 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-cost Parallel Transmission for Dense Indoor Data Collection with LoRaWAN: Time Synchronization and Resource Allocation
May 22, 2026LoRaWAN is a compelling low-cost solution for large-scale indoor Internet of Things (IoT) data backhaul, owing to its strong penetration capability and low power consumption. However, its default pure ALOHA access mechanism leads to severe channel contention, substantial packet loss, and reduced throughput under dense, concurrent transmissions. To overcome this, we propose a lightweight out-of-band (OOB) synchronization scheme that integrates a time division multiple access (TDMA) mechanism into commercial LoRaWAN Class~A networks. Unlike approaches requiring gateway scheduling, frequent downlink signaling, or custom hardware, our method introduces a single low-cost node providing millisecond-level alignment via a dedicated OOB synchronization channel. End devices seamlessly access this channel by briefly retuning their existing LoRa transceivers. Consequently, the scheme imposes zero downlink overhead during the steady-state reporting phase, requires no hardware modifications to gateways or end devices, and remains fully backward-compatible. This design enables collision-free scheduled channel access within the configured nominal resource capacity, thereby improving throughput and reducing contention. Real-world experiments using an indoor positioning prototype demonstrate that the proposed TDMA-LoRaWAN architecture improves system throughput by over 30\% and reduces the packet loss rate from 25.8\% to 5.02\% in a 20-node indoor deployment. Furthermore, large-scale simulations corroborate these empirical findings, support the scalability analysis under larger network sizes, and indicate improved energy efficiency per successful packet in dense network settings. These combined results demonstrate the effectiveness of the proposed approach for dense indoor IoT data collection and indicate its practical potential under high uplink reporting demands.
Empathetic Motion Generation for Humanoid Educational Robots via Reasoning-Guided Vision--Language--Motion Diffusion Architecture
Mar 19, 2026This article suggests a reasoning-guided vision-language-motion diffusion framework (RG-VLMD) for generating instruction-aware co-speech gestures for humanoid robots in educational scenarios. The system integrates multi-modal affective estimation, pedagogical reasoning, and teaching-act-conditioned motion synthesis to enable adaptive and semantically consistent robot behavior. A gated mixture-of-experts model predicts Valence/Arousal from input text, visual, and acoustic features, which then mapped to discrete teaching-act categories through an affect-driven policy.These signals condition a diffusion-based motion generator using clip-level intent and frame-level instructional schedules via additive latent restriction with auxiliary action-group supervision. Compared to a baseline diffusion model, our proposed method produces more structured and distinctive motion patterns, as verified by motion statics and pairwise distance analysis. Generated motion sequences remain physically plausible and can be retargeted to a NAO robot for real-time execution. The results reveal that reasoning-guided instructional conditioning improves gesture controllability and pedagogical expressiveness in educational human-robot interaction.
Unsupervised Cross-Domain 3D Human Pose Estimation via Pseudo-Label-Guided Global Transforms
Apr 17, 2025Existing 3D human pose estimation methods often suffer in performance, when applied to cross-scenario inference, due to domain shifts in characteristics such as camera viewpoint, position, posture, and body size. Among these factors, camera viewpoints and locations {have been shown} to contribute significantly to the domain gap by influencing the global positions of human poses. To address this, we propose a novel framework that explicitly conducts global transformations between pose positions in the camera coordinate systems of source and target domains. We start with a Pseudo-Label Generation Module that is applied to the 2D poses of the target dataset to generate pseudo-3D poses. Then, a Global Transformation Module leverages a human-centered coordinate system as a novel bridging mechanism to seamlessly align the positional orientations of poses across disparate domains, ensuring consistent spatial referencing. To further enhance generalization, a Pose Augmentor is incorporated to address variations in human posture and body size. This process is iterative, allowing refined pseudo-labels to progressively improve guidance for domain adaptation. Our method is evaluated on various cross-dataset benchmarks, including Human3.6M, MPI-INF-3DHP, and 3DPW. The proposed method outperforms state-of-the-art approaches and even outperforms the target-trained model.
Dynamic Connected Neural Decision Classifier and Regressor with Dynamic Softing Pruning
Nov 20, 2019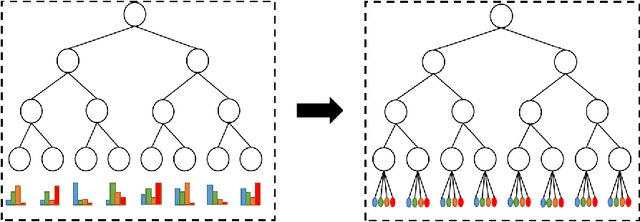
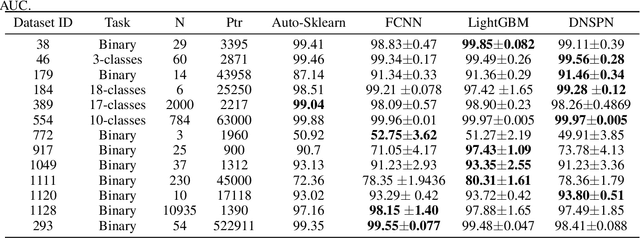
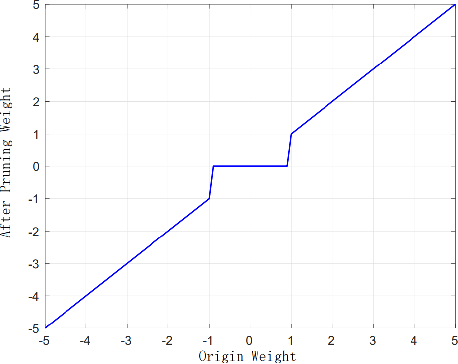
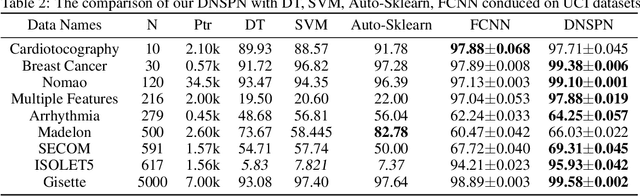
To deal with datasets of different complexity, this paper presents an efficient learning model that combines the proposed Dynamic Connected Neural Decision Networks (DNDN) and a new pruning method--Dynamic Soft Pruning (DSP). DNDN is a combination of random forests and deep neural networks thereby it enjoys both the properties of powerful classification capability and representation learning functionality. Different from Deep Neural Decision Forests (DNDF), this paper adopts an end-to-end training approach by representing the classification distribution with multiple randomly initialized softmax layers, which enables the placement of the forest trees after each layer in the neural network and greatly improves the training speed and stability. Furthermore, DSP is proposed to reduce the redundant connections of the network in a soft fashion which has high flexibility but demonstrates no performance loss compared with previous approaches. Extensive experiments on different datasets demonstrate the superiority of the proposed model over other popular algorithms in solving classification tasks.
Regression via Arbitrary Quantile Modeling
Nov 13, 2019
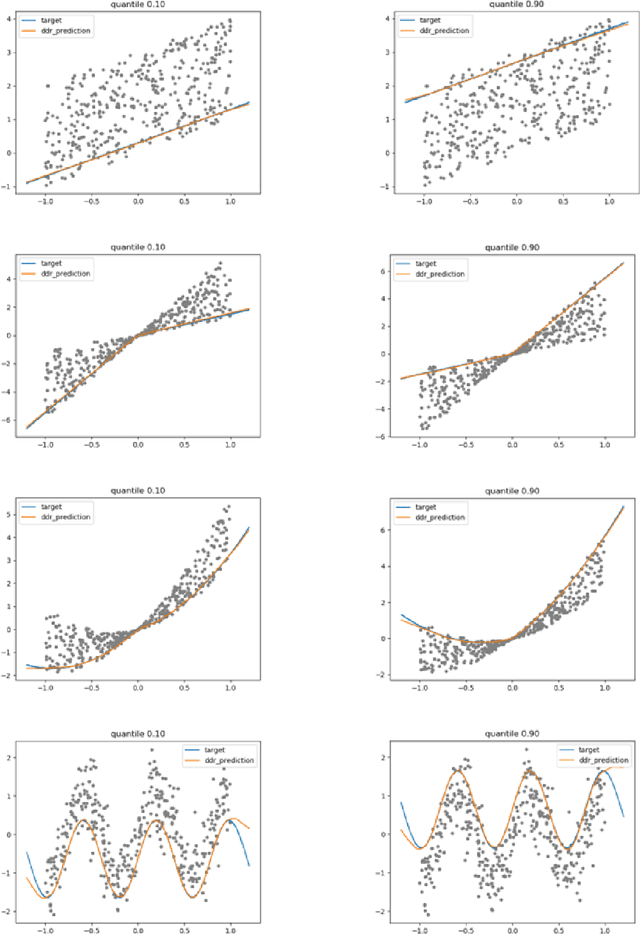

In the regression problem, L1 and L2 are the most commonly used loss functions, which produce mean predictions with different biases. However, the predictions are neither robust nor adequate enough since they only capture a few conditional distributions instead of the whole distribution, especially for small datasets. To address this problem, we proposed arbitrary quantile modeling to regulate the prediction, which achieved better performance compared to traditional loss functions. More specifically, a new distribution regression method, Deep Distribution Regression (DDR), is proposed to estimate arbitrary quantiles of the response variable. Our DDR method consists of two models: a Q model, which predicts the corresponding value for arbitrary quantile, and an F model, which predicts the corresponding quantile for arbitrary value. Furthermore, the duality between Q and F models enables us to design a novel loss function for joint training and perform a dual inference mechanism. Our experiments demonstrate that our DDR-joint and DDR-disjoint methods outperform previous methods such as AdaBoost, random forest, LightGBM, and neural networks both in terms of mean and quantile prediction.
Accurate Face Detection for High Performance
May 24, 2019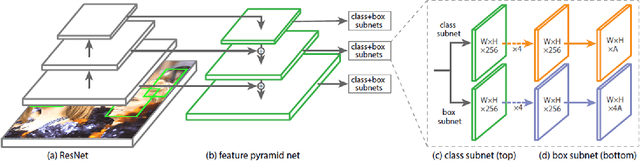

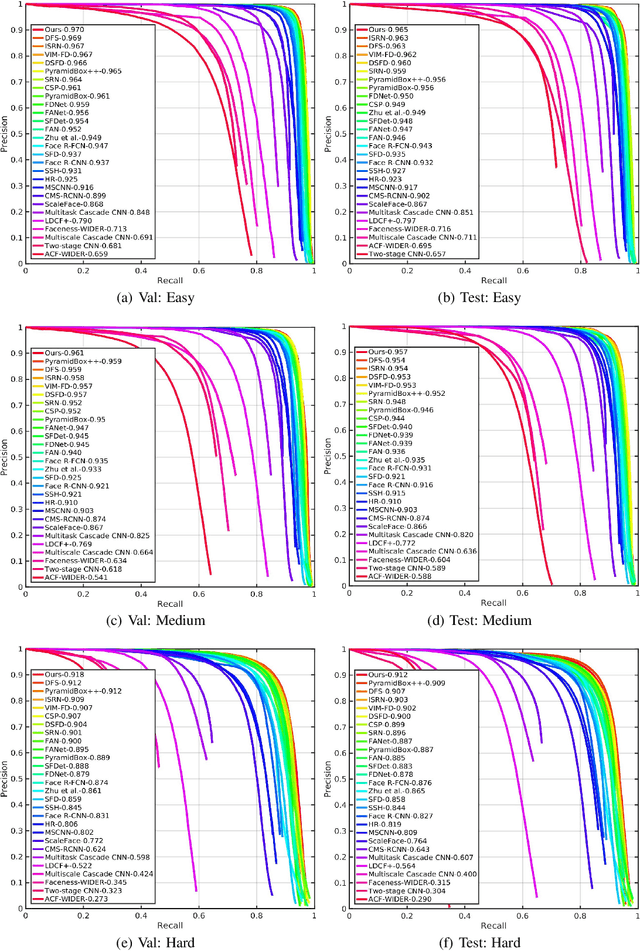
Face detection has witnessed significant progress due to the advances of deep convolutional neural networks (CNNs). Its central issue in recent years is how to improve the detection performance of tiny faces. To this end, many recent works propose some specific strategies, redesign the architecture and introduce new loss functions for tiny object detection. In this report, we start from the popular one-stage RetinaNet approach and apply some recent tricks to obtain a high performance face detector. Specifically, we apply the Intersection over Union (IoU) loss function for regression, employ the two-step classification and regression for detection, revisit the data augmentation based on data-anchor-sampling for training, utilize the max-out operation for classification and use the multi-scale testing strategy for inference. As a consequence, the proposed face detection method achieves state-of-the-art performance on the most popular and challenging face detection benchmark WIDER FACE dataset.