 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning
Jul 22, 2025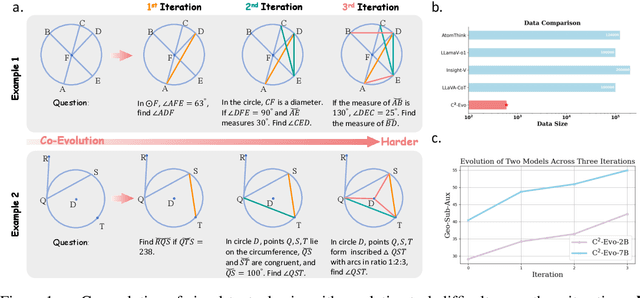

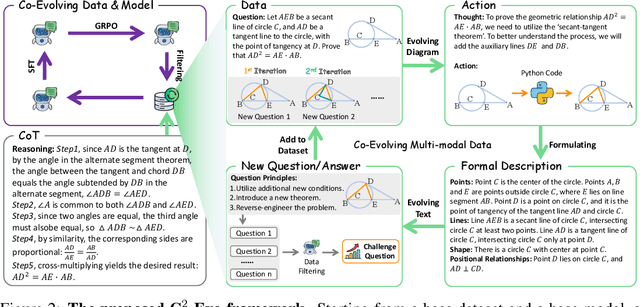
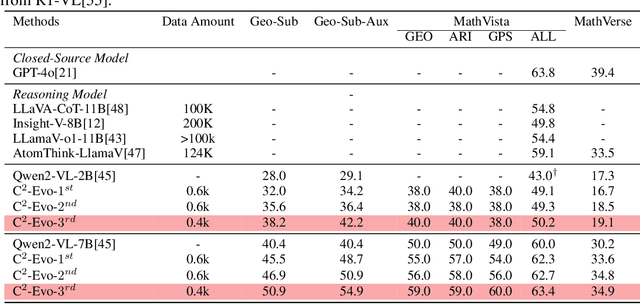
Recent advances in multimodal large language models (MLLMs) have shown impressive reasoning capabilities. However, further enhancing existing MLLMs necessitates high-quality vision-language datasets with carefully curated task complexities, which are both costly and challenging to scale. Although recent self-improving models that iteratively refine themselves offer a feasible solution, they still suffer from two core challenges: (i) most existing methods augment visual or textual data separately, resulting in discrepancies in data complexity (e.g., over-simplified diagrams paired with redundant textual descriptions); and (ii) the evolution of data and models is also separated, leading to scenarios where models are exposed to tasks with mismatched difficulty levels. To address these issues, we propose C2-Evo, an automatic, closed-loop self-improving framework that jointly evolves both training data and model capabilities. Specifically, given a base dataset and a base model, C2-Evo enhances them by a cross-modal data evolution loop and a data-model evolution loop. The former loop expands the base dataset by generating complex multimodal problems that combine structured textual sub-problems with iteratively specified geometric diagrams, while the latter loop adaptively selects the generated problems based on the performance of the base model, to conduct supervised fine-tuning and reinforcement learning alternately. Consequently, our method continuously refines its model and training data, and consistently obtains considerable performance gains across multiple mathematical reasoning benchmarks. Our code, models, and datasets will be released.
SeePhys: Does Seeing Help Thinking? -- Benchmarking Vision-Based Physics Reasoning
May 25, 2025We present SeePhys, a large-scale multimodal benchmark for LLM reasoning grounded in physics questions ranging from middle school to PhD qualifying exams. The benchmark covers 7 fundamental domains spanning the physics discipline, incorporating 21 categories of highly heterogeneous diagrams. In contrast to prior works where visual elements mainly serve auxiliary purposes, our benchmark features a substantial proportion of vision-essential problems (75\%) that mandate visual information extraction for correct solutions. Through extensive evaluation, we observe that even the most advanced visual reasoning models (e.g., Gemini-2.5-pro and o4-mini) achieve sub-60\% accuracy on our benchmark. These results reveal fundamental challenges in current large language models' visual understanding capabilities, particularly in: (i) establishing rigorous coupling between diagram interpretation and physics reasoning, and (ii) overcoming their persistent reliance on textual cues as cognitive shortcuts.
From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
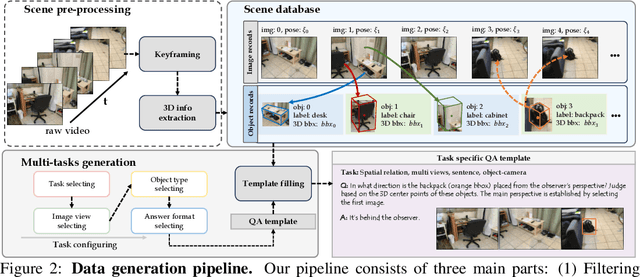
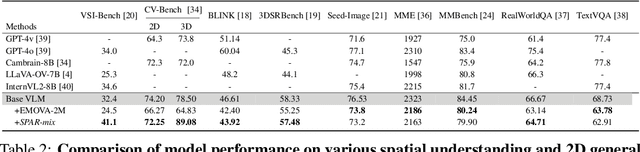

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
Can Atomic Step Decomposition Enhance the Self-structured Reasoning of Multimodal Large Models?
Mar 08, 2025In this paper, we address the challenging task of multimodal mathematical reasoning by incorporating the ability of "slow thinking" into multimodal large language models (MLLMs). Our core idea is that different levels of reasoning abilities can be combined dynamically to tackle questions with different complexity. To this end, we propose a paradigm of Self-structured Chain of Thought (SCoT), which is composed of minimal semantic atomic steps. Different from existing methods that rely on structured templates or free-form paradigms, our method can not only generate cognitive CoT structures for various complex tasks but also mitigates the phenomenon of overthinking. To introduce structured reasoning capabilities into visual understanding models, we further design a novel AtomThink framework with four key modules, including (i) a data engine to generate high-quality multimodal reasoning paths; (ii) a supervised fine-tuning process with serialized inference data; (iii) a policy-guided multi-turn inference method; and (iv) an atomic capability metric to evaluate the single step utilization rate. We conduct extensive experiments to show that the proposed AtomThink significantly improves the performance of baseline MLLMs, achieving more than 10\% average accuracy gains on MathVista and MathVerse. Compared to state-of-the-art structured CoT approaches, our method not only achieves higher accuracy but also improves data utilization by 5 times and boosts inference efficiency by 85.3\%. Our code is now public available in https://github.com/Quinn777/AtomThink.
4Dynamic: Text-to-4D Generation with Hybrid Priors
Jul 17, 2024

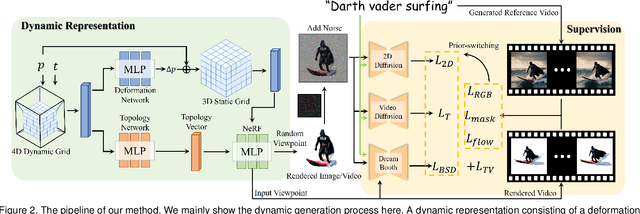

Due to the fascinating generative performance of text-to-image diffusion models, growing text-to-3D generation works explore distilling the 2D generative priors into 3D, using the score distillation sampling (SDS) loss, to bypass the data scarcity problem. The existing text-to-3D methods have achieved promising results in realism and 3D consistency, but text-to-4D generation still faces challenges, including lack of realism and insufficient dynamic motions. In this paper, we propose a novel method for text-to-4D generation, which ensures the dynamic amplitude and authenticity through direct supervision provided by a video prior. Specifically, we adopt a text-to-video diffusion model to generate a reference video and divide 4D generation into two stages: static generation and dynamic generation. The static 3D generation is achieved under the guidance of the input text and the first frame of the reference video, while in the dynamic generation stage, we introduce a customized SDS loss to ensure multi-view consistency, a video-based SDS loss to improve temporal consistency, and most importantly, direct priors from the reference video to ensure the quality of geometry and texture. Moreover, we design a prior-switching training strategy to avoid conflicts between different priors and fully leverage the benefits of each prior. In addition, to enrich the generated motion, we further introduce a dynamic modeling representation composed of a deformation network and a topology network, which ensures dynamic continuity while modeling topological changes. Our method not only supports text-to-4D generation but also enables 4D generation from monocular videos. The comparison experiments demonstrate the superiority of our method compared to existing methods.
StylizedGS: Controllable Stylization for 3D Gaussian Splatting
Apr 08, 2024
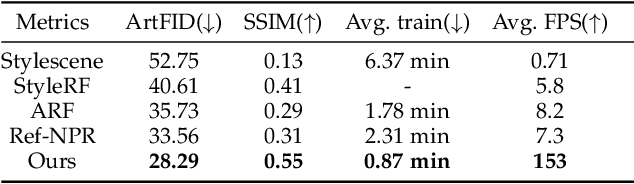
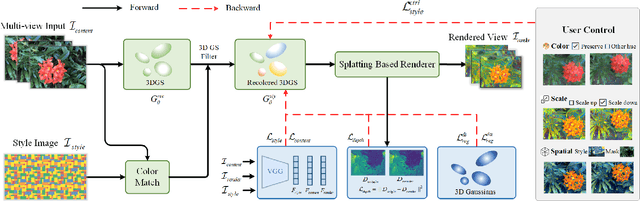

With the rapid development of XR, 3D generation and editing are becoming more and more important, among which, stylization is an important tool of 3D appearance editing. It can achieve consistent 3D artistic stylization given a single reference style image and thus is a user-friendly editing way. However, recent NeRF-based 3D stylization methods face efficiency issues that affect the actual user experience and the implicit nature limits its ability to transfer the geometric pattern styles. Additionally, the ability for artists to exert flexible control over stylized scenes is considered highly desirable, fostering an environment conducive to creative exploration. In this paper, we introduce StylizedGS, a 3D neural style transfer framework with adaptable control over perceptual factors based on 3D Gaussian Splatting (3DGS) representation. The 3DGS brings the benefits of high efficiency. We propose a GS filter to eliminate floaters in the reconstruction which affects the stylization effects before stylization. Then the nearest neighbor-based style loss is introduced to achieve stylization by fine-tuning the geometry and color parameters of 3DGS, while a depth preservation loss with other regularizations is proposed to prevent the tampering of geometry content. Moreover, facilitated by specially designed losses, StylizedGS enables users to control color, stylized scale and regions during the stylization to possess customized capabilities. Our method can attain high-quality stylization results characterized by faithful brushstrokes and geometric consistency with flexible controls. Extensive experiments across various scenes and styles demonstrate the effectiveness and efficiency of our method concerning both stylization quality and inference FPS.
Recent Advances in 3D Gaussian Splatting
Mar 17, 2024


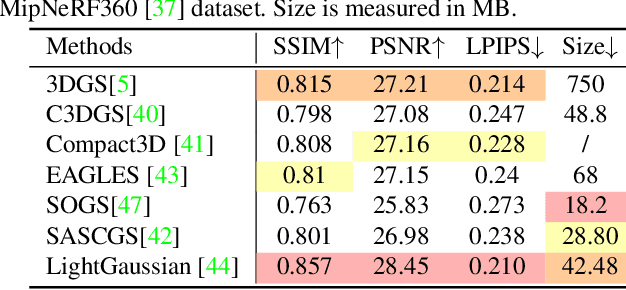
The emergence of 3D Gaussian Splatting (3DGS) has greatly accelerated the rendering speed of novel view synthesis. Unlike neural implicit representations like Neural Radiance Fields (NeRF) that represent a 3D scene with position and viewpoint-conditioned neural networks, 3D Gaussian Splatting utilizes a set of Gaussian ellipsoids to model the scene so that efficient rendering can be accomplished by rasterizing Gaussian ellipsoids into images. Apart from the fast rendering speed, the explicit representation of 3D Gaussian Splatting facilitates editing tasks like dynamic reconstruction, geometry editing, and physical simulation. Considering the rapid change and growing number of works in this field, we present a literature review of recent 3D Gaussian Splatting methods, which can be roughly classified into 3D reconstruction, 3D editing, and other downstream applications by functionality. Traditional point-based rendering methods and the rendering formulation of 3D Gaussian Splatting are also illustrated for a better understanding of this technique. This survey aims to help beginners get into this field quickly and provide experienced researchers with a comprehensive overview, which can stimulate the future development of the 3D Gaussian Splatting representation.
Mesh-based Gaussian Splatting for Real-time Large-scale Deformation
Feb 07, 2024Neural implicit representations, including Neural Distance Fields and Neural Radiance Fields, have demonstrated significant capabilities for reconstructing surfaces with complicated geometry and topology, and generating novel views of a scene. Nevertheless, it is challenging for users to directly deform or manipulate these implicit representations with large deformations in the real-time fashion. Gaussian Splatting(GS) has recently become a promising method with explicit geometry for representing static scenes and facilitating high-quality and real-time synthesis of novel views. However,it cannot be easily deformed due to the use of discrete Gaussians and lack of explicit topology. To address this, we develop a novel GS-based method that enables interactive deformation. Our key idea is to design an innovative mesh-based GS representation, which is integrated into Gaussian learning and manipulation. 3D Gaussians are defined over an explicit mesh, and they are bound with each other: the rendering of 3D Gaussians guides the mesh face split for adaptive refinement, and the mesh face split directs the splitting of 3D Gaussians. Moreover, the explicit mesh constraints help regularize the Gaussian distribution, suppressing poor-quality Gaussians(e.g. misaligned Gaussians,long-narrow shaped Gaussians), thus enhancing visual quality and avoiding artifacts during deformation. Based on this representation, we further introduce a large-scale Gaussian deformation technique to enable deformable GS, which alters the parameters of 3D Gaussians according to the manipulation of the associated mesh. Our method benefits from existing mesh deformation datasets for more realistic data-driven Gaussian deformation. Extensive experiments show that our approach achieves high-quality reconstruction and effective deformation, while maintaining the promising rendering results at a high frame rate(65 FPS on average).
StylizedNeRF: Consistent 3D Scene Stylization as Stylized NeRF via 2D-3D Mutual Learning
May 25, 2022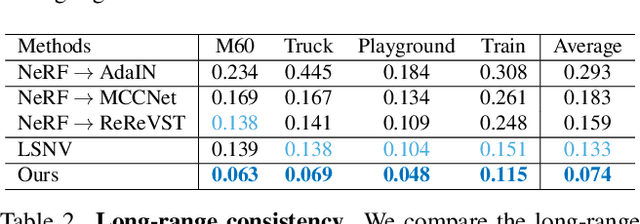

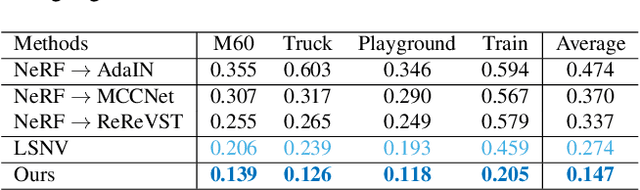
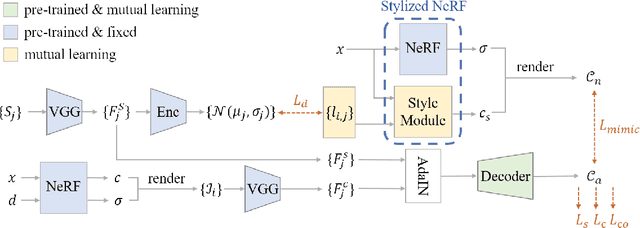
3D scene stylization aims at generating stylized images of the scene from arbitrary novel views following a given set of style examples, while ensuring consistency when rendered from different views. Directly applying methods for image or video stylization to 3D scenes cannot achieve such consistency. Thanks to recently proposed neural radiance fields (NeRF), we are able to represent a 3D scene in a consistent way. Consistent 3D scene stylization can be effectively achieved by stylizing the corresponding NeRF. However, there is a significant domain gap between style examples which are 2D images and NeRF which is an implicit volumetric representation. To address this problem, we propose a novel mutual learning framework for 3D scene stylization that combines a 2D image stylization network and NeRF to fuse the stylization ability of 2D stylization network with the 3D consistency of NeRF. We first pre-train a standard NeRF of the 3D scene to be stylized and replace its color prediction module with a style network to obtain a stylized NeRF. It is followed by distilling the prior knowledge of spatial consistency from NeRF to the 2D stylization network through an introduced consistency loss. We also introduce a mimic loss to supervise the mutual learning of the NeRF style module and fine-tune the 2D stylization decoder. In order to further make our model handle ambiguities of 2D stylization results, we introduce learnable latent codes that obey the probability distributions conditioned on the style. They are attached to training samples as conditional inputs to better learn the style module in our novel stylized NeRF. Experimental results demonstrate that our method is superior to existing approaches in both visual quality and long-range consistency.
NeRF-Editing: Geometry Editing of Neural Radiance Fields
May 10, 2022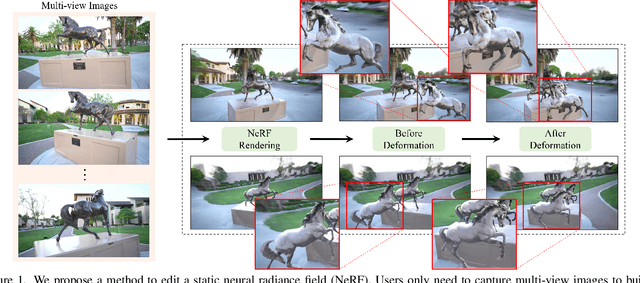

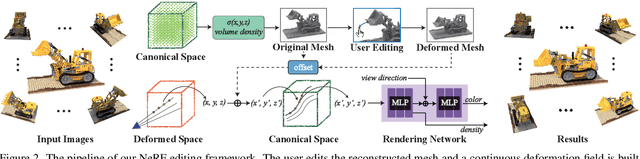

Implicit neural rendering, especially Neural Radiance Field (NeRF), has shown great potential in novel view synthesis of a scene. However, current NeRF-based methods cannot enable users to perform user-controlled shape deformation in the scene. While existing works have proposed some approaches to modify the radiance field according to the user's constraints, the modification is limited to color editing or object translation and rotation. In this paper, we propose a method that allows users to perform controllable shape deformation on the implicit representation of the scene, and synthesizes the novel view images of the edited scene without re-training the network. Specifically, we establish a correspondence between the extracted explicit mesh representation and the implicit neural representation of the target scene. Users can first utilize well-developed mesh-based deformation methods to deform the mesh representation of the scene. Our method then utilizes user edits from the mesh representation to bend the camera rays by introducing a tetrahedra mesh as a proxy, obtaining the rendering results of the edited scene. Extensive experiments demonstrate that our framework can achieve ideal editing results not only on synthetic data, but also on real scenes captured by users.