 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Apr 18, 2024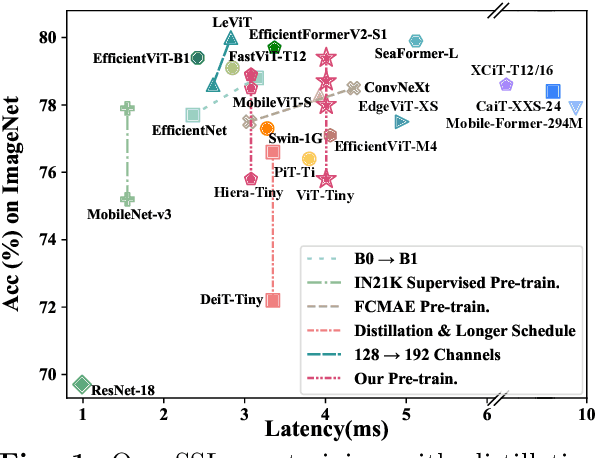
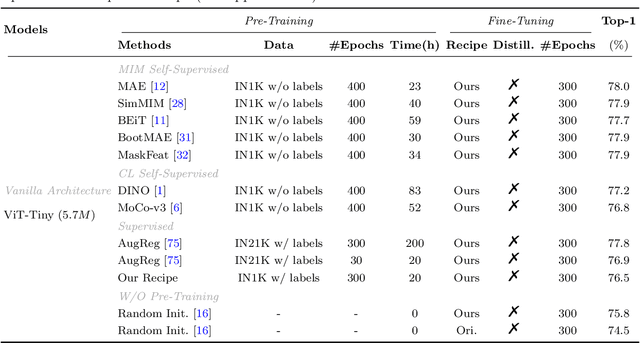

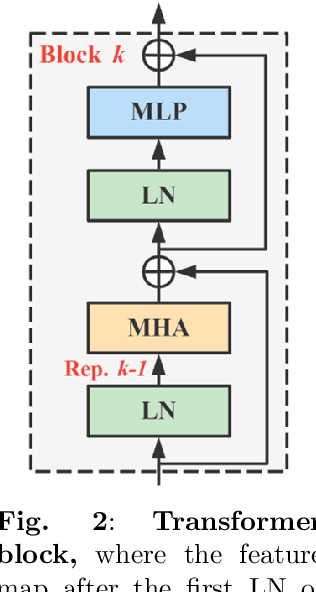
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) in computer vision has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the extremely simple ViTs' fine-tuning performance with a small-scale architecture can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology with sophisticated components introduced. By carefully adapting various typical MIM pre-training methods to this lightweight regime and comparing them with the contrastive learning (CL) pre-training on various downstream image classification and dense prediction tasks, we systematically observe different behaviors between MIM and CL with respect to the downstream fine-tuning data scales. Furthermore, we analyze the frozen features under linear probing evaluation and also the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory fine-tuning performance on data-insufficient downstream tasks. This finding is naturally a guide to choosing appropriate distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments on various vision tasks demonstrate the effectiveness of our observation-analysis-solution flow. In particular, our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design (5.7M/6.5M) can achieve 79.4%/78.9% top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K semantic segmentation task (42.8% mIoU) and LaSOT visual tracking task (66.1% AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
DSPNet: Towards Slimmable Pretrained Networks based on Discriminative Self-supervised Learning
Jul 13, 2022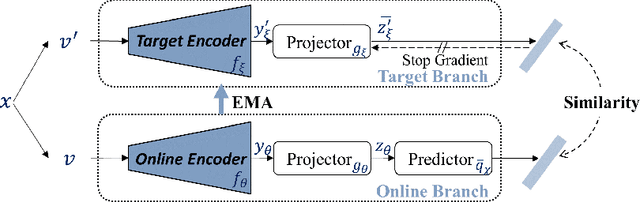
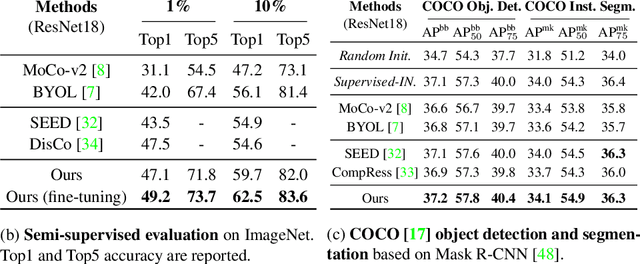
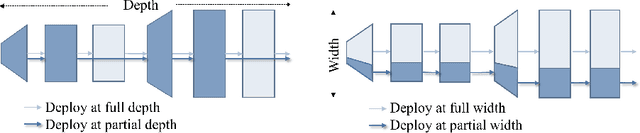
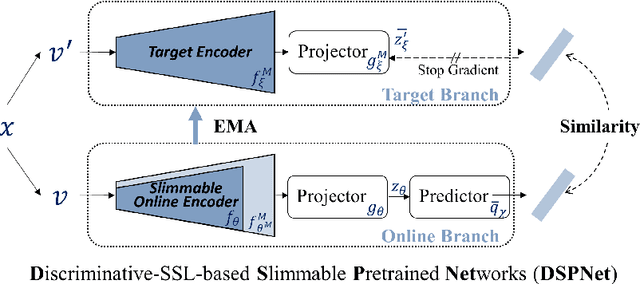
Self-supervised learning (SSL) has achieved promising downstream performance. However, when facing various resource budgets in real-world applications, it costs a huge computation burden to pretrain multiple networks of various sizes one by one. In this paper, we propose Discriminative-SSL-based Slimmable Pretrained Networks (DSPNet), which can be trained at once and then slimmed to multiple sub-networks of various sizes, each of which faithfully learns good representation and can serve as good initialization for downstream tasks with various resource budgets. Specifically, we extend the idea of slimmable networks to a discriminative SSL paradigm, by integrating SSL and knowledge distillation gracefully. We show comparable or improved performance of DSPNet on ImageNet to the networks individually pretrained one by one under the linear evaluation and semi-supervised evaluation protocols, while reducing large training cost. The pretrained models also generalize well on downstream detection and segmentation tasks. Code will be made public.
Narrowing the Gap: Improved Detector Training with Noisy Location Annotations
Jun 12, 2022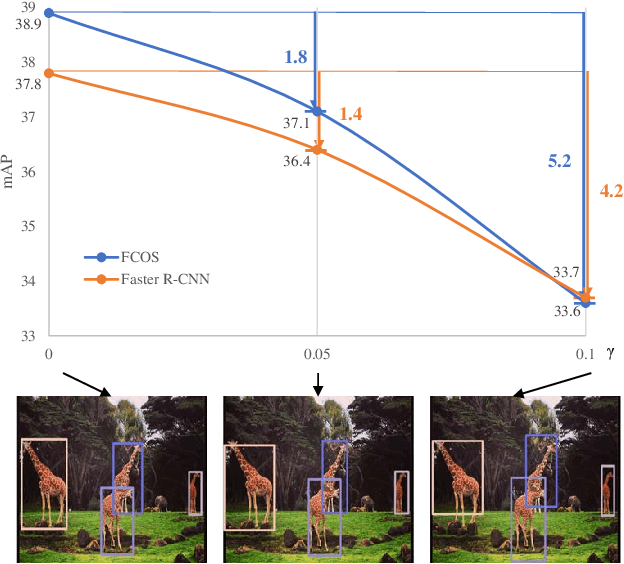
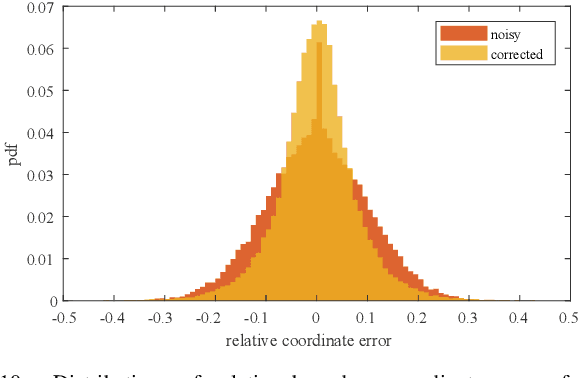

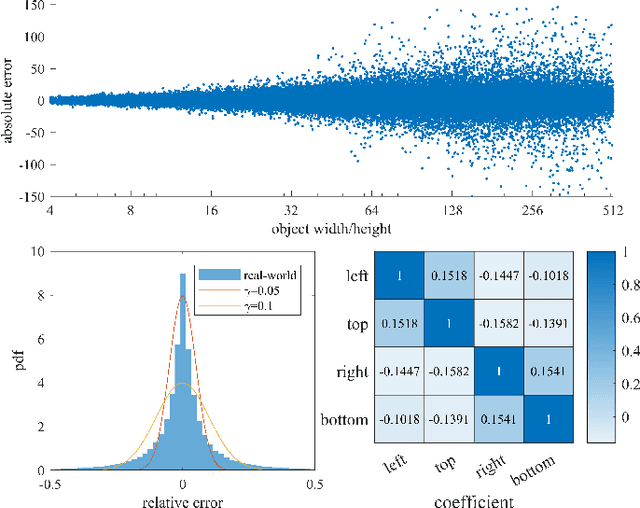
Deep learning methods require massive of annotated data for optimizing parameters. For example, datasets attached with accurate bounding box annotations are essential for modern object detection tasks. However, labeling with such pixel-wise accuracy is laborious and time-consuming, and elaborate labeling procedures are indispensable for reducing man-made noise, involving annotation review and acceptance testing. In this paper, we focus on the impact of noisy location annotations on the performance of object detection approaches and aim to, on the user side, reduce the adverse effect of the noise. First, noticeable performance degradation is experimentally observed for both one-stage and two-stage detectors when noise is introduced to the bounding box annotations. For instance, our synthesized noise results in performance decrease from 38.9% AP to 33.6% AP for FCOS detector on COCO test split, and 37.8%AP to 33.7%AP for Faster R-CNN. Second, a self-correction technique based on a Bayesian filter for prediction ensemble is proposed to better exploit the noisy location annotations following a Teacher-Student learning paradigm. Experiments for both synthesized and real-world scenarios consistently demonstrate the effectiveness of our approach, e.g., our method increases the degraded performance of the FCOS detector from 33.6% AP to 35.6% AP on COCO.
A Closer Look at Self-supervised Lightweight Vision Transformers
May 28, 2022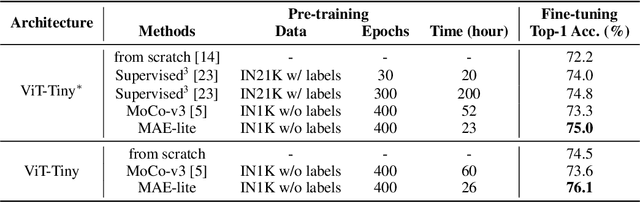
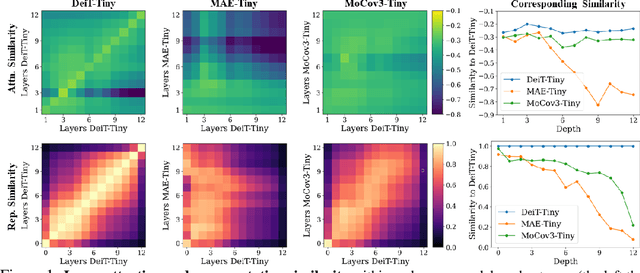
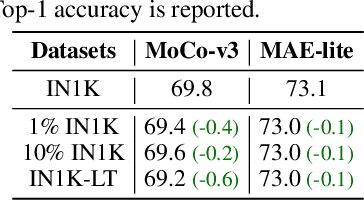
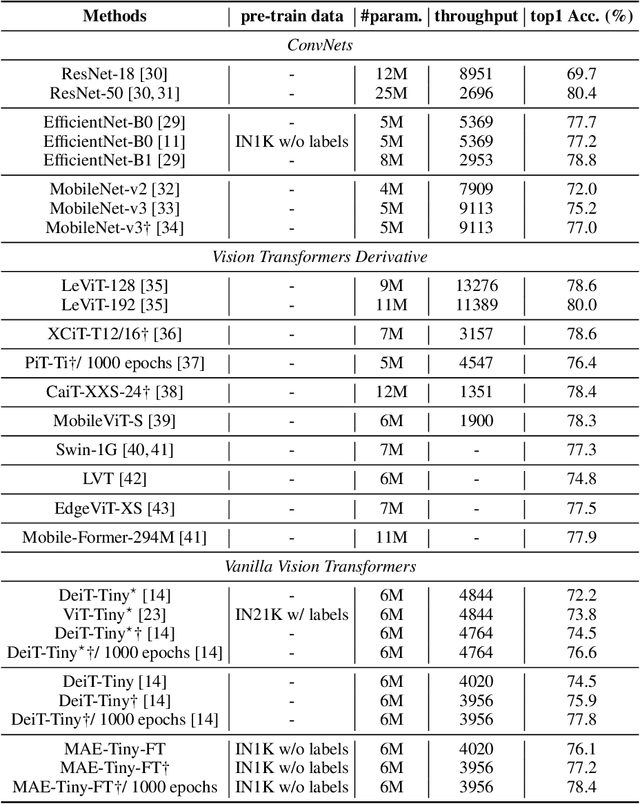
Self-supervised learning on large-scale Vision Transformers (ViTs) as pre-training methods has achieved promising downstream performance. Yet, how such pre-training paradigms promote lightweight ViTs' performance is considerably less studied. In this work, we mainly produce recipes for pre-training high-performance lightweight ViTs using masked-image-modeling-based MAE, namely MAE-lite, which achieves 78.4% top-1 accuracy on ImageNet with ViT-Tiny (5.7M). Furthermore, we develop and benchmark other fully-supervised and self-supervised pre-training counterparts, e.g., contrastive-learning-based MoCo-v3, on both ImageNet and other classification tasks. We analyze and clearly show the effect of such pre-training, and reveal that properly-learned lower layers of the pre-trained models matter more than higher ones in data-sufficient downstream tasks. Finally, by further comparing with the pre-trained representations of the up-scaled models, a distillation strategy during pre-training is developed to improve the pre-trained representations as well, leading to further downstream performance improvement. The code and models will be made publicly available.
Open-Vocabulary One-Stage Detection with Hierarchical Visual-Language Knowledge Distillation
Mar 20, 2022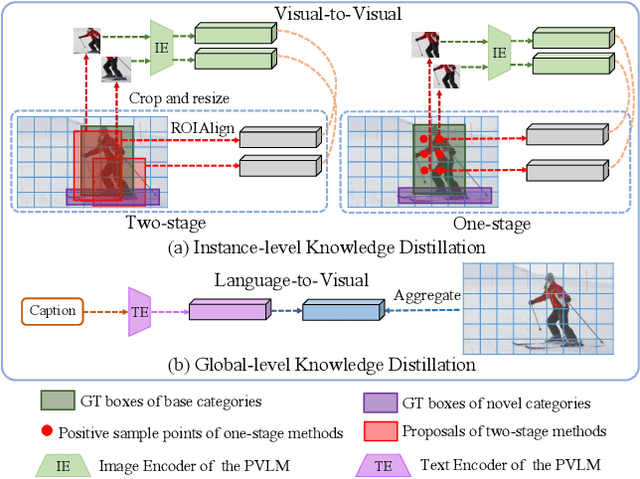
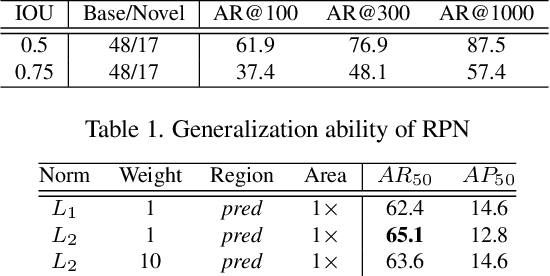
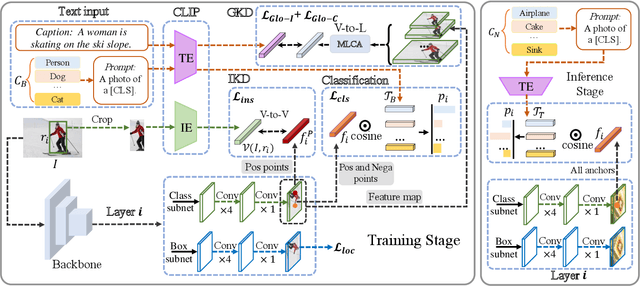
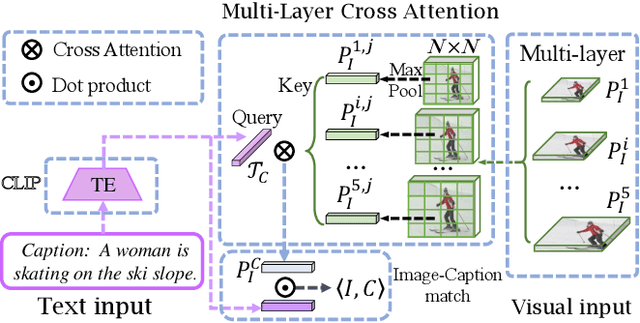
Open-vocabulary object detection aims to detect novel object categories beyond the training set. The advanced open-vocabulary two-stage detectors employ instance-level visual-to-visual knowledge distillation to align the visual space of the detector with the semantic space of the Pre-trained Visual-Language Model (PVLM). However, in the more efficient one-stage detector, the absence of class-agnostic object proposals hinders the knowledge distillation on unseen objects, leading to severe performance degradation. In this paper, we propose a hierarchical visual-language knowledge distillation method, i.e., HierKD, for open-vocabulary one-stage detection. Specifically, a global-level knowledge distillation is explored to transfer the knowledge of unseen categories from the PVLM to the detector. Moreover, we combine the proposed global-level knowledge distillation and the common instance-level knowledge distillation to learn the knowledge of seen and unseen categories simultaneously. Extensive experiments on MS-COCO show that our method significantly surpasses the previous best one-stage detector with 11.9\% and 6.7\% $AP_{50}$ gains under the zero-shot detection and generalized zero-shot detection settings, and reduces the $AP_{50}$ performance gap from 14\% to 7.3\% compared to the best two-stage detector.
A Simple and Strong Baseline for Universal Targeted Attacks on Siamese Visual Tracking
May 06, 2021

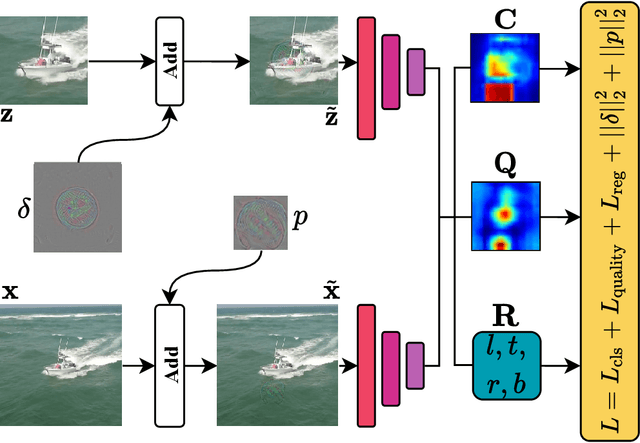

Siamese trackers are shown to be vulnerable to adversarial attacks recently. However, the existing attack methods craft the perturbations for each video independently, which comes at a non-negligible computational cost. In this paper, we show the existence of universal perturbations that can enable the targeted attack, e.g., forcing a tracker to follow the ground-truth trajectory with specified offsets, to be video-agnostic and free from inference in a network. Specifically, we attack a tracker by adding a universal imperceptible perturbation to the template image and adding a fake target, i.e., a small universal adversarial patch, into the search images adhering to the predefined trajectory, so that the tracker outputs the location and size of the fake target instead of the real target. Our approach allows perturbing a novel video to come at no additional cost except the mere addition operations -- and not require gradient optimization or network inference. Experimental results on several datasets demonstrate that our approach can effectively fool the Siamese trackers in a targeted attack manner. We show that the proposed perturbations are not only universal across videos, but also generalize well across different trackers. Such perturbations are therefore doubly universal, both with respect to the data and the network architectures. We will make our code publicly available.
PDNet: Towards Better One-stage Object Detection with Prediction Decoupling
Apr 28, 2021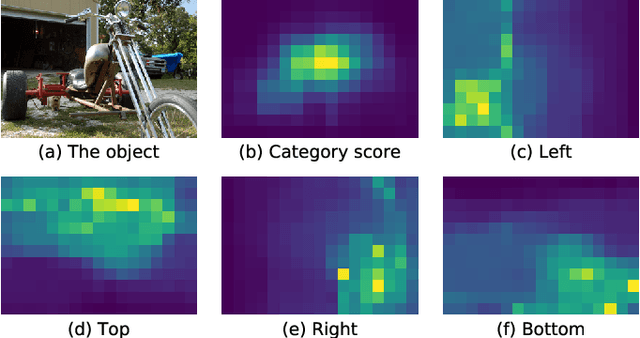
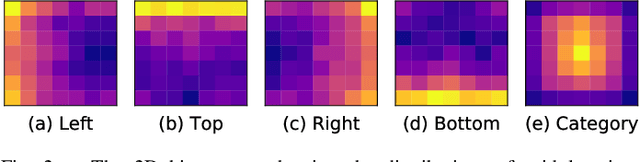
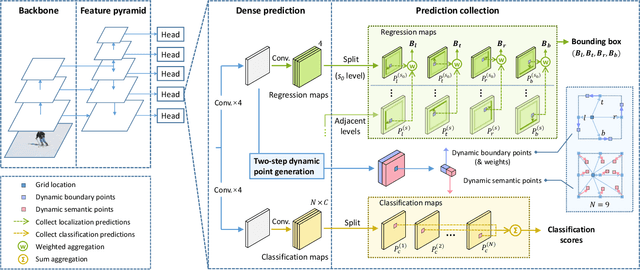
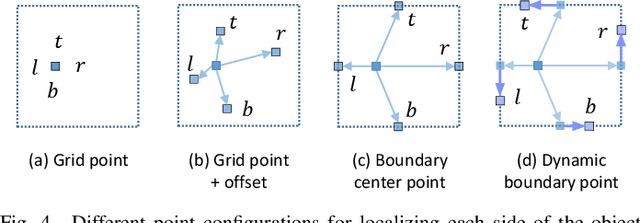
Recent one-stage object detectors follow a per-pixel prediction approach that predicts both the object category scores and boundary positions from every single grid location. However, the most suitable positions for inferring different targets, i.e., the object category and boundaries, are generally different. Predicting all these targets from the same grid location thus may lead to sub-optimal results. In this paper, we analyze the suitable inference positions for object category and boundaries, and propose a prediction-target-decoupled detector named PDNet to establish a more flexible detection paradigm. Our PDNet with the prediction decoupling mechanism encodes different targets separately in different locations. A learnable prediction collection module is devised with two sets of dynamic points, i.e., dynamic boundary points and semantic points, to collect and aggregate the predictions from the favorable regions for localization and classification. We adopt a two-step strategy to learn these dynamic point positions, where the prior positions are estimated for different targets first, and the network further predicts residual offsets to the positions with better perceptions of the object properties. Extensive experiments on the MS COCO benchmark demonstrate the effectiveness and efficiency of our method. With a single ResNeXt-64x4d-101 as the backbone, our detector achieves 48.7 AP with single-scale testing, which outperforms the state-of-the-art methods by an appreciable margin under the same experimental settings. Moreover, our detector is highly efficient as a one-stage framework. Our code will be public.
RDSNet: A New Deep Architecture for Reciprocal Object Detection and Instance Segmentation
Dec 11, 2019
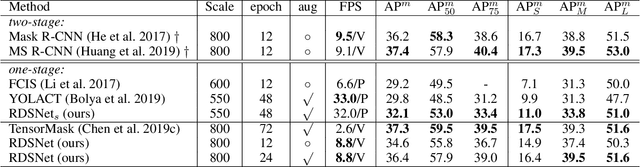
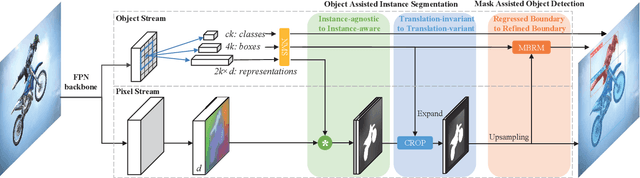
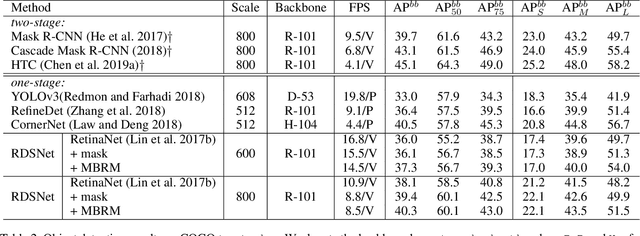
Object detection and instance segmentation are two fundamental computer vision tasks. They are closely correlated but their relations have not yet been fully explored in most previous work. This paper presents RDSNet, a novel deep architecture for reciprocal object detection and instance segmentation. To reciprocate these two tasks, we design a two-stream structure to learn features on both the object level (i.e., bounding boxes) and the pixel level (i.e., instance masks) jointly. Within this structure, information from the two streams is fused alternately, namely information on the object level introduces the awareness of instance and translation variance to the pixel level, and information on the pixel level refines the localization accuracy of objects on the object level in return. Specifically, a correlation module and a cropping module are proposed to yield instance masks, as well as a mask based boundary refinement module for more accurate bounding boxes. Extensive experimental analyses and comparisons on the COCO dataset demonstrate the effectiveness and efficiency of RDSNet. The source code is available at https://github.com/wangsr126/RDSNet.