 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending One-Step Image Generation from Class Labels to Text via Discriminative Text Representation
Apr 20, 2026Few-step generation has been a long-standing goal, with recent one-step generation methods exemplified by MeanFlow achieving remarkable results. Existing research on MeanFlow primarily focuses on class-to-image generation. However, an intuitive yet unexplored direction is to extend the condition from fixed class labels to flexible text inputs, enabling richer content creation. Compared to the limited class labels, text conditions pose greater challenges to the model's understanding capability, necessitating the effective integration of powerful text encoders into the MeanFlow framework. Surprisingly, although incorporating text conditions appears straightforward, we find that integrating powerful LLM-based text encoders using conventional training strategies results in unsatisfactory performance. To uncover the underlying cause, we conduct detailed analyses and reveal that, due to the extremely limited number of refinement steps in the MeanFlow generation, such as only one step, the text feature representations are required to possess sufficiently high discriminability. This also explains why discrete and easily distinguishable class features perform well within the MeanFlow framework. Guided by these insights, we leverage a powerful LLM-based text encoder validated to possess the required semantic properties and adapt the MeanFlow generation process to this framework, resulting in efficient text-conditioned synthesis for the first time. Furthermore, we validate our approach on the widely used diffusion model, demonstrating significant generation performance improvements. We hope this work provides a general and practical reference for future research on text-conditioned MeanFlow generation. The code is available at https://github.com/AMAP-ML/EMF.
MAR-GRPO: Stabilized GRPO for AR-diffusion Hybrid Image Generation
Apr 08, 2026Reinforcement learning (RL) has been successfully applied to autoregressive (AR) and diffusion models. However, extending RL to hybrid AR-diffusion frameworks remains challenging due to interleaved inference and noisy log-probability estimation. In this work, we study masked autoregressive models (MAR) and show that the diffusion head plays a critical role in training dynamics, often introducing noisy gradients that lead to instability and early performance saturation. To address this issue, we propose a stabilized RL framework for MAR. We introduce multi-trajectory expectation (MTE), which estimates the optimization direction by averaging over multiple diffusion trajectories, thereby reducing diffusion-induced gradient noise. To avoid over-smoothing, we further estimate token-wise uncertainty from multiple trajectories and apply multi-trajectory optimization only to the top-k% uncertain tokens. In addition, we introduce a consistency-aware token selection strategy that filters out AR tokens that are less aligned with the final generated content. Extensive experiments across multiple benchmarks demonstrate that our method consistently improves visual quality, training stability, and spatial structure understanding over baseline GRPO and pre-RL models. Code is available at: https://github.com/AMAP-ML/mar-grpo.
ConceptWeaver: Weaving Disentangled Concepts with Flow
Mar 30, 2026Pre-trained flow-based models excel at synthesizing complex scenes yet lack a direct mechanism for disentangling and customizing their underlying concepts from one-shot real-world sources. To demystify this process, we first introduce a novel differential probing technique to isolate and analyze the influence of individual concept tokens on the velocity field over time. This investigation yields a critical insight: the generative process is not monolithic but unfolds in three distinct stages. An initial \textbf{Blueprint Stage} establishes low-frequency structure, followed by a pivotal \textbf{Instantiation Stage} where content concepts emerge with peak intensity and become naturally disentangled, creating an optimal window for manipulation. A final concept-insensitive refinement stage then synthesizes fine-grained details. Guided by this discovery, we propose \textbf{ConceptWeaver}, a framework for one-shot concept disentanglement. ConceptWeaver learns concept-specific semantic offsets from a single reference image using a stage-aware optimization strategy that aligns with the three-stage framework. These learned offsets are then deployed during inference via our novel ConceptWeaver Guidance (CWG) mechanism, which strategically injects them at the appropriate generative stage. Extensive experiments validate that ConceptWeaver enables high-fidelity, compositional synthesis and editing, demonstrating that understanding and leveraging the intrinsic, staged nature of flow models is key to unlocking precise, multi-granularity content manipulation.
Omni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
Mar 23, 2026Video--based world models have emerged along two dominant paradigms: video generation and 3D reconstruction. However, existing evaluation benchmarks either focus narrowly on visual fidelity and text--video alignment for generative models, or rely on static 3D reconstruction metrics that fundamentally neglect temporal dynamics. We argue that the future of world modeling lies in 4D generation, which jointly models spatial structure and temporal evolution. In this paradigm, the core capability is interactive response: the ability to faithfully reflect how interaction actions drive state transitions across space and time. Yet no existing benchmark systematically evaluates this critical dimension. To address this gap, we propose Omni--WorldBench, a comprehensive benchmark specifically designed to evaluate the interactive response capabilities of world models in 4D settings. Omni--WorldBench comprises two key components: Omni--WorldSuite, a systematic prompt suite spanning diverse interaction levels and scene types; and Omni--Metrics, an agent-based evaluation framework that quantifies world modeling capabilities by measuring the causal impact of interaction actions on both final outcomes and intermediate state evolution trajectories. We conduct extensive evaluations of 18 representative world models across multiple paradigms. Our analysis reveals critical limitations of current world models in interactive response, providing actionable insights for future research. Omni-WorldBench will be publicly released to foster progress in interactive 4D world modeling.
Artifact-Aware Evaluation for High-Quality Video Generation
Jan 28, 2026With the rapid advancement of video generation techniques, evaluating and auditing generated videos has become increasingly crucial. Existing approaches typically offer coarse video quality scores, lacking detailed localization and categorization of specific artifacts. In this work, we introduce a comprehensive evaluation protocol focusing on three key aspects affecting human perception: Appearance, Motion, and Camera. We define these axes through a taxonomy of 10 prevalent artifact categories reflecting common generative failures observed in video generation. To enable robust artifact detection and categorization, we introduce GenVID, a large-scale dataset of 80k videos generated by various state-of-the-art video generation models, each carefully annotated for the defined artifact categories. Leveraging GenVID, we develop DVAR, a Dense Video Artifact Recognition framework for fine-grained identification and classification of generative artifacts. Extensive experiments show that our approach significantly improves artifact detection accuracy and enables effective filtering of low-quality content.
Ranking-aware Reinforcement Learning for Ordinal Ranking
Jan 28, 2026Ordinal regression and ranking are challenging due to inherent ordinal dependencies that conventional methods struggle to model. We propose Ranking-Aware Reinforcement Learning (RARL), a novel RL framework that explicitly learns these relationships. At its core, RARL features a unified objective that synergistically integrates regression and Learning-to-Rank (L2R), enabling mutual improvement between the two tasks. This is driven by a ranking-aware verifiable reward that jointly assesses regression precision and ranking accuracy, facilitating direct model updates via policy optimization. To further enhance training, we introduce Response Mutation Operations (RMO), which inject controlled noise to improve exploration and prevent stagnation at saddle points. The effectiveness of RARL is validated through extensive experiments on three distinct benchmarks.
Latent Temporal Discrepancy as Motion Prior: A Loss-Weighting Strategy for Dynamic Fidelity in T2V
Jan 28, 2026Video generation models have achieved notable progress in static scenarios, yet their performance in motion video generation remains limited, with quality degrading under drastic dynamic changes. This is due to noise disrupting temporal coherence and increasing the difficulty of learning dynamic regions. {Unfortunately, existing diffusion models rely on static loss for all scenarios, constraining their ability to capture complex dynamics.} To address this issue, we introduce Latent Temporal Discrepancy (LTD) as a motion prior to guide loss weighting. LTD measures frame-to-frame variation in the latent space, assigning larger penalties to regions with higher discrepancy while maintaining regular optimization for stable regions. This motion-aware strategy stabilizes training and enables the model to better reconstruct high-frequency dynamics. Extensive experiments on the general benchmark VBench and the motion-focused VMBench show consistent gains, with our method outperforming strong baselines by 3.31% on VBench and 3.58% on VMBench, achieving significant improvements in motion quality.
Taming Preference Mode Collapse via Directional Decoupling Alignment in Diffusion Reinforcement Learning
Dec 30, 2025Recent studies have demonstrated significant progress in aligning text-to-image diffusion models with human preference via Reinforcement Learning from Human Feedback. However, while existing methods achieve high scores on automated reward metrics, they often lead to Preference Mode Collapse (PMC)-a specific form of reward hacking where models converge on narrow, high-scoring outputs (e.g., images with monolithic styles or pervasive overexposure), severely degrading generative diversity. In this work, we introduce and quantify this phenomenon, proposing DivGenBench, a novel benchmark designed to measure the extent of PMC. We posit that this collapse is driven by over-optimization along the reward model's inherent biases. Building on this analysis, we propose Directional Decoupling Alignment (D$^2$-Align), a novel framework that mitigates PMC by directionally correcting the reward signal. Specifically, our method first learns a directional correction within the reward model's embedding space while keeping the model frozen. This correction is then applied to the reward signal during the optimization process, preventing the model from collapsing into specific modes and thereby maintaining diversity. Our comprehensive evaluation, combining qualitative analysis with quantitative metrics for both quality and diversity, reveals that D$^2$-Align achieves superior alignment with human preference.
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
Dec 30, 2025Multimodal Large Language Models (MLLMs) have made remarkable progress in video understanding. However, they suffer from a critical vulnerability: an over-reliance on language priors, which can lead to visual ungrounded hallucinations, especially when processing counterfactual videos that defy common sense. This limitation, stemming from the intrinsic data imbalance between text and video, is challenging to address due to the substantial cost of collecting and annotating counterfactual data. To address this, we introduce DualityForge, a novel counterfactual data synthesis framework that employs controllable, diffusion-based video editing to transform real-world videos into counterfactual scenarios. By embedding structured contextual information into the video editing and QA generation processes, the framework automatically produces high-quality QA pairs together with original-edited video pairs for contrastive training. Based on this, we build DualityVidQA, a large-scale video dataset designed to reduce MLLM hallucinations. In addition, to fully exploit the contrastive nature of our paired data, we propose Duality-Normalized Advantage Training (DNA-Train), a two-stage SFT-RL training regime where the RL phase applies pair-wise $\ell_1$ advantage normalization, thereby enabling a more stable and efficient policy optimization. Experiments on DualityVidQA-Test demonstrate that our method substantially reduces model hallucinations on counterfactual videos, yielding a relative improvement of 24.0% over the Qwen2.5-VL-7B baseline. Moreover, our approach achieves significant gains across both hallucination and general-purpose benchmarks, indicating strong generalization capability. We will open-source our dataset and code.
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Dec 20, 2025


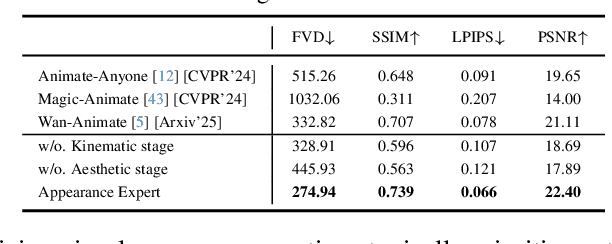
With the rise of online dance-video platforms and rapid advances in AI-generated content (AIGC), music-driven dance generation has emerged as a compelling research direction. Despite substantial progress in related domains such as music-driven 3D dance generation, pose-driven image animation, and audio-driven talking-head synthesis, existing methods cannot be directly adapted to this task. Moreover, the limited studies in this area still struggle to jointly achieve high-quality visual appearance and realistic human motion. Accordingly, we present MACE-Dance, a music-driven dance video generation framework with cascaded Mixture-of-Experts (MoE). The Motion Expert performs music-to-3D motion generation while enforcing kinematic plausibility and artistic expressiveness, whereas the Appearance Expert carries out motion- and reference-conditioned video synthesis, preserving visual identity with spatiotemporal coherence. Specifically, the Motion Expert adopts a diffusion model with a BiMamba-Transformer hybrid architecture and a Guidance-Free Training (GFT) strategy, achieving state-of-the-art (SOTA) performance in 3D dance generation. The Appearance Expert employs a decoupled kinematic-aesthetic fine-tuning strategy, achieving state-of-the-art (SOTA) performance in pose-driven image animation. To better benchmark this task, we curate a large-scale and diverse dataset and design a motion-appearance evaluation protocol. Based on this protocol, MACE-Dance also achieves state-of-the-art performance. Project page: https://macedance.github.io/