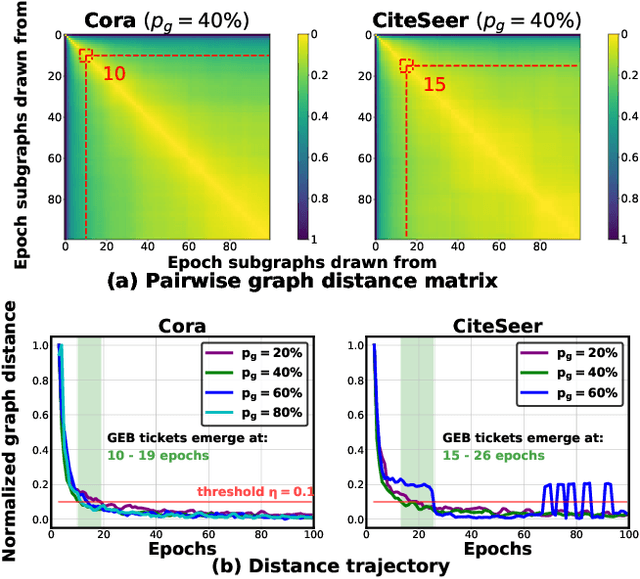
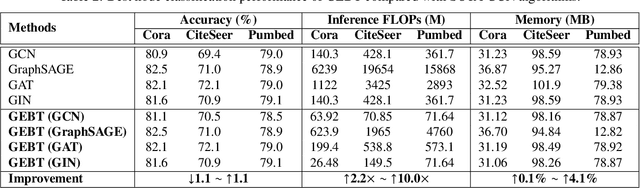
Graph Convolutional Networks (GCNs) have emerged as the state-of-the-art deep learning model for representation learning on graphs. However, it remains notoriously challenging to train and inference GCNs over large graph datasets, limiting their application to large real-world graphs and hindering the exploration of deeper and more sophisticated GCN graphs. This is because as the graph size grows, the sheer number of node features and the large adjacency matrix can easily explode the required memory and data movements. To tackle the aforementioned challenge, we explore the possibility of drawing lottery tickets when sparsifying GCN graphs, i.e., subgraphs that largely shrink the adjacency matrix yet are capable of achieving accuracy comparable to or even better than their corresponding full graphs. Specifically, we for the first time discover the existence of graph early-bird (GEB) tickets that emerge at the very early stage when sparsifying GCN graphs, and propose a simple yet effective detector to automatically identify the emergence of such GEB tickets. Furthermore, we develop a generic efficient GCN training framework dubbed GEBT that can significantly boost the efficiency of GCN training by (1) drawing joint early-bird tickets between the GCN graphs and models and (2) enabling simultaneously sparsifying both GCN graphs and models, paving the way for training and inferencing large GCN graphs to handle real-world graph datasets. Experiments on various GCN models and datasets consistently validate our GEB finding and the effectiveness of our GEBT, e.g., our GEBT achieves up to 80.2% ~ 85.6% and 84.6% ~ 87.5% savings of GCN training and inference costs while leading to a comparable or even better accuracy as compared to state-of-the-art methods. Code available at https://github.com/RICE-EIC/GEBT
Max-Affine Spline Insights Into Deep Network Pruning
Jan 07, 2021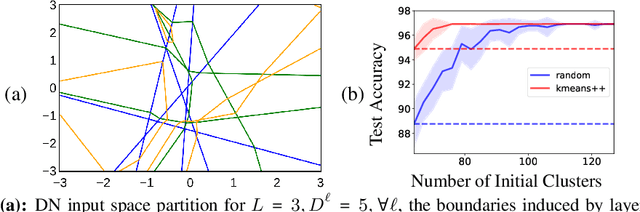
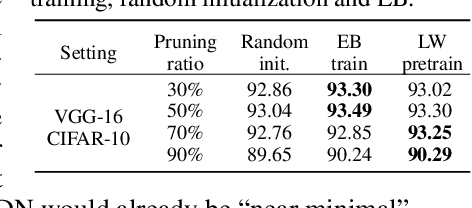

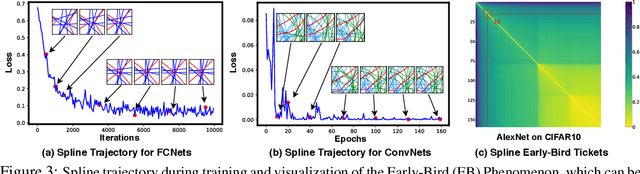
In this paper, we study the importance of pruning in Deep Networks (DNs) and motivate it based on the current absence of data aware weight initialization. Current DN initializations, focusing primarily at maintaining first order statistics of the feature maps through depth, force practitioners to overparametrize a model in order to reach high performances. This overparametrization can then be pruned a posteriori, leading to a phenomenon known as "winning tickets". However, the pruning literature still relies on empirical investigations, lacking a theoretical understanding of (1) how pruning affects the decision boundary, (2) how to interpret pruning, (3) how to design principled pruning techniques, and (4) how to theoretically study pruning. To tackle those questions, we propose to employ recent advances in the theoretical analysis of Continuous Piecewise Affine (CPA) DNs. From this viewpoint, we can study the DNs' input space partitioning and detect the early-bird (EB) phenomenon, guide practitioners by identifying when to stop the first training step, provide interpretability into current pruning techniques, and develop a principled pruning criteria towards efficient DN training. Finally, we conduct extensive experiments to show the effectiveness of the proposed spline pruning criteria in terms of both layerwise and global pruning over state-of-the-art pruning methods.