 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Instance Segmentation
Apr 14, 2021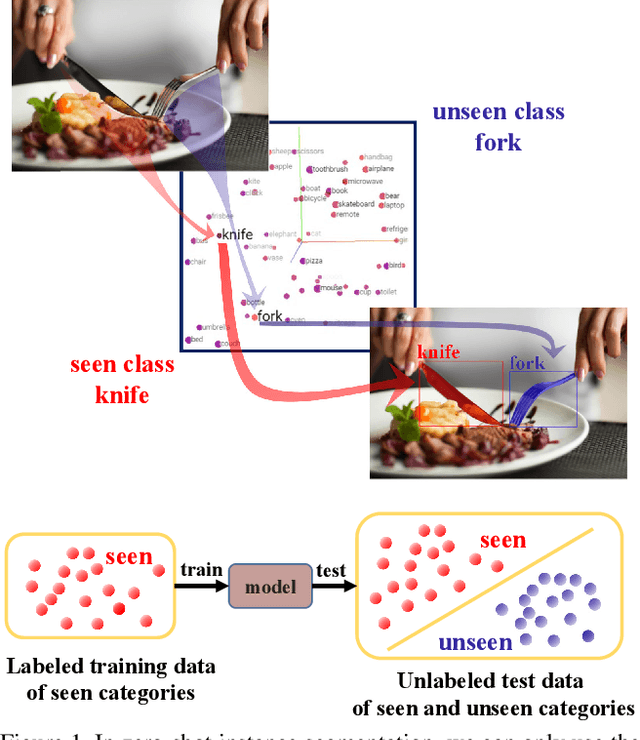
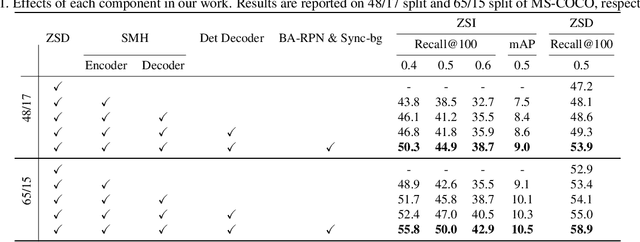
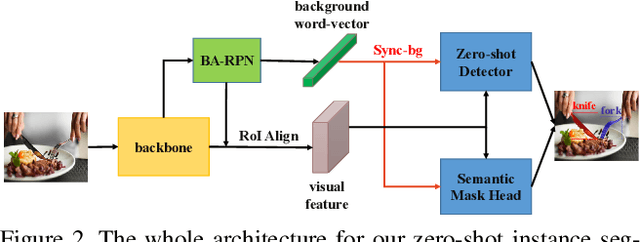
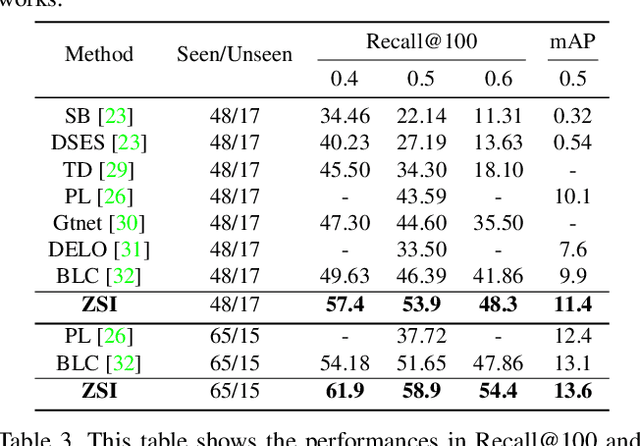
Deep learning has significantly improved the precision of instance segmentation with abundant labeled data. However, in many areas like medical and manufacturing, collecting sufficient data is extremely hard and labeling this data requires high professional skills. We follow this motivation and propose a new task set named zero-shot instance segmentation (ZSI). In the training phase of ZSI, the model is trained with seen data, while in the testing phase, it is used to segment all seen and unseen instances. We first formulate the ZSI task and propose a method to tackle the challenge, which consists of Zero-shot Detector, Semantic Mask Head, Background Aware RPN and Synchronized Background Strategy. We present a new benchmark for zero-shot instance segmentation based on the MS-COCO dataset. The extensive empirical results in this benchmark show that our method not only surpasses the state-of-the-art results in zero-shot object detection task but also achieves promising performance on ZSI. Our approach will serve as a solid baseline and facilitate future research in zero-shot instance segmentation.
BiOpt: Bi-Level Optimization for Few-Shot Segmentation
Nov 23, 2020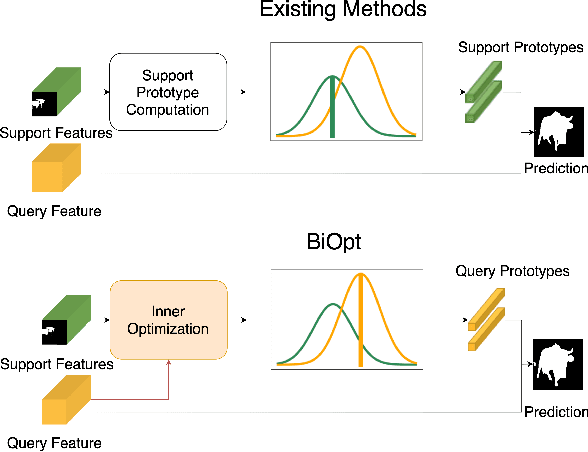
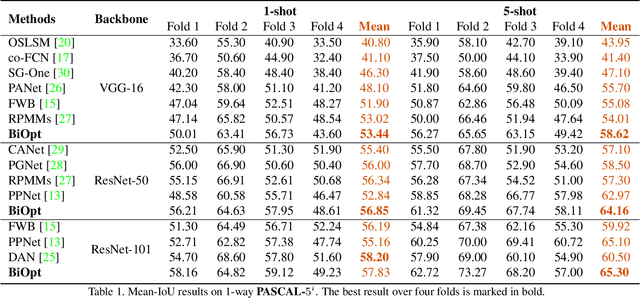

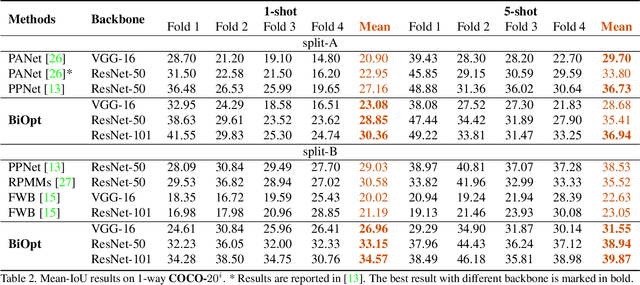
Few-shot segmentation is a challenging task that aims to segment objects of new classes given scarce support images. In the inductive setting, existing prototype-based methods focus on extracting prototypes from the support images; however, they fail to utilize semantic information of the query images. In this paper, we propose Bi-level Optimization (BiOpt), which succeeds to compute class prototypes from the query images under inductive setting. The learning procedure of BiOpt is decomposed into two nested loops: inner and outer loop. On each task, the inner loop aims to learn optimized prototypes from the query images. An init step is conducted to fully exploit knowledge from both support and query features, so as to give reasonable initialized prototypes into the inner loop. The outer loop aims to learn a discriminative embedding space across different tasks. Extensive experiments on two benchmarks verify the superiority of our proposed BiOpt algorithm. In particular, we consistently achieve the state-of-the-art performance on 5-shot PASCAL-$5^i$ and 1-shot COCO-$20^i$.
Prototype Refinement Network for Few-Shot Segmentation
Feb 10, 2020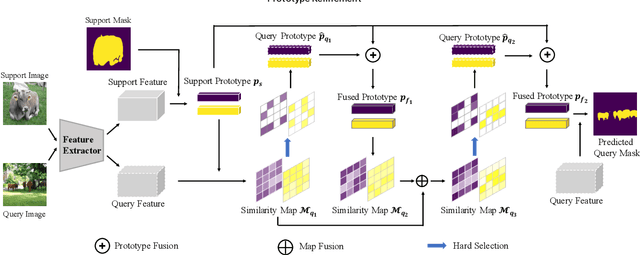
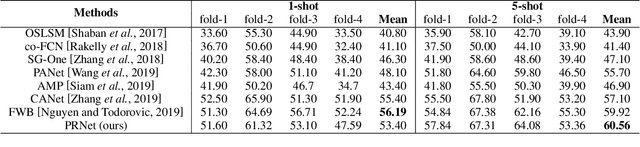

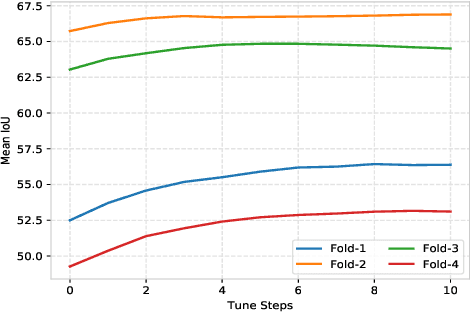
Few-shot segmentation targets to segment new classes with few annotated images provided. It is more challenging than traditional semantic segmentation tasks that segment pre-defined classes with abundant annotated data. In this paper, we propose Prototype Refinement Network (PRNet) to attack the challenge of few-shot segmentation. PRNet learns to bidirectionally extract prototypes from both support and query images, which is different from existing methods. To extract representative prototypes of the new classes, we use adaptation and fusion for prototype refinement. The adaptation of PRNet is implemented by fine-tuning on the support set. Furthermore, prototype fusion is adopted to fuse support prototypes with query prototypes, incorporating the knowledge from both sides. Refined in this way, the prototypes become more discriminative in low-data regimes. Experiments on PASAL-$5^i$ and COCO-$20^i$ demonstrate the superiority of our method. Especially on COCO-$20^i$, PRNet significantly outperforms previous methods by a large margin of 13.1% in 1-shot setting and 17.4% in 5-shot setting respectively.
Fast and Generalized Adaptation for Few-Shot Learning
Nov 25, 2019
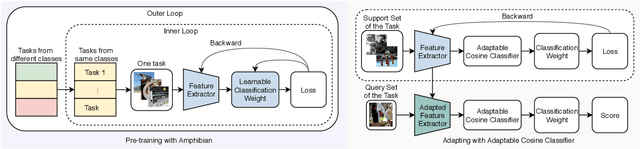
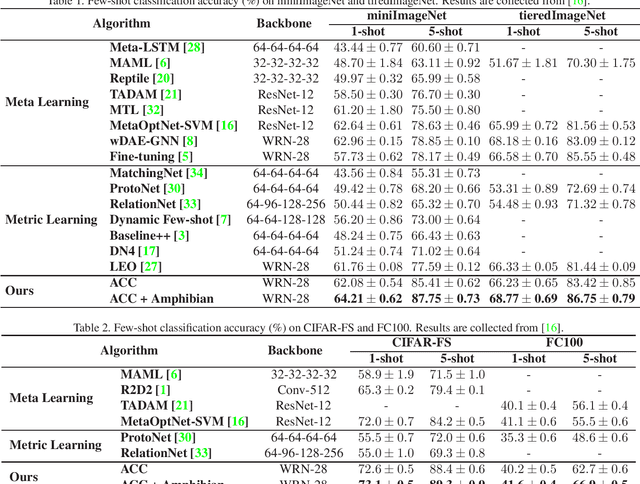
The ability of fast generalizing to novel tasks from a few examples is critical in dealing with few-shot learning problems. However, deep learning models severely suffer from overfitting in extreme low data regime. In this paper, we propose Adaptable Cosine Classifier (ACC) and Amphibian to achieve fast and generalized adaptation for few-shot learning. The ACC realizes the flexible retraining of a deep network on small data without overfitting. The Amphibian learns a good weight initialization in the parameter space where optimal solutions for the tasks of the same class cluster tightly. It enables rapid adaptation to novel tasks with few gradient updates. We conduct comprehensive experiments on four few-shot datasets and achieve state-of-the-art performance in all cases. Notably, we achieve the accuracy of 87.75% on 5-shot miniImageNet which approximately outperforms existing methods by 10%. We also conduct experiment on cross-domain few-shot tasks and provide the best results.
Prototype Rectification for Few-Shot Learning
Nov 25, 2019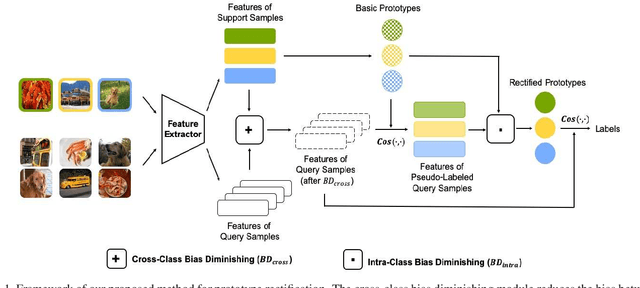
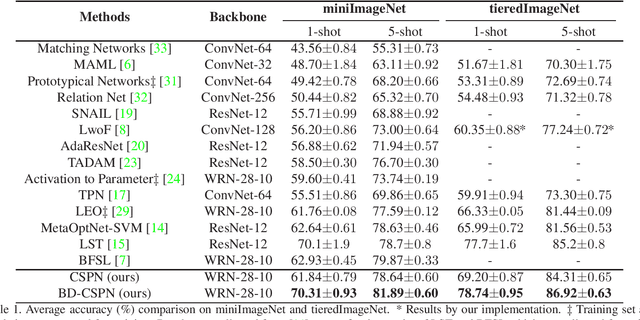

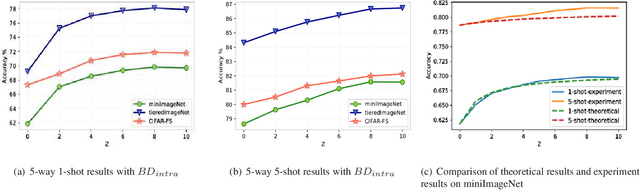
Few-shot learning is a challenging problem that requires a model to recognize novel classes with few labeled data. In this paper, we aim to find the expected prototypes of the novel classes, which have the maximum cosine similarity with the samples of the same class. Firstly, we propose a cosine similarity based prototypical network to compute basic prototypes of the novel classes from the few samples. A bias diminishing module is further proposed for prototype rectification since the basic prototypes computed in the low-data regime are biased against the expected prototypes. In our method, the intra-class bias and the cross-class bias are diminished to modify the prototypes. Then we give a theoretical analysis of the impact of the bias diminishing module on the expected performance of our method. We conduct extensive experiments on four few-shot benchmarks and further analyze the advantage of the bias diminishing module. The bias diminishing module brings in significant improvement by a large margin of 3% to 9% in general. Notably, our approach achieves state-of-the-art performance on miniImageNet (70.31% in 1-shot and 81.89% in 5-shot) and tieredImageNet (78.74% in 1-shot and 86.92% in 5-shot), which demonstrates the superiority of the proposed method.
Accurate Face Detection for High Performance
May 24, 2019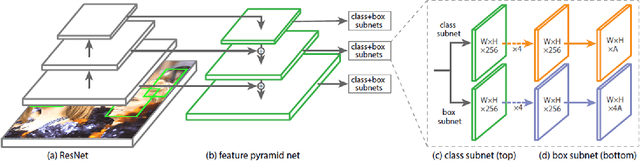

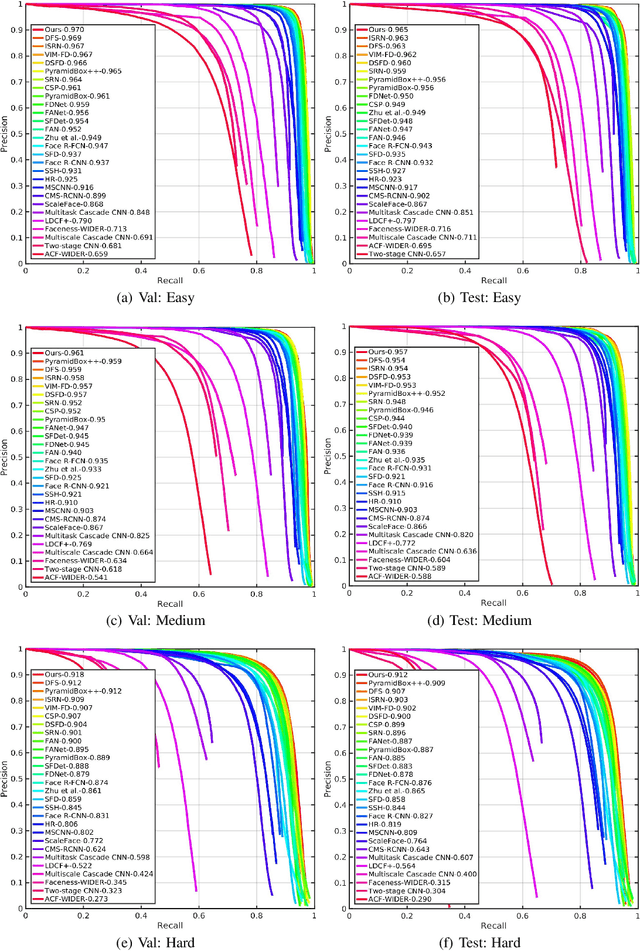
Face detection has witnessed significant progress due to the advances of deep convolutional neural networks (CNNs). Its central issue in recent years is how to improve the detection performance of tiny faces. To this end, many recent works propose some specific strategies, redesign the architecture and introduce new loss functions for tiny object detection. In this report, we start from the popular one-stage RetinaNet approach and apply some recent tricks to obtain a high performance face detector. Specifically, we apply the Intersection over Union (IoU) loss function for regression, employ the two-step classification and regression for detection, revisit the data augmentation based on data-anchor-sampling for training, utilize the max-out operation for classification and use the multi-scale testing strategy for inference. As a consequence, the proposed face detection method achieves state-of-the-art performance on the most popular and challenging face detection benchmark WIDER FACE dataset.