 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Self-supervised Lightweight Vision Transformers
Paper and Code
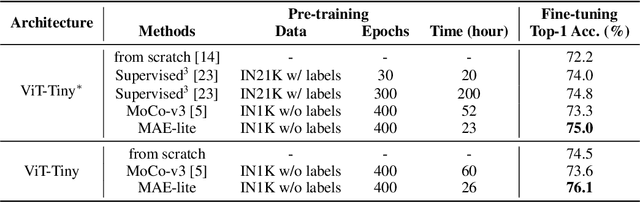
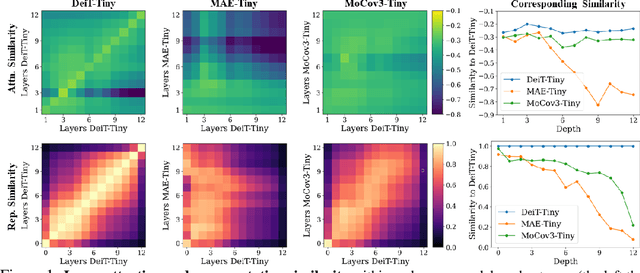
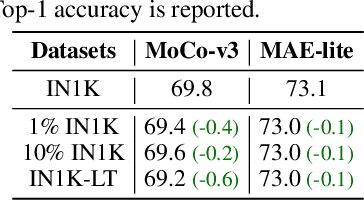
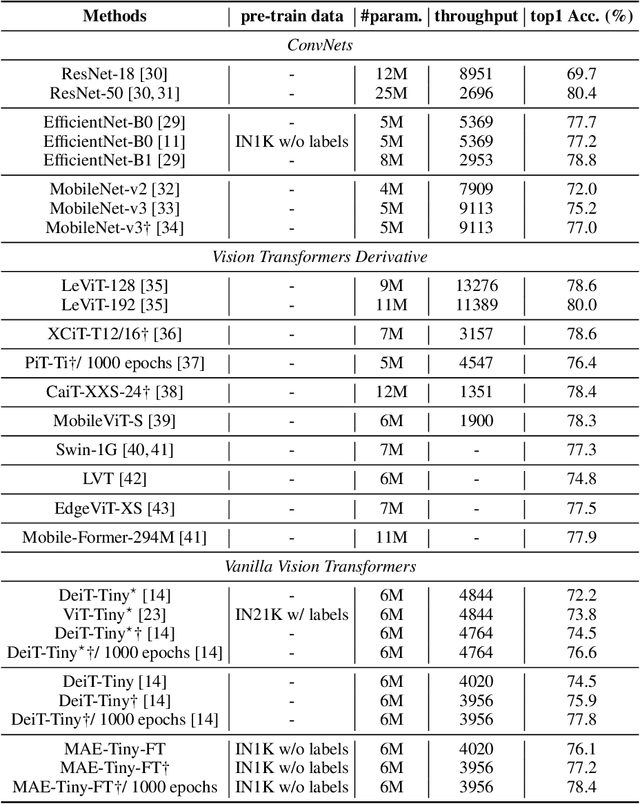
Self-supervised learning on large-scale Vision Transformers (ViTs) as pre-training methods has achieved promising downstream performance. Yet, how such pre-training paradigms promote lightweight ViTs' performance is considerably less studied. In this work, we mainly produce recipes for pre-training high-performance lightweight ViTs using masked-image-modeling-based MAE, namely MAE-lite, which achieves 78.4% top-1 accuracy on ImageNet with ViT-Tiny (5.7M). Furthermore, we develop and benchmark other fully-supervised and self-supervised pre-training counterparts, e.g., contrastive-learning-based MoCo-v3, on both ImageNet and other classification tasks. We analyze and clearly show the effect of such pre-training, and reveal that properly-learned lower layers of the pre-trained models matter more than higher ones in data-sufficient downstream tasks. Finally, by further comparing with the pre-trained representations of the up-scaled models, a distillation strategy during pre-training is developed to improve the pre-trained representations as well, leading to further downstream performance improvement. The code and models will be made publicly available.