 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniPart: Part-Aware 3D Generation with Semantic Decoupling and Structural Cohesion
Jul 08, 2025The creation of 3D assets with explicit, editable part structures is crucial for advancing interactive applications, yet most generative methods produce only monolithic shapes, limiting their utility. We introduce OmniPart, a novel framework for part-aware 3D object generation designed to achieve high semantic decoupling among components while maintaining robust structural cohesion. OmniPart uniquely decouples this complex task into two synergistic stages: (1) an autoregressive structure planning module generates a controllable, variable-length sequence of 3D part bounding boxes, critically guided by flexible 2D part masks that allow for intuitive control over part decomposition without requiring direct correspondences or semantic labels; and (2) a spatially-conditioned rectified flow model, efficiently adapted from a pre-trained holistic 3D generator, synthesizes all 3D parts simultaneously and consistently within the planned layout. Our approach supports user-defined part granularity, precise localization, and enables diverse downstream applications. Extensive experiments demonstrate that OmniPart achieves state-of-the-art performance, paving the way for more interpretable, editable, and versatile 3D content.
TEXGen: a Generative Diffusion Model for Mesh Textures
Nov 22, 2024



While high-quality texture maps are essential for realistic 3D asset rendering, few studies have explored learning directly in the texture space, especially on large-scale datasets. In this work, we depart from the conventional approach of relying on pre-trained 2D diffusion models for test-time optimization of 3D textures. Instead, we focus on the fundamental problem of learning in the UV texture space itself. For the first time, we train a large diffusion model capable of directly generating high-resolution texture maps in a feed-forward manner. To facilitate efficient learning in high-resolution UV spaces, we propose a scalable network architecture that interleaves convolutions on UV maps with attention layers on point clouds. Leveraging this architectural design, we train a 700 million parameter diffusion model that can generate UV texture maps guided by text prompts and single-view images. Once trained, our model naturally supports various extended applications, including text-guided texture inpainting, sparse-view texture completion, and text-driven texture synthesis. Project page is at http://cvmi-lab.github.io/TEXGen/.
* Accepted to SIGGRAPH Asia Journal Article (TOG 2024)
3D Gaussian Editing with A Single Image
Aug 14, 2024The modeling and manipulation of 3D scenes captured from the real world are pivotal in various applications, attracting growing research interest. While previous works on editing have achieved interesting results through manipulating 3D meshes, they often require accurately reconstructed meshes to perform editing, which limits their application in 3D content generation. To address this gap, we introduce a novel single-image-driven 3D scene editing approach based on 3D Gaussian Splatting, enabling intuitive manipulation via directly editing the content on a 2D image plane. Our method learns to optimize the 3D Gaussians to align with an edited version of the image rendered from a user-specified viewpoint of the original scene. To capture long-range object deformation, we introduce positional loss into the optimization process of 3D Gaussian Splatting and enable gradient propagation through reparameterization. To handle occluded 3D Gaussians when rendering from the specified viewpoint, we build an anchor-based structure and employ a coarse-to-fine optimization strategy capable of handling long-range deformation while maintaining structural stability. Furthermore, we design a novel masking strategy to adaptively identify non-rigid deformation regions for fine-scale modeling. Extensive experiments show the effectiveness of our method in handling geometric details, long-range, and non-rigid deformation, demonstrating superior editing flexibility and quality compared to previous approaches.
PPEA-Depth: Progressive Parameter-Efficient Adaptation for Self-Supervised Monocular Depth Estimation
Jan 17, 2024



Self-supervised monocular depth estimation is of significant importance with applications spanning across autonomous driving and robotics. However, the reliance on self-supervision introduces a strong static-scene assumption, thereby posing challenges in achieving optimal performance in dynamic scenes, which are prevalent in most real-world situations. To address these issues, we propose PPEA-Depth, a Progressive Parameter-Efficient Adaptation approach to transfer a pre-trained image model for self-supervised depth estimation. The training comprises two sequential stages: an initial phase trained on a dataset primarily composed of static scenes, succeeded by an expansion to more intricate datasets involving dynamic scenes. To facilitate this process, we design compact encoder and decoder adapters to enable parameter-efficient tuning, allowing the network to adapt effectively. They not only uphold generalized patterns from pre-trained image models but also retain knowledge gained from the preceding phase into the subsequent one. Extensive experiments demonstrate that PPEA-Depth achieves state-of-the-art performance on KITTI, CityScapes and DDAD datasets.
PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Dec 14, 2023



In this paper, we introduce PI3D, a novel and efficient framework that utilizes the pre-trained text-to-image diffusion models to generate high-quality 3D shapes in minutes. On the one hand, it fine-tunes a pre-trained 2D diffusion model into a 3D diffusion model, enabling both 3D generative capabilities and generalization derived from the 2D model. On the other, it utilizes score distillation sampling of 2D diffusion models to quickly improve the quality of the sampled 3D shapes. PI3D enables the migration of knowledge from image to triplane generation by treating it as a set of pseudo-images. We adapt the modules in the pre-training model to enable hybrid training using pseudo and real images, which has proved to be a well-established strategy for improving generalizability. The efficiency of PI3D is highlighted by its ability to sample diverse 3D models in seconds and refine them in minutes. The experimental results confirm the advantages of PI3D over existing methods based on either 3D diffusion models or lifting 2D diffusion models in terms of fast generation of 3D consistent and high-quality models. The proposed PI3D stands as a promising advancement in the field of text-to-3D generation, and we hope it will inspire more research into 3D generation leveraging the knowledge in both 2D and 3D data.
DualVector: Unsupervised Vector Font Synthesis with Dual-Part Representation
May 17, 2023



Automatic generation of fonts can be an important aid to typeface design. Many current approaches regard glyphs as pixelated images, which present artifacts when scaling and inevitable quality losses after vectorization. On the other hand, existing vector font synthesis methods either fail to represent the shape concisely or require vector supervision during training. To push the quality of vector font synthesis to the next level, we propose a novel dual-part representation for vector glyphs, where each glyph is modeled as a collection of closed "positive" and "negative" path pairs. The glyph contour is then obtained by boolean operations on these paths. We first learn such a representation only from glyph images and devise a subsequent contour refinement step to align the contour with an image representation to further enhance details. Our method, named DualVector, outperforms state-of-the-art methods in vector font synthesis both quantitatively and qualitatively. Our synthesized vector fonts can be easily converted to common digital font formats like TrueType Font for practical use. The code is released at https://github.com/thuliu-yt16/dualvector.
Enhancing Multi-Scale Implicit Learning in Image Super-Resolution with Integrated Positional Encoding
Dec 10, 2021
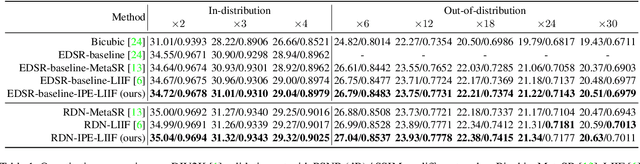
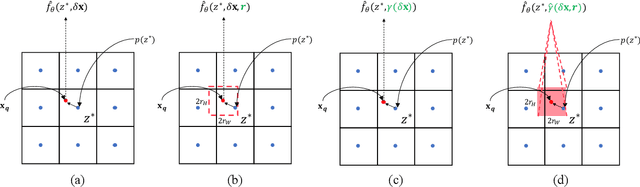

Is the center position fully capable of representing a pixel? There is nothing wrong to represent pixels with their centers in a discrete image representation, but it makes more sense to consider each pixel as the aggregation of signals from a local area in an image super-resolution (SR) context. Despite the great capability of coordinate-based implicit representation in the field of arbitrary-scale image SR, this area's nature of pixels is not fully considered. To this end, we propose integrated positional encoding (IPE), extending traditional positional encoding by aggregating frequency information over the pixel area. We apply IPE to the state-of-the-art arbitrary-scale image super-resolution method: local implicit image function (LIIF), presenting IPE-LIIF. We show the effectiveness of IPE-LIIF by quantitative and qualitative evaluations, and further demonstrate the generalization ability of IPE to larger image scales and multiple implicit-based methods. Code will be released.
Learning Implicit Glyph Shape Representation
Jun 16, 2021
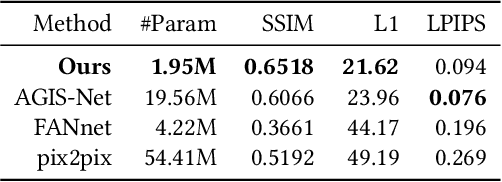
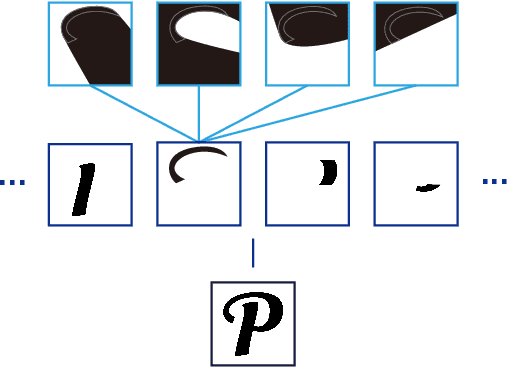

In this paper, we present a novel implicit glyph shape representation, which models glyphs as shape primitives enclosed by quadratic curves, and naturally enables generating glyph images at arbitrary high resolutions. Experiments on font reconstruction and interpolation tasks verified that this structured implicit representation is suitable for describing both structure and style features of glyphs. Furthermore, based on the proposed representation, we design a simple yet effective disentangled network for the challenging one-shot font style transfer problem, and achieve the best results comparing to state-of-the-art alternatives in both quantitative and qualitative comparisons. Benefit from this representation, our generated glyphs have the potential to be converted to vector fonts through post-processing, reducing the gap between rasterized images and vector graphics. We hope this work can provide a powerful tool for 2D shape analysis and synthesis, and inspire further exploitation in implicit representations for 2D shape modeling.