 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVVLoc: Prior-free 3-DoF Vehicle Visual Localization
Jan 31, 2026Localization is a critical technology in autonomous driving, encompassing both topological localization, which identifies the most similar map keyframe to the current observation, and metric localization, which provides precise spatial coordinates. Conventional methods typically address these tasks independently, rely on single-camera setups, and often require additional 3D semantic or pose priors, while lacking mechanisms to quantify the confidence of localization results, making them less feasible for real industrial applications. In this paper, we propose VVLoc, a unified pipeline that employs a single neural network to concurrently achieve topological and metric vehicle localization using multi-camera system. VVLoc first evaluates the geo-proximity between visual observations, then estimates their relative metric poses using a matching strategy, while also providing a confidence measure. Additionally, the training process for VVLoc is highly efficient, requiring only pairs of visual data and corresponding ground-truth poses, eliminating the need for complex supplementary data. We evaluate VVLoc not only on the publicly available datasets, but also on a more challenging self-collected dataset, demonstrating its ability to deliver state-of-the-art localization accuracy across a wide range of localization tasks.
From Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
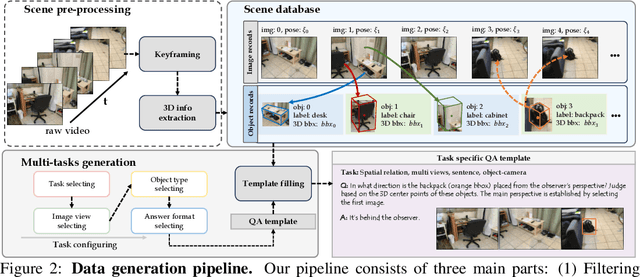
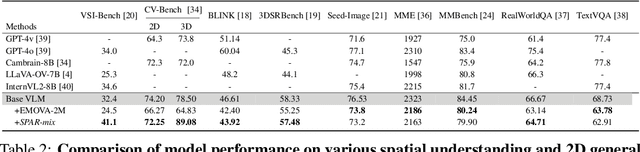

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
WoVoGen: World Volume-aware Diffusion for Controllable Multi-camera Driving Scene Generation
Dec 06, 2023



Generating multi-camera street-view videos is critical for augmenting autonomous driving datasets, addressing the urgent demand for extensive and varied data. Due to the limitations in diversity and challenges in handling lighting conditions, traditional rendering-based methods are increasingly being supplanted by diffusion-based methods. However, a significant challenge in diffusion-based methods is ensuring that the generated sensor data preserve both intra-world consistency and inter-sensor coherence. To address these challenges, we combine an additional explicit world volume and propose the World Volume-aware Multi-camera Driving Scene Generator (WoVoGen). This system is specifically designed to leverage 4D world volume as a foundational element for video generation. Our model operates in two distinct phases: (i) envisioning the future 4D temporal world volume based on vehicle control sequences, and (ii) generating multi-camera videos, informed by this envisioned 4D temporal world volume and sensor interconnectivity. The incorporation of the 4D world volume empowers WoVoGen not only to generate high-quality street-view videos in response to vehicle control inputs but also to facilitate scene editing tasks.
MLPST: MLP is All You Need for Spatio-Temporal Prediction
Sep 23, 2023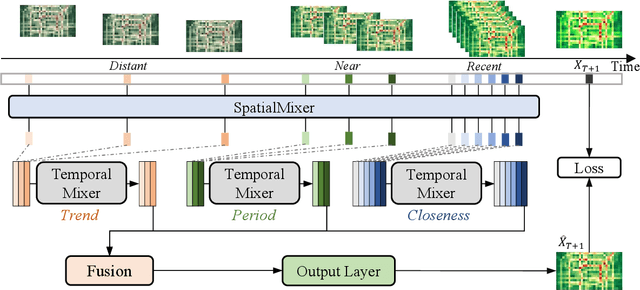
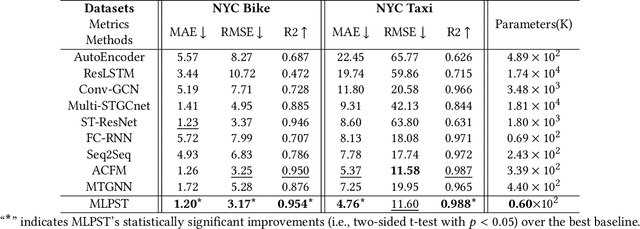
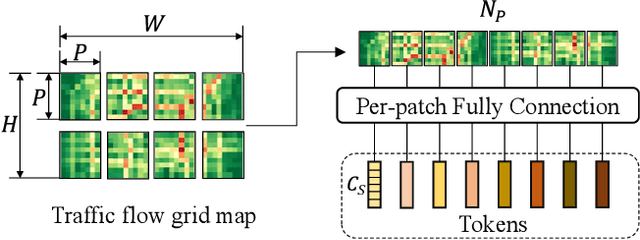
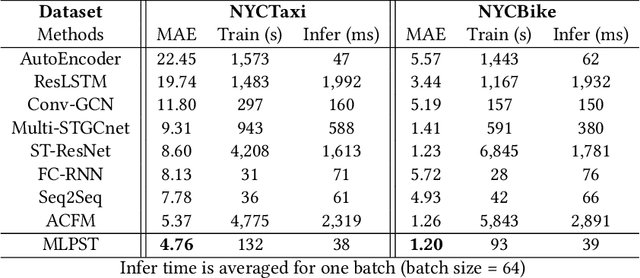
Traffic prediction is a typical spatio-temporal data mining task and has great significance to the public transportation system. Considering the demand for its grand application, we recognize key factors for an ideal spatio-temporal prediction method: efficient, lightweight, and effective. However, the current deep model-based spatio-temporal prediction solutions generally own intricate architectures with cumbersome optimization, which can hardly meet these expectations. To accomplish the above goals, we propose an intuitive and novel framework, MLPST, a pure multi-layer perceptron architecture for traffic prediction. Specifically, we first capture spatial relationships from both local and global receptive fields. Then, temporal dependencies in different intervals are comprehensively considered. Through compact and swift MLP processing, MLPST can well capture the spatial and temporal dependencies while requiring only linear computational complexity, as well as model parameters that are more than an order of magnitude lower than baselines. Extensive experiments validated the superior effectiveness and efficiency of MLPST against advanced baselines, and among models with optimal accuracy, MLPST achieves the best time and space efficiency.
A Faster, Lighter and Stronger Deep Learning-Based Approach for Place Recognition
Nov 27, 2022



Visual Place Recognition is an essential component of systems for camera localization and loop closure detection, and it has attracted widespread interest in multiple domains such as computer vision, robotics and AR/VR. In this work, we propose a faster, lighter and stronger approach that can generate models with fewer parameters and can spend less time in the inference stage. We designed RepVGG-lite as the backbone network in our architecture, it is more discriminative than other general networks in the Place Recognition task. RepVGG-lite has more speed advantages while achieving higher performance. We extract only one scale patch-level descriptors from global descriptors in the feature extraction stage. Then we design a trainable feature matcher to exploit both spatial relationships of the features and their visual appearance, which is based on the attention mechanism. Comprehensive experiments on challenging benchmark datasets demonstrate the proposed method outperforming recent other state-of-the-art learned approaches, and achieving even higher inference speed. Our system has 14 times less params than Patch-NetVLAD, 6.8 times lower theoretical FLOPs, and run faster 21 and 33 times in feature extraction and feature matching. Moreover, the performance of our approach is 0.5\% better than Patch-NetVLAD in Recall@1. We used subsets of Mapillary Street Level Sequences dataset to conduct experiments for all other challenging conditions.
EventPoint: Self-Supervised Local Descriptor Learning for Event Cameras
Sep 01, 2021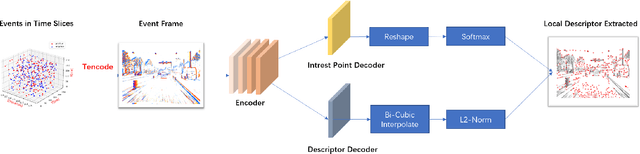

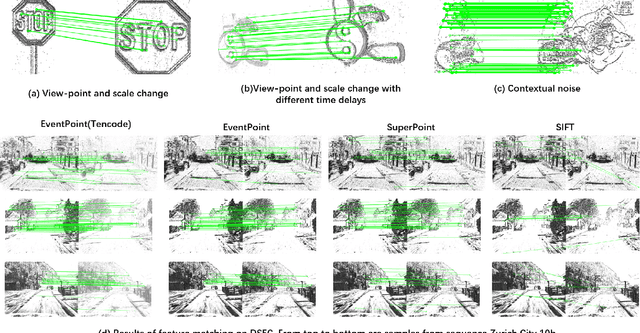
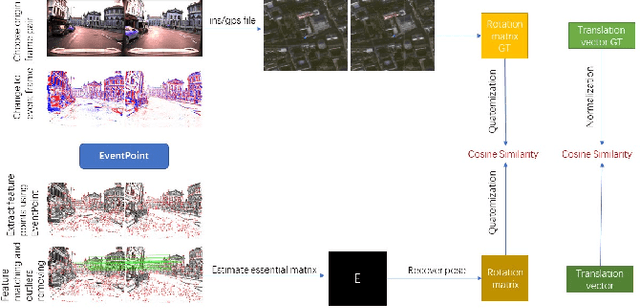
We proposes a method of extracting intrest points and descriptors using self-supervised learning method on frame-based event data, which is called EventPoint. Different from other feature extraction methods on event data, we train our model on real event-form driving dataset--DSEC with the self-supervised learning method we proposed, the training progress fully consider the characteristics of event data.To verify the effectiveness of our work,we conducted several complete evaluations: we emulated DART and carried out feature matching experiments on N-caltech101 dataset, the results shows that the effect of EventPoint is better than DART; We use Vid2e tool provided by UZH to convert Oxford robotcar data into event-based format, and combined with INS information provided to carry out the global pose estimation experiment which is important in SLAM. As far as we know, this is the first work to carry out this challenging task.Sufficient experimental data show that EventPoint can get better results while achieve real time on CPU.
AinnoSeg: Panoramic Segmentation with High Perfomance
Jul 21, 2020
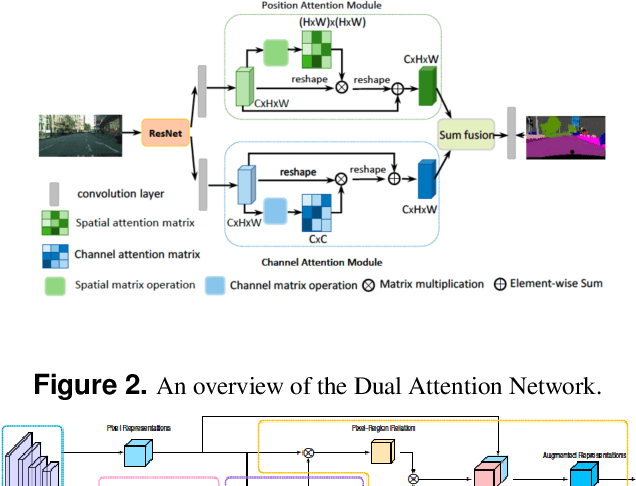
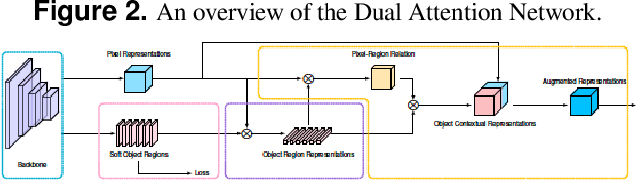

Panoramic segmentation is a scene where image segmentation tasks is more difficult. With the development of CNN networks, panoramic segmentation tasks have been sufficiently developed.However, the current panoramic segmentation algorithms are more concerned with context semantics, but the details of image are not processed enough. Moreover, they cannot solve the problems which contains the accuracy of occluded object segmentation,little object segmentation,boundary pixel in object segmentation etc. Aiming to address these issues, this paper presents some useful tricks. (a) By changing the basic segmentation model, the model can take into account the large objects and the boundary pixel classification of image details. (b) Modify the loss function so that it can take into account the boundary pixels of multiple objects in the image. (c) Use a semi-supervised approach to regain control of the training process. (d) Using multi-scale training and reasoning. All these operations named AinnoSeg, AinnoSeg can achieve state-of-art performance on the well-known dataset ADE20K.