 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time and Accurate Object Detection in Compressed Video by Long Short-term Feature Aggregation
Mar 25, 2021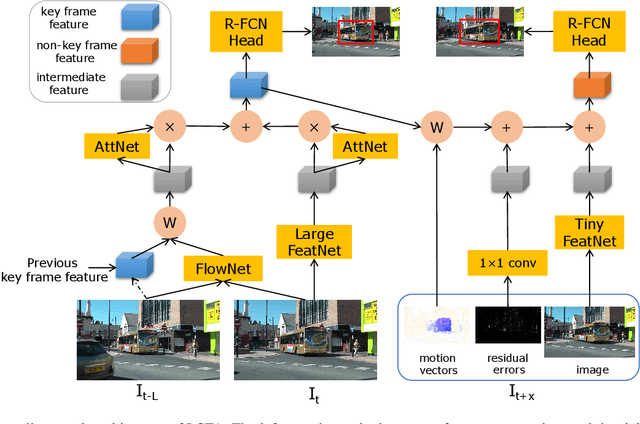
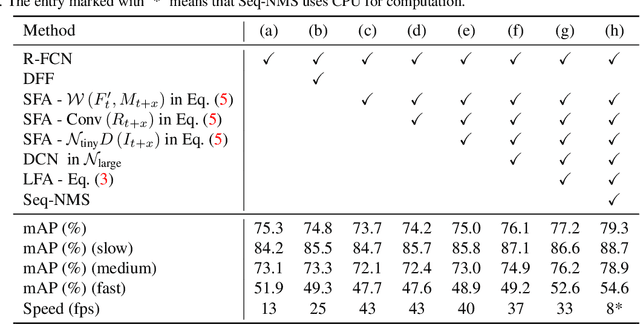
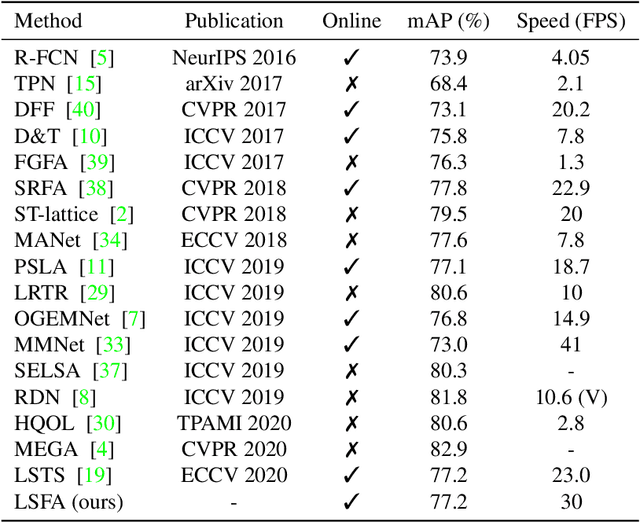

Video object detection is a fundamental problem in computer vision and has a wide spectrum of applications. Based on deep networks, video object detection is actively studied for pushing the limits of detection speed and accuracy. To reduce the computation cost, we sparsely sample key frames in video and treat the rest frames are non-key frames; a large and deep network is used to extract features for key frames and a tiny network is used for non-key frames. To enhance the features of non-key frames, we propose a novel short-term feature aggregation method to propagate the rich information in key frame features to non-key frame features in a fast way. The fast feature aggregation is enabled by the freely available motion cues in compressed videos. Further, key frame features are also aggregated based on optical flow. The propagated deep features are then integrated with the directly extracted features for object detection. The feature extraction and feature integration parameters are optimized in an end-to-end manner. The proposed video object detection network is evaluated on the large-scale ImageNet VID benchmark and achieves 77.2\% mAP, which is on-par with state-of-the-art accuracy, at the speed of 30 FPS using a Titan X GPU. The source codes are available at \url{https://github.com/hustvl/LSFA}.
EmbedMask: Embedding Coupling for One-stage Instance Segmentation
Dec 05, 2019
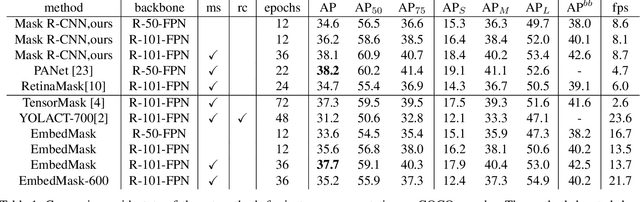
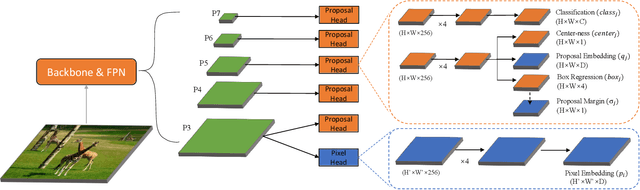
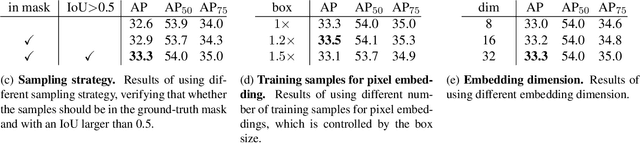
Current instance segmentation methods can be categorized into segmentation-based methods that segment first then do clustering, and proposal-based methods that detect first then predict masks for each instance proposal using repooling. In this work, we propose a one-stage method, named EmbedMask, that unifies both methods by taking advantages of them. Like proposal-based methods, EmbedMask builds on top of detection models making it strong in detection capability. Meanwhile, EmbedMask applies extra embedding modules to generate embeddings for pixels and proposals, where pixel embeddings are guided by proposal embeddings if they belong to the same instance. Through this embedding coupling process, pixels are assigned to the mask of the proposal if their embeddings are similar. The pixel-level clustering enables EmbedMask to generate high-resolution masks without missing details from repooling, and the existence of proposal embedding simplifies and strengthens the clustering procedure to achieve high speed with higher performance than segmentation-based methods. Without any bells and whistles, EmbedMask achieves comparable performance as Mask R-CNN, which is the representative two-stage method, and can produce more detailed masks at a higher speed. Code is available at github.com/yinghdb/EmbedMask.
Mask Scoring R-CNN
Mar 01, 2019
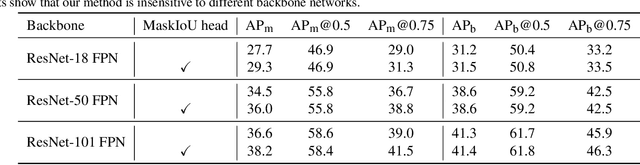
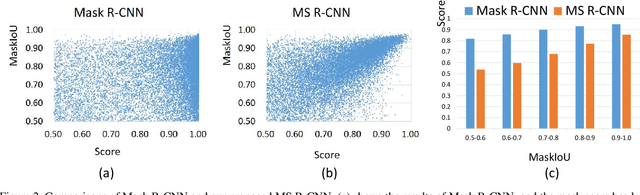

Letting a deep network be aware of the quality of its own predictions is an interesting yet important problem. In the task of instance segmentation, the confidence of instance classification is used as mask quality score in most instance segmentation frameworks. However, the mask quality, quantified as the IoU between the instance mask and its ground truth, is usually not well correlated with classification score. In this paper, we study this problem and propose Mask Scoring R-CNN which contains a network block to learn the quality of the predicted instance masks. The proposed network block takes the instance feature and the corresponding predicted mask together to regress the mask IoU. The mask scoring strategy calibrates the misalignment between mask quality and mask score, and improves instance segmentation performance by prioritizing more accurate mask predictions during COCO AP evaluation. By extensive evaluations on the COCO dataset, Mask Scoring R-CNN brings consistent and noticeable gain with different models, and outperforms the state-of-the-art Mask R-CNN. We hope our simple and effective approach will provide a new direction for improving instance segmentation. The source code of our method is available at \url{https://github.com/zjhuang22/maskscoring_rcnn}.