 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixal3D: Pixel-Aligned 3D Generation from Images
May 11, 2026Recent advances in 3D generative models have rapidly improved image-to-3D synthesis quality, enabling higher-resolution geometry and more realistic appearance. Yet fidelity, which measures pixel-level faithfulness of the generated 3D asset to the input image, still remains a central bottleneck. We argue this stems from an implicit 2D-3D correspondence issue: most 3D-native generators synthesize shape in canonical space and inject image cues via attention, leaving pixel-to-3D associations ambiguous. To tackle this issue, we draw inspiration from 3D reconstruction and propose Pixal3D, a pixel-aligned 3D generation paradigm for high-fidelity 3D asset creation from images. Instead of generating in a canonical pose, Pixal3D directly generates 3D in a pixel-aligned way, consistent with the input view. To enable this, we introduce a pixel back-projection conditioning scheme that explicitly lifts multi-scale image features into a 3D feature volume, establishing direct pixel-to-3D correspondence without ambiguity. We show that Pixal3D is not only scalable and capable of producing high-quality 3D assets, but also substantially improves fidelity, approaching the fidelity level of reconstruction. Furthermore, Pixal3D naturally extends to multi-view generation by aggregating back-projected feature volumes across views. Finally, we show pixel-aligned generation benefits scene synthesis, and present a modular pipeline that produces high-fidelity, object-separated 3D scenes from images. Pixal3D for the first time demonstrates 3D-native pixel-aligned generation at scale, and provides a new inspiring way towards high-fidelity 3D generation of object or scene from single or multi-view images. Project page: https://ldyang694.github.io/projects/pixal3d/
SketchFaceGS: Real-Time Sketch-Driven Face Editing and Generation with Gaussian Splatting
Apr 21, 20263D Gaussian representations have emerged as a powerful paradigm for digital head modeling, achieving photorealistic quality with real-time rendering. However, intuitive and interactive creation or editing of 3D Gaussian head models remains challenging. Although 2D sketches provide an ideal interaction modality for fast, intuitive conceptual design, they are sparse, depth-ambiguous, and lack high-frequency appearance cues, making it difficult to infer dense, geometrically consistent 3D Gaussian structures from strokes - especially under real-time constraints. To address these challenges, we propose SketchFaceGS, the first sketch-driven framework for real-time generation and editing of photorealistic 3D Gaussian head models from 2D sketches. Our method uses a feed-forward, coarse-to-fine architecture. A Transformer-based UV feature-prediction module first reconstructs a coarse but geometrically consistent UV feature map from the input sketch, and then a 3D UV feature enhancement module refines it with high-frequency, photorealistic detail to produce a high-fidelity 3D head. For editing, we introduce a UV Mask Fusion technique combined with a layer-by-layer feature-fusion strategy, enabling precise, real-time, free-viewpoint modifications. Extensive experiments show that SketchFaceGS outperforms existing methods in both generation fidelity and editing flexibility, producing high-quality, editable 3D heads from sketches in a single forward pass.
SSD-GS: Scattering and Shadow Decomposition for Relightable 3D Gaussian Splatting
Apr 14, 2026We present SSD-GS, a physically-based relighting framework built upon 3D Gaussian Splatting (3DGS) that achieves high-quality reconstruction and photorealistic relighting under novel lighting conditions. In physically-based relighting, accurately modeling light-material interactions is essential for faithful appearance reproduction. However, existing 3DGS-based relighting methods adopt coarse shading decompositions, either modeling only diffuse and specular reflections or relying on neural networks to approximate shadows and scattering. This leads to limited fidelity and poor physical interpretability, particularly for anisotropic metals and translucent materials. To address these limitations, SSD-GS decomposes reflectance into four components: diffuse, specular, shadow, and subsurface scattering. We introduce a learnable dipole-based scattering module for subsurface transport, an occlusion-aware shadow formulation that integrates visibility estimates with a refinement network, and an enhanced specular component with an anisotropic Fresnel-based model. Through progressive integration of all components during training, SSD-GS effectively disentangles lighting and material properties, even for unseen illumination conditions, as demonstrated on the challenging OLAT dataset. Experiments demonstrate superior quantitative and perceptual relighting quality compared to prior methods and pave the way for downstream tasks, including controllable light source editing and interactive scene relighting. The source code is available at: https://github.com/irisfreesiri/SSD-GS.
MSGS: Multispectral 3D Gaussian Splatting
Apr 14, 2026We present a multispectral extension to 3D Gaussian Splatting (3DGS) for wavelength-aware view synthesis. Each Gaussian is augmented with spectral radiance, represented via per-band spherical harmonics, and optimized under a dual-loss supervision scheme combining RGB and multispectral signals. To improve rendering fidelity, we perform spectral-to-RGB conversion at the pixel level, allowing richer spectral cues to be retained during optimization. Our method is evaluated on both public and self-captured real-world datasets, demonstrating consistent improvements over the RGB-only 3DGS baseline in terms of image quality and spectral consistency. Notably, it excels in challenging scenes involving translucent materials and anisotropic reflections. The proposed approach maintains the compactness and real-time efficiency of 3DGS while laying the foundation for future integration with physically based shading models.
* Published in IEEE ISMAR 2025 Adjunct
RL-ScanIQA: Reinforcement-Learned Scanpaths for Blind 360°Image Quality Assessment
Mar 15, 2026Blind 360°image quality assessment (IQA) aims to predict perceptual quality for panoramic images without a pristine reference. Unlike conventional planar images, 360°content in immersive environments restricts viewers to a limited viewport at any moment, making viewing behaviors critical to quality perception. Although existing scanpath-based approaches have attempted to model viewing behaviors by approximating the human view-then-rate paradigm, they treat scanpath generation and quality assessment as separate steps, preventing end-to-end optimization and task-aligned exploration. To address this limitation, we propose RL-ScanIQA, a reinforcement-learned framework for blind 360°IQA. RL-ScanIQA optimize a PPO-trained scanpath policy and a quality assessor, where the policy receives quality-driven feedback to learn task-relevant viewing strategies. To improve training stability and prevent mode collapse, we design multi-level rewards, including scanpath diversity and equator-biased priors. We further boost cross-dataset robustness using distortion-space augmentation together with rank-consistent losses that preserve intra-image and inter-image quality orderings. Extensive experiments on three benchmarks show that RL-ScanIQA achieves superior in-dataset performance and cross-dataset generalization. Codes are available at https://github.com/wangyuji1/RLScanIQA.git.
Cross360: 360° Monocular Depth Estimation via Cross Projections Across Scales
Jan 24, 2026360° depth estimation is a challenging research problem due to the difficulty of finding a representation that both preserves global continuity and avoids distortion in spherical images. Existing methods attempt to leverage complementary information from multiple projections, but struggle with balancing global and local consistency. Their local patch features have limited global perception, and the combined global representation does not address discrepancies in feature extraction at the boundaries between patches. To address these issues, we propose Cross360, a novel cross-attention-based architecture integrating local and global information using less-distorted tangent patches along with equirectangular features. Our Cross Projection Feature Alignment module employs cross-attention to align local tangent projection features with the equirectangular projection's 360° field of view, ensuring each tangent projection patch is aware of the global context. Additionally, our Progressive Feature Aggregation with Attention module refines multi-scaled features progressively, enhancing depth estimation accuracy. Cross360 significantly outperforms existing methods across most benchmark datasets, especially those in which the entire 360° image is available, demonstrating its effectiveness in accurate and globally consistent depth estimation. The code and model are available at https://github.com/huangkun101230/Cross360.
SE360: Semantic Edit in 360$^\circ$ Panoramas via Hierarchical Data Construction
Dec 23, 2025While instruction-based image editing is emerging, extending it to 360$^\circ$ panoramas introduces additional challenges. Existing methods often produce implausible results in both equirectangular projections (ERP) and perspective views. To address these limitations, we propose SE360, a novel framework for multi-condition guided object editing in 360$^\circ$ panoramas. At its core is a novel coarse-to-fine autonomous data generation pipeline without manual intervention. This pipeline leverages a Vision-Language Model (VLM) and adaptive projection adjustment for hierarchical analysis, ensuring the holistic segmentation of objects and their physical context. The resulting data pairs are both semantically meaningful and geometrically consistent, even when sourced from unlabeled panoramas. Furthermore, we introduce a cost-effective, two-stage data refinement strategy to improve data realism and mitigate model overfitting to erase artifacts. Based on the constructed dataset, we train a Transformer-based diffusion model to allow flexible object editing guided by text, mask, or reference image in 360$^\circ$ panoramas. Our experiments demonstrate that our method outperforms existing methods in both visual quality and semantic accuracy.
RTR-GS: 3D Gaussian Splatting for Inverse Rendering with Radiance Transfer and Reflection
Jul 10, 2025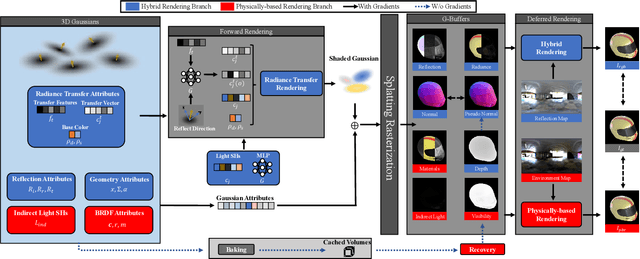
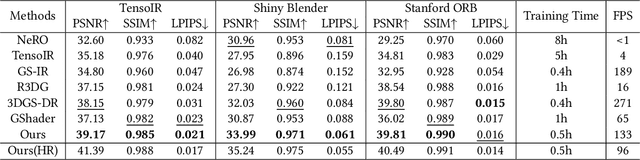
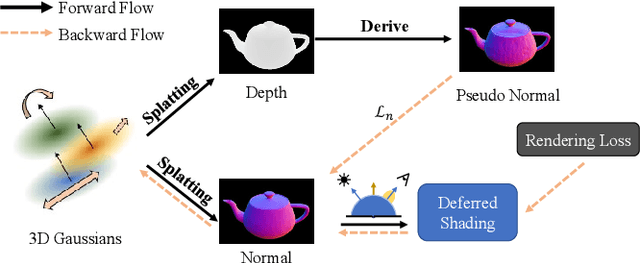
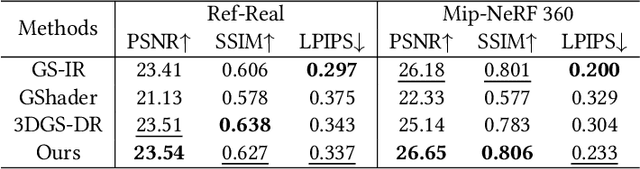
3D Gaussian Splatting (3DGS) has demonstrated impressive capabilities in novel view synthesis. However, rendering reflective objects remains a significant challenge, particularly in inverse rendering and relighting. We introduce RTR-GS, a novel inverse rendering framework capable of robustly rendering objects with arbitrary reflectance properties, decomposing BRDF and lighting, and delivering credible relighting results. Given a collection of multi-view images, our method effectively recovers geometric structure through a hybrid rendering model that combines forward rendering for radiance transfer with deferred rendering for reflections. This approach successfully separates high-frequency and low-frequency appearances, mitigating floating artifacts caused by spherical harmonic overfitting when handling high-frequency details. We further refine BRDF and lighting decomposition using an additional physically-based deferred rendering branch. Experimental results show that our method enhances novel view synthesis, normal estimation, decomposition, and relighting while maintaining efficient training inference process.
Multi-task Geometric Estimation of Depth and Surface Normal from Monocular 360° Images
Nov 04, 2024



Geometric estimation is required for scene understanding and analysis in panoramic 360{\deg} images. Current methods usually predict a single feature, such as depth or surface normal. These methods can lack robustness, especially when dealing with intricate textures or complex object surfaces. We introduce a novel multi-task learning (MTL) network that simultaneously estimates depth and surface normals from 360{\deg} images. Our first innovation is our MTL architecture, which enhances predictions for both tasks by integrating geometric information from depth and surface normal estimation, enabling a deeper understanding of 3D scene structure. Another innovation is our fusion module, which bridges the two tasks, allowing the network to learn shared representations that improve accuracy and robustness. Experimental results demonstrate that our MTL architecture significantly outperforms state-of-the-art methods in both depth and surface normal estimation, showing superior performance in complex and diverse scenes. Our model's effectiveness and generalizability, particularly in handling intricate surface textures, establish it as a new benchmark in 360{\deg} image geometric estimation. The code and model are available at \url{https://github.com/huangkun101230/360MTLGeometricEstimation}.
3D Gaussian Editing with A Single Image
Aug 14, 2024



The modeling and manipulation of 3D scenes captured from the real world are pivotal in various applications, attracting growing research interest. While previous works on editing have achieved interesting results through manipulating 3D meshes, they often require accurately reconstructed meshes to perform editing, which limits their application in 3D content generation. To address this gap, we introduce a novel single-image-driven 3D scene editing approach based on 3D Gaussian Splatting, enabling intuitive manipulation via directly editing the content on a 2D image plane. Our method learns to optimize the 3D Gaussians to align with an edited version of the image rendered from a user-specified viewpoint of the original scene. To capture long-range object deformation, we introduce positional loss into the optimization process of 3D Gaussian Splatting and enable gradient propagation through reparameterization. To handle occluded 3D Gaussians when rendering from the specified viewpoint, we build an anchor-based structure and employ a coarse-to-fine optimization strategy capable of handling long-range deformation while maintaining structural stability. Furthermore, we design a novel masking strategy to adaptively identify non-rigid deformation regions for fine-scale modeling. Extensive experiments show the effectiveness of our method in handling geometric details, long-range, and non-rigid deformation, demonstrating superior editing flexibility and quality compared to previous approaches.