 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniGen: Unified $S^3$ Fields for Animatable 3D Asset Generation
Apr 14, 2026Animatable 3D assets, defined as geometry equipped with an articulated skeleton and skinning weights, are fundamental to interactive graphics, embodied agents, and animation production. While recent 3D generative models can synthesize visually plausible shapes from images, the results are typically static. Obtaining usable rigs via post-hoc auto-rigging is brittle and often produces skeletons that are topologically inconsistent with the generated geometry. We present AniGen, a unified framework that directly generates animate-ready 3D assets conditioned on a single image. Our key insight is to represent shape, skeleton, and skinning as mutually consistent $S^3$ Fields (Shape, Skeleton, Skin) defined over a shared spatial domain. To enable the robust learning of these fields, we introduce two technical innovations: (i) a confidence-decaying skeleton field that explicitly handles the geometric ambiguity of bone prediction at Voronoi boundaries, and (ii) a dual skin feature field that decouples skinning weights from specific joint counts, allowing a fixed-architecture network to predict rigs of arbitrary complexity. Built upon a two-stage flow-matching pipeline, AniGen first synthesizes a sparse structural scaffold and then generates dense geometry and articulation in a structured latent space. Extensive experiments demonstrate that AniGen substantially outperforms state-of-the-art sequential baselines in rig validity and animation quality, generalizing effectively to in-the-wild images across diverse categories including animals, humanoids, and machinery. Homepage: https://yihua7.github.io/AniGen-web/
ObjectMorpher: 3D-Aware Image Editing via Deformable 3DGS Models
Mar 30, 2026Achieving precise, object-level control in image editing remains challenging: 2D methods lack 3D awareness and often yield ambiguous or implausible results, while existing 3D-aware approaches rely on heavy optimization or incomplete monocular reconstructions. We present ObjectMorpher, a unified, interactive framework that converts ambiguous 2D edits into geometry-grounded operations. ObjectMorpher lifts target instances with an image-to-3D generator into editable 3D Gaussian Splatting (3DGS), enabling fast, identity-preserving manipulation. Users drag control points; a graph-based non-rigid deformation with as-rigid-as-possible (ARAP) constraints ensures physically sensible shape and pose changes. A composite diffusion module harmonizes lighting, color, and boundaries for seamless reintegration. Across diverse categories, ObjectMorpher delivers fine-grained, photorealistic edits with superior controllability and efficiency, outperforming 2D drag and 3D-aware baselines on KID, LPIPS, SIFID, and user preference.
UniGeo: Taming Video Diffusion for Unified Consistent Geometry Estimation
May 30, 2025Recently, methods leveraging diffusion model priors to assist monocular geometric estimation (e.g., depth and normal) have gained significant attention due to their strong generalization ability. However, most existing works focus on estimating geometric properties within the camera coordinate system of individual video frames, neglecting the inherent ability of diffusion models to determine inter-frame correspondence. In this work, we demonstrate that, through appropriate design and fine-tuning, the intrinsic consistency of video generation models can be effectively harnessed for consistent geometric estimation. Specifically, we 1) select geometric attributes in the global coordinate system that share the same correspondence with video frames as the prediction targets, 2) introduce a novel and efficient conditioning method by reusing positional encodings, and 3) enhance performance through joint training on multiple geometric attributes that share the same correspondence. Our results achieve superior performance in predicting global geometric attributes in videos and can be directly applied to reconstruction tasks. Even when trained solely on static video data, our approach exhibits the potential to generalize to dynamic video scenes.
Learning Critically: Selective Self Distillation in Federated Learning on Non-IID Data
Apr 20, 2025Federated learning (FL) enables multiple clients to collaboratively train a global model while keeping local data decentralized. Data heterogeneity (non-IID) across clients has imposed significant challenges to FL, which makes local models re-optimize towards their own local optima and forget the global knowledge, resulting in performance degradation and convergence slowdown. Many existing works have attempted to address the non-IID issue by adding an extra global-model-based regularizing item to the local training but without an adaption scheme, which is not efficient enough to achieve high performance with deep learning models. In this paper, we propose a Selective Self-Distillation method for Federated learning (FedSSD), which imposes adaptive constraints on the local updates by self-distilling the global model's knowledge and selectively weighting it by evaluating the credibility at both the class and sample level. The convergence guarantee of FedSSD is theoretically analyzed and extensive experiments are conducted on three public benchmark datasets, which demonstrates that FedSSD achieves better generalization and robustness in fewer communication rounds, compared with other state-of-the-art FL methods.
Deformable Radial Kernel Splatting
Dec 16, 2024



Recently, Gaussian splatting has emerged as a robust technique for representing 3D scenes, enabling real-time rasterization and high-fidelity rendering. However, Gaussians' inherent radial symmetry and smoothness constraints limit their ability to represent complex shapes, often requiring thousands of primitives to approximate detailed geometry. We introduce Deformable Radial Kernel (DRK), which extends Gaussian splatting into a more general and flexible framework. Through learnable radial bases with adjustable angles and scales, DRK efficiently models diverse shape primitives while enabling precise control over edge sharpness and boundary curvature. iven DRK's planar nature, we further develop accurate ray-primitive intersection computation for depth sorting and introduce efficient kernel culling strategies for improved rasterization efficiency. Extensive experiments demonstrate that DRK outperforms existing methods in both representation efficiency and rendering quality, achieving state-of-the-art performance while dramatically reducing primitive count.
NeRF-Texture: Synthesizing Neural Radiance Field Textures
Dec 13, 2024



Texture synthesis is a fundamental problem in computer graphics that would benefit various applications. Existing methods are effective in handling 2D image textures. In contrast, many real-world textures contain meso-structure in the 3D geometry space, such as grass, leaves, and fabrics, which cannot be effectively modeled using only 2D image textures. We propose a novel texture synthesis method with Neural Radiance Fields (NeRF) to capture and synthesize textures from given multi-view images. In the proposed NeRF texture representation, a scene with fine geometric details is disentangled into the meso-structure textures and the underlying base shape. This allows textures with meso-structure to be effectively learned as latent features situated on the base shape, which are fed into a NeRF decoder trained simultaneously to represent the rich view-dependent appearance. Using this implicit representation, we can synthesize NeRF-based textures through patch matching of latent features. However, inconsistencies between the metrics of the reconstructed content space and the latent feature space may compromise the synthesis quality. To enhance matching performance, we further regularize the distribution of latent features by incorporating a clustering constraint. In addition to generating NeRF textures over a planar domain, our method can also synthesize NeRF textures over curved surfaces, which are practically useful. Experimental results and evaluations demonstrate the effectiveness of our approach.
Splatter a Video: Video Gaussian Representation for Versatile Processing
Jun 19, 2024



Video representation is a long-standing problem that is crucial for various down-stream tasks, such as tracking,depth prediction,segmentation,view synthesis,and editing. However, current methods either struggle to model complex motions due to the absence of 3D structure or rely on implicit 3D representations that are ill-suited for manipulation tasks. To address these challenges, we introduce a novel explicit 3D representation-video Gaussian representation -- that embeds a video into 3D Gaussians. Our proposed representation models video appearance in a 3D canonical space using explicit Gaussians as proxies and associates each Gaussian with 3D motions for video motion. This approach offers a more intrinsic and explicit representation than layered atlas or volumetric pixel matrices. To obtain such a representation, we distill 2D priors, such as optical flow and depth, from foundation models to regularize learning in this ill-posed setting. Extensive applications demonstrate the versatility of our new video representation. It has been proven effective in numerous video processing tasks, including tracking, consistent video depth and feature refinement, motion and appearance editing, and stereoscopic video generation. Project page: https://sunyangtian.github.io/spatter_a_video_web/
3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting
Mar 30, 2024In this paper, we present an implicit surface reconstruction method with 3D Gaussian Splatting (3DGS), namely 3DGSR, that allows for accurate 3D reconstruction with intricate details while inheriting the high efficiency and rendering quality of 3DGS. The key insight is incorporating an implicit signed distance field (SDF) within 3D Gaussians to enable them to be aligned and jointly optimized. First, we introduce a differentiable SDF-to-opacity transformation function that converts SDF values into corresponding Gaussians' opacities. This function connects the SDF and 3D Gaussians, allowing for unified optimization and enforcing surface constraints on the 3D Gaussians. During learning, optimizing the 3D Gaussians provides supervisory signals for SDF learning, enabling the reconstruction of intricate details. However, this only provides sparse supervisory signals to the SDF at locations occupied by Gaussians, which is insufficient for learning a continuous SDF. Then, to address this limitation, we incorporate volumetric rendering and align the rendered geometric attributes (depth, normal) with those derived from 3D Gaussians. This consistency regularization introduces supervisory signals to locations not covered by discrete 3D Gaussians, effectively eliminating redundant surfaces outside the Gaussian sampling range. Our extensive experimental results demonstrate that our 3DGSR method enables high-quality 3D surface reconstruction while preserving the efficiency and rendering quality of 3DGS. Besides, our method competes favorably with leading surface reconstruction techniques while offering a more efficient learning process and much better rendering qualities. The code will be available at https://github.com/CVMI-Lab/3DGSR.
StylizedNeRF: Consistent 3D Scene Stylization as Stylized NeRF via 2D-3D Mutual Learning
May 25, 2022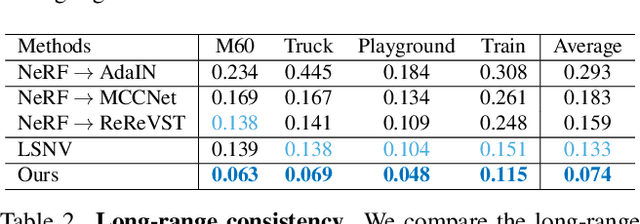

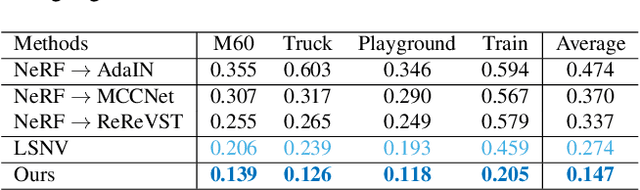
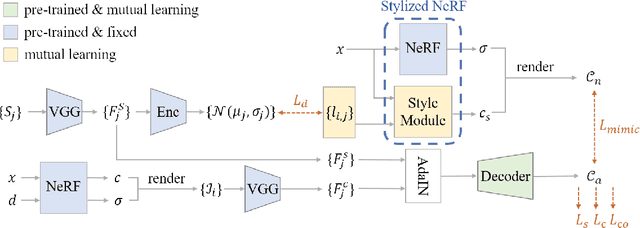
3D scene stylization aims at generating stylized images of the scene from arbitrary novel views following a given set of style examples, while ensuring consistency when rendered from different views. Directly applying methods for image or video stylization to 3D scenes cannot achieve such consistency. Thanks to recently proposed neural radiance fields (NeRF), we are able to represent a 3D scene in a consistent way. Consistent 3D scene stylization can be effectively achieved by stylizing the corresponding NeRF. However, there is a significant domain gap between style examples which are 2D images and NeRF which is an implicit volumetric representation. To address this problem, we propose a novel mutual learning framework for 3D scene stylization that combines a 2D image stylization network and NeRF to fuse the stylization ability of 2D stylization network with the 3D consistency of NeRF. We first pre-train a standard NeRF of the 3D scene to be stylized and replace its color prediction module with a style network to obtain a stylized NeRF. It is followed by distilling the prior knowledge of spatial consistency from NeRF to the 2D stylization network through an introduced consistency loss. We also introduce a mimic loss to supervise the mutual learning of the NeRF style module and fine-tune the 2D stylization decoder. In order to further make our model handle ambiguities of 2D stylization results, we introduce learnable latent codes that obey the probability distributions conditioned on the style. They are attached to training samples as conditional inputs to better learn the style module in our novel stylized NeRF. Experimental results demonstrate that our method is superior to existing approaches in both visual quality and long-range consistency.