 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time and Accurate Object Detection in Compressed Video by Long Short-term Feature Aggregation
Mar 25, 2021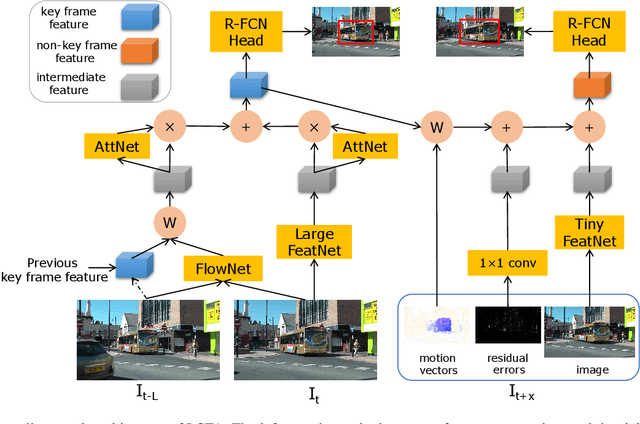
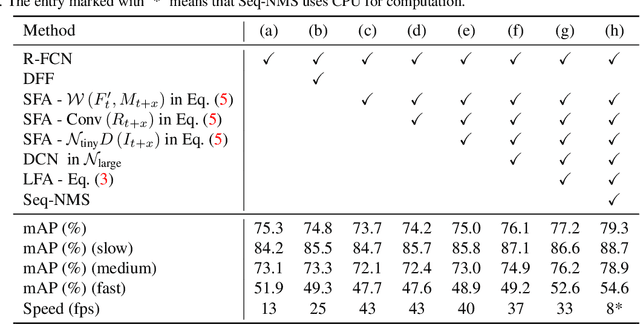
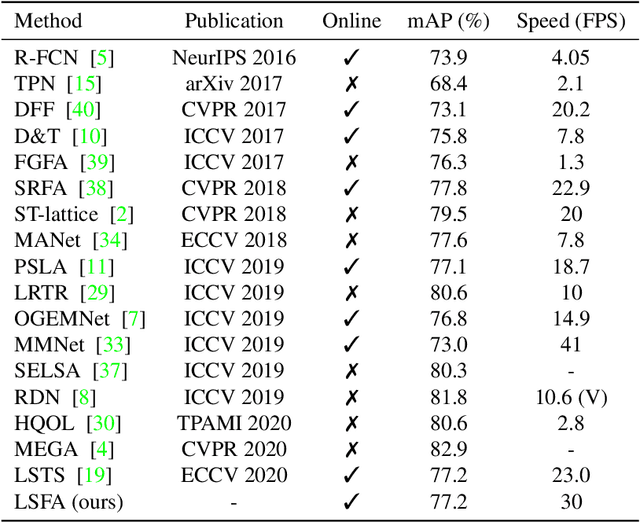

Video object detection is a fundamental problem in computer vision and has a wide spectrum of applications. Based on deep networks, video object detection is actively studied for pushing the limits of detection speed and accuracy. To reduce the computation cost, we sparsely sample key frames in video and treat the rest frames are non-key frames; a large and deep network is used to extract features for key frames and a tiny network is used for non-key frames. To enhance the features of non-key frames, we propose a novel short-term feature aggregation method to propagate the rich information in key frame features to non-key frame features in a fast way. The fast feature aggregation is enabled by the freely available motion cues in compressed videos. Further, key frame features are also aggregated based on optical flow. The propagated deep features are then integrated with the directly extracted features for object detection. The feature extraction and feature integration parameters are optimized in an end-to-end manner. The proposed video object detection network is evaluated on the large-scale ImageNet VID benchmark and achieves 77.2\% mAP, which is on-par with state-of-the-art accuracy, at the speed of 30 FPS using a Titan X GPU. The source codes are available at \url{https://github.com/hustvl/LSFA}.
RDSNet: A New Deep Architecture for Reciprocal Object Detection and Instance Segmentation
Dec 11, 2019
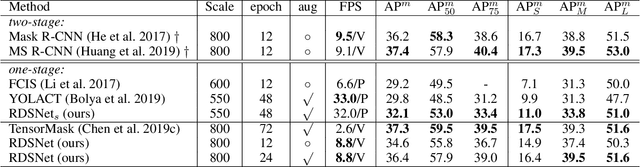
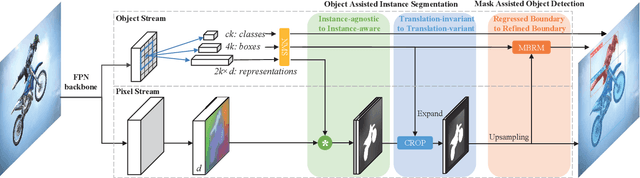
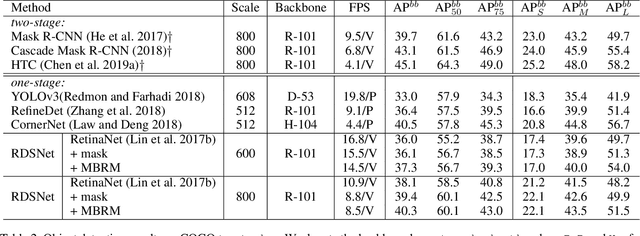
Object detection and instance segmentation are two fundamental computer vision tasks. They are closely correlated but their relations have not yet been fully explored in most previous work. This paper presents RDSNet, a novel deep architecture for reciprocal object detection and instance segmentation. To reciprocate these two tasks, we design a two-stream structure to learn features on both the object level (i.e., bounding boxes) and the pixel level (i.e., instance masks) jointly. Within this structure, information from the two streams is fused alternately, namely information on the object level introduces the awareness of instance and translation variance to the pixel level, and information on the pixel level refines the localization accuracy of objects on the object level in return. Specifically, a correlation module and a cropping module are proposed to yield instance masks, as well as a mask based boundary refinement module for more accurate bounding boxes. Extensive experimental analyses and comparisons on the COCO dataset demonstrate the effectiveness and efficiency of RDSNet. The source code is available at https://github.com/wangsr126/RDSNet.
Proposal, Tracking and Segmentation (PTS): A Cascaded Network for Video Object Segmentation
Jul 04, 2019

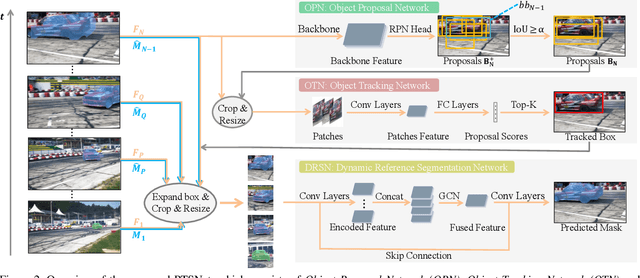

Video object segmentation (VOS) aims at pixel-level object tracking given only the annotations in the first frame. Due to the large visual variations of objects in video and the lack of training samples, it remains a difficult task despite the upsurging development of deep learning. Toward solving the VOS problem, we bring in several new insights by the proposed unified framework consisting of object proposal, tracking and segmentation components. The object proposal network transfers objectness information as generic knowledge into VOS; the tracking network identifies the target object from the proposals; and the segmentation network is performed based on the tracking results with a novel dynamic-reference based model adaptation scheme. Extensive experiments have been conducted on the DAVIS'17 dataset and the YouTube-VOS dataset, our method achieves the state-of-the-art performance on several video object segmentation benchmarks. We make the code publicly available at https://github.com/sydney0zq/PTSNet.
Mask Scoring R-CNN
Mar 01, 2019
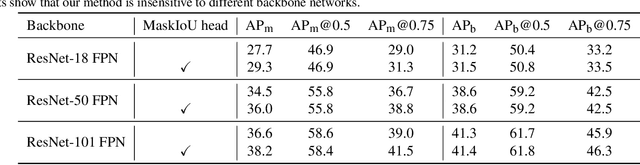
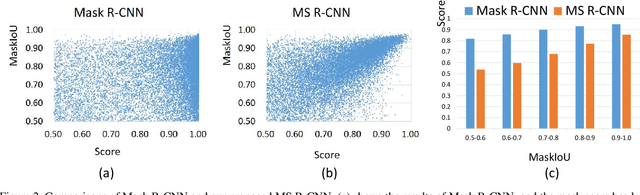

Letting a deep network be aware of the quality of its own predictions is an interesting yet important problem. In the task of instance segmentation, the confidence of instance classification is used as mask quality score in most instance segmentation frameworks. However, the mask quality, quantified as the IoU between the instance mask and its ground truth, is usually not well correlated with classification score. In this paper, we study this problem and propose Mask Scoring R-CNN which contains a network block to learn the quality of the predicted instance masks. The proposed network block takes the instance feature and the corresponding predicted mask together to regress the mask IoU. The mask scoring strategy calibrates the misalignment between mask quality and mask score, and improves instance segmentation performance by prioritizing more accurate mask predictions during COCO AP evaluation. By extensive evaluations on the COCO dataset, Mask Scoring R-CNN brings consistent and noticeable gain with different models, and outperforms the state-of-the-art Mask R-CNN. We hope our simple and effective approach will provide a new direction for improving instance segmentation. The source code of our method is available at \url{https://github.com/zjhuang22/maskscoring_rcnn}.