 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025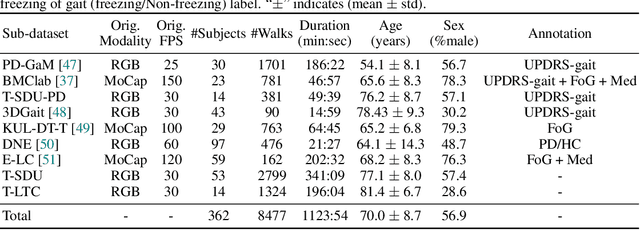
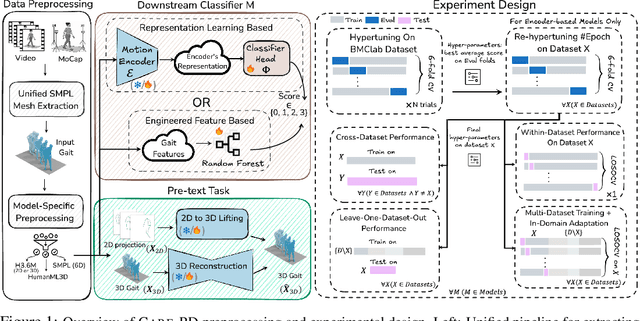
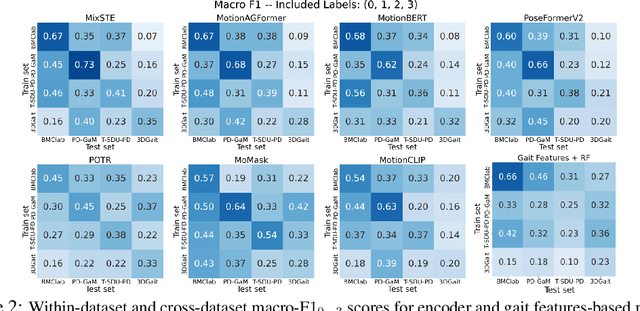
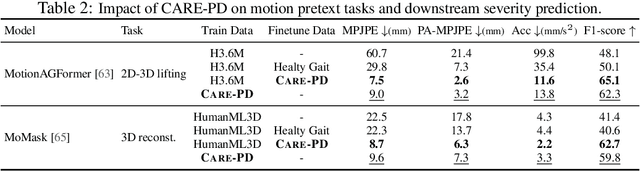
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
Unsupervised Cross-Domain 3D Human Pose Estimation via Pseudo-Label-Guided Global Transforms
Apr 17, 2025Existing 3D human pose estimation methods often suffer in performance, when applied to cross-scenario inference, due to domain shifts in characteristics such as camera viewpoint, position, posture, and body size. Among these factors, camera viewpoints and locations {have been shown} to contribute significantly to the domain gap by influencing the global positions of human poses. To address this, we propose a novel framework that explicitly conducts global transformations between pose positions in the camera coordinate systems of source and target domains. We start with a Pseudo-Label Generation Module that is applied to the 2D poses of the target dataset to generate pseudo-3D poses. Then, a Global Transformation Module leverages a human-centered coordinate system as a novel bridging mechanism to seamlessly align the positional orientations of poses across disparate domains, ensuring consistent spatial referencing. To further enhance generalization, a Pose Augmentor is incorporated to address variations in human posture and body size. This process is iterative, allowing refined pseudo-labels to progressively improve guidance for domain adaptation. Our method is evaluated on various cross-dataset benchmarks, including Human3.6M, MPI-INF-3DHP, and 3DPW. The proposed method outperforms state-of-the-art approaches and even outperforms the target-trained model.
Trajectory-guided Motion Perception for Facial Expression Quality Assessment in Neurological Disorders
Apr 16, 2025Automated facial expression quality assessment (FEQA) in neurological disorders is critical for enhancing diagnostic accuracy and improving patient care, yet effectively capturing the subtle motions and nuances of facial muscle movements remains a challenge. We propose to analyse facial landmark trajectories, a compact yet informative representation, that encodes these subtle motions from a high-level structural perspective. Hence, we introduce Trajectory-guided Motion Perception Transformer (TraMP-Former), a novel FEQA framework that fuses landmark trajectory features for fine-grained motion capture with visual semantic cues from RGB frames, ultimately regressing the combined features into a quality score. Extensive experiments demonstrate that TraMP-Former achieves new state-of-the-art performance on benchmark datasets with neurological disorders, including PFED5 (up by 6.51%) and an augmented Toronto NeuroFace (up by 7.62%). Our ablation studies further validate the efficiency and effectiveness of landmark trajectories in FEQA. Our code is available at https://github.com/shuchaoduan/TraMP-Former.
Co-STAR: Collaborative Curriculum Self-Training with Adaptive Regularization for Source-Free Video Domain Adaptation
Apr 15, 2025Recent advances in Source-Free Unsupervised Video Domain Adaptation (SFUVDA) leverage vision-language models to enhance pseudo-label generation. However, challenges such as noisy pseudo-labels and over-confident predictions limit their effectiveness in adapting well across domains. We propose Co-STAR, a novel framework that integrates curriculum learning with collaborative self-training between a source-trained teacher and a contrastive vision-language model (CLIP). Our curriculum learning approach employs a reliability-based weight function that measures bidirectional prediction alignment between the teacher and CLIP, balancing between confident and uncertain predictions. This function preserves uncertainty for difficult samples, while prioritizing reliable pseudo-labels when the predictions from both models closely align. To further improve adaptation, we propose Adaptive Curriculum Regularization, which modifies the learning priority of samples in a probabilistic, adaptive manner based on their confidence scores and prediction stability, mitigating overfitting to noisy and over-confident samples. Extensive experiments across multiple video domain adaptation benchmarks demonstrate that Co-STAR consistently outperforms state-of-the-art SFUVDA methods. Code is available at: https://github.com/Plrbear/Co-Star
GAITGen: Disentangled Motion-Pathology Impaired Gait Generative Model -- Bringing Motion Generation to the Clinical Domain
Mar 28, 2025Gait analysis is crucial for the diagnosis and monitoring of movement disorders like Parkinson's Disease. While computer vision models have shown potential for objectively evaluating parkinsonian gait, their effectiveness is limited by scarce clinical datasets and the challenge of collecting large and well-labelled data, impacting model accuracy and risk of bias. To address these gaps, we propose GAITGen, a novel framework that generates realistic gait sequences conditioned on specified pathology severity levels. GAITGen employs a Conditional Residual Vector Quantized Variational Autoencoder to learn disentangled representations of motion dynamics and pathology-specific factors, coupled with Mask and Residual Transformers for conditioned sequence generation. GAITGen generates realistic, diverse gait sequences across severity levels, enriching datasets and enabling large-scale model training in parkinsonian gait analysis. Experiments on our new PD-GaM (real) dataset demonstrate that GAITGen outperforms adapted state-of-the-art models in both reconstruction fidelity and generation quality, accurately capturing critical pathology-specific gait features. A clinical user study confirms the realism and clinical relevance of our generated sequences. Moreover, incorporating GAITGen-generated data into downstream tasks improves parkinsonian gait severity estimation, highlighting its potential for advancing clinical gait analysis.
SEA: State-Exchange Attention for High-Fidelity Physics-Based Transformers
Oct 20, 2024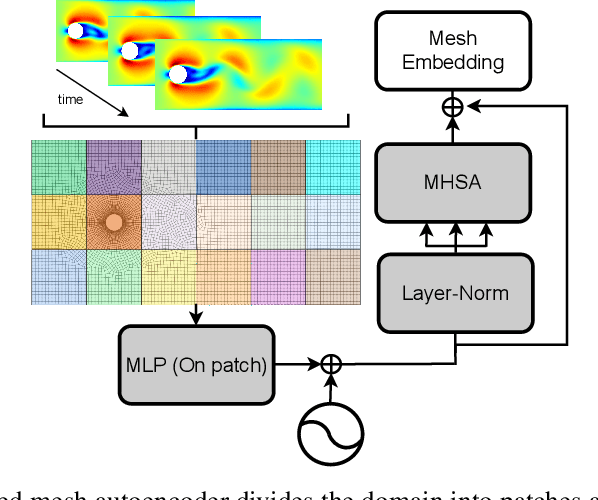

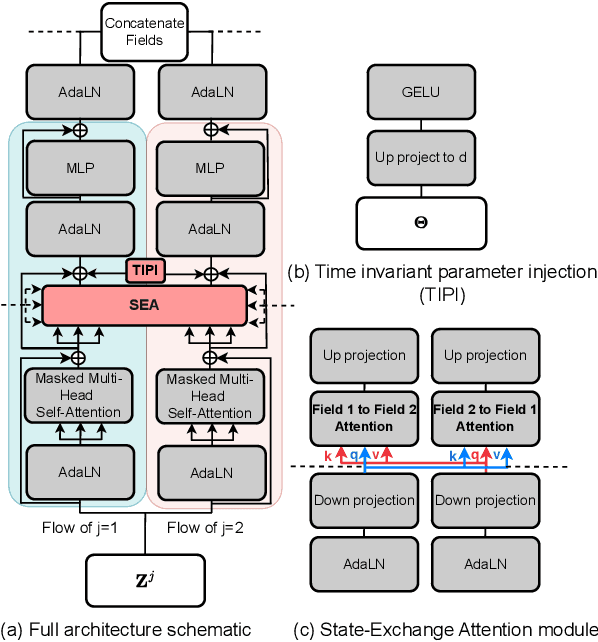

Current approaches using sequential networks have shown promise in estimating field variables for dynamical systems, but they are often limited by high rollout errors. The unresolved issue of rollout error accumulation results in unreliable estimations as the network predicts further into the future, with each step's error compounding and leading to an increase in inaccuracy. Here, we introduce the State-Exchange Attention (SEA) module, a novel transformer-based module enabling information exchange between encoded fields through multi-head cross-attention. The cross-field multidirectional information exchange design enables all state variables in the system to exchange information with one another, capturing physical relationships and symmetries between fields. In addition, we incorporate a ViT-like architecture to generate spatially coherent mesh embeddings, further improving the model's ability to capture spatial dependencies in the data. This enhances the model's ability to represent complex interactions between the field variables, resulting in improved rollout error accumulation. Our results show that the Transformer model integrated with the State-Exchange Attention (SEA) module outperforms competitive baseline models, including the PbGMR-GMUS Transformer-RealNVP and GMR-GMUS Transformer, with a reduction in error of 88\% and 91\%, respectively, achieving state-of-the-art performance. Furthermore, we demonstrate that the SEA module alone can reduce errors by 97\% for state variables that are highly dependent on other states of the system.
QAFE-Net: Quality Assessment of Facial Expressions with Landmark Heatmaps
Dec 01, 2023Facial expression recognition (FER) methods have made great inroads in categorising moods and feelings in humans. Beyond FER, pain estimation methods assess levels of intensity in pain expressions, however assessing the quality of all facial expressions is of critical value in health-related applications. In this work, we address the quality of five different facial expressions in patients affected by Parkinson's disease. We propose a novel landmark-guided approach, QAFE-Net, that combines temporal landmark heatmaps with RGB data to capture small facial muscle movements that are encoded and mapped to severity scores. The proposed approach is evaluated on a new Parkinson's Disease Facial Expression dataset (PFED5), as well as on the pain estimation benchmark, the UNBC-McMaster Shoulder Pain Expression Archive Database. Our comparative experiments demonstrate that the proposed method outperforms SOTA action quality assessment works on PFED5 and achieves lower mean absolute error than the SOTA pain estimation methods on UNBC-McMaster. Our code and the new PFED5 dataset are available at https://github.com/shuchaoduan/QAFE-Net.
PECoP: Parameter Efficient Continual Pretraining for Action Quality Assessment
Nov 11, 2023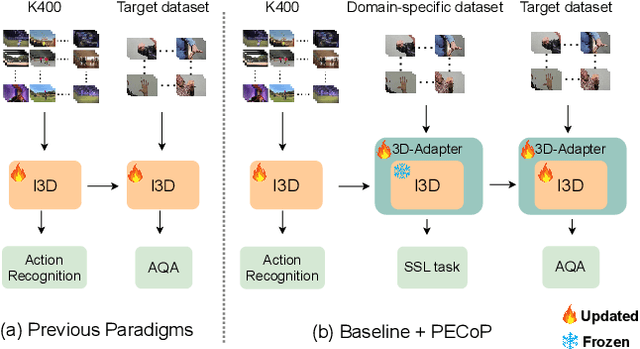
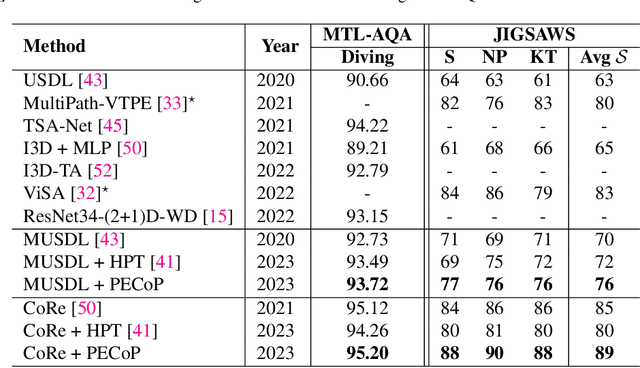
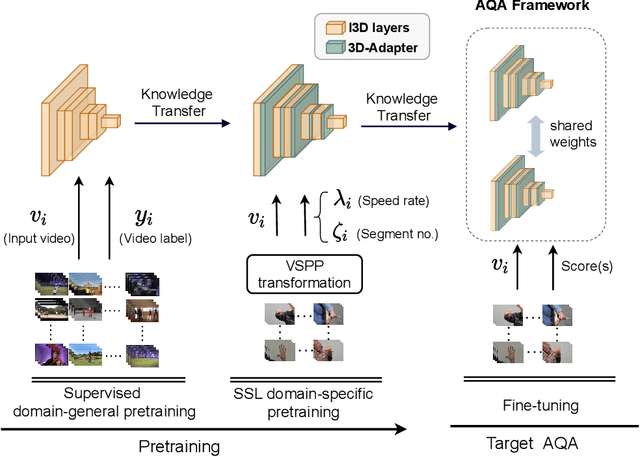

The limited availability of labelled data in Action Quality Assessment (AQA), has forced previous works to fine-tune their models pretrained on large-scale domain-general datasets. This common approach results in weak generalisation, particularly when there is a significant domain shift. We propose a novel, parameter efficient, continual pretraining framework, PECoP, to reduce such domain shift via an additional pretraining stage. In PECoP, we introduce 3D-Adapters, inserted into the pretrained model, to learn spatiotemporal, in-domain information via self-supervised learning where only the adapter modules' parameters are updated. We demonstrate PECoP's ability to enhance the performance of recent state-of-the-art methods (MUSDL, CoRe, and TSA) applied to AQA, leading to considerable improvements on benchmark datasets, JIGSAWS ($\uparrow6.0\%$), MTL-AQA ($\uparrow0.99\%$), and FineDiving ($\uparrow2.54\%$). We also present a new Parkinson's Disease dataset, PD4T, of real patients performing four various actions, where we surpass ($\uparrow3.56\%$) the state-of-the-art in comparison. Our code, pretrained models, and the PD4T dataset are available at https://github.com/Plrbear/PECoP.
Auxiliary Learning for Self-Supervised Video Representation via Similarity-based Knowledge Distillation
Dec 07, 2021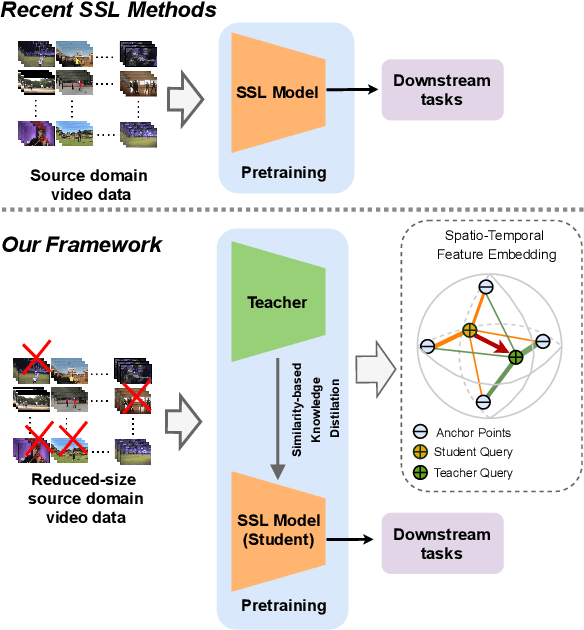
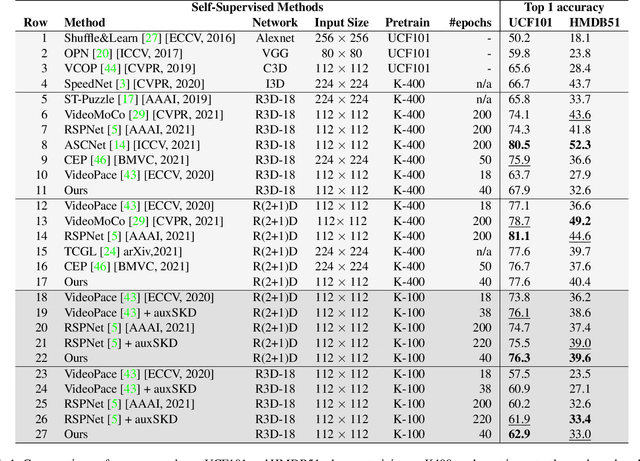
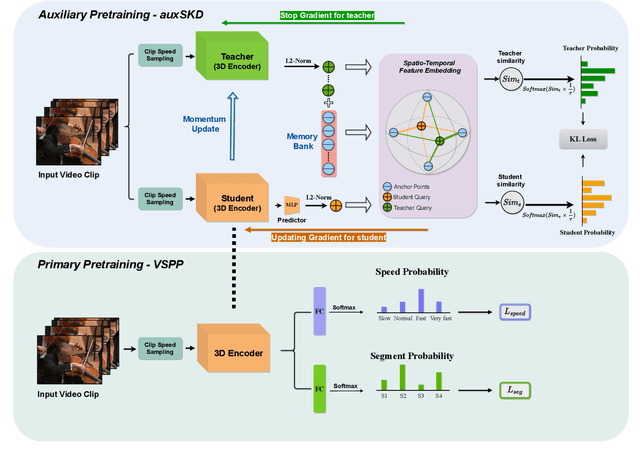
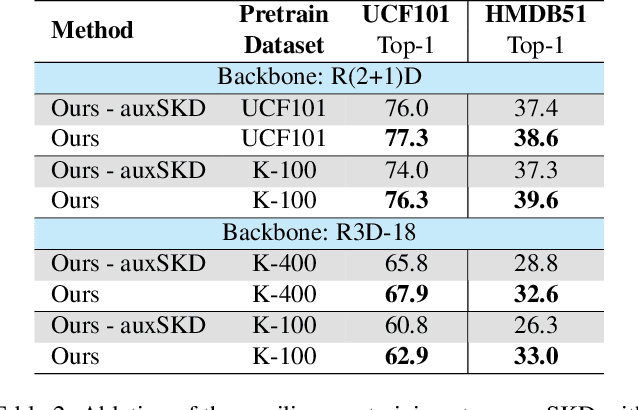
Despite the outstanding success of self-supervised pretraining methods for video representation learning, they generalise poorly when the unlabeled dataset for pretraining is small or the domain difference between unlabelled data in source task (pretraining) and labeled data in target task (finetuning) is significant. To mitigate these issues, we propose a novel approach to complement self-supervised pretraining via an auxiliary pretraining phase, based on knowledge similarity distillation, auxSKD, for better generalisation with a significantly smaller amount of video data, e.g. Kinetics-100 rather than Kinetics-400. Our method deploys a teacher network that iteratively distils its knowledge to the student model by capturing the similarity information between segments of unlabelled video data. The student model then solves a pretext task by exploiting this prior knowledge. We also introduce a novel pretext task, Video Segment Pace Prediction or VSPP, which requires our model to predict the playback speed of a randomly selected segment of the input video to provide more reliable self-supervised representations. Our experimental results show superior results to the state of the art on both UCF101 and HMDB51 datasets when pretraining on K100. Additionally, we show that our auxiliary pertaining, auxSKD, when added as an extra pretraining phase to recent state of the art self-supervised methods (e.g. VideoPace and RSPNet), improves their results on UCF101 and HMDB51. Our code will be released soon.
Exploring Motion Boundaries in an End-to-End Network for Vision-based Parkinson's Severity Assessment
Dec 24, 2020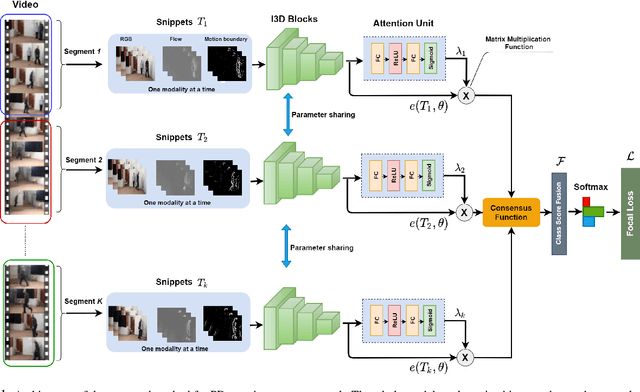
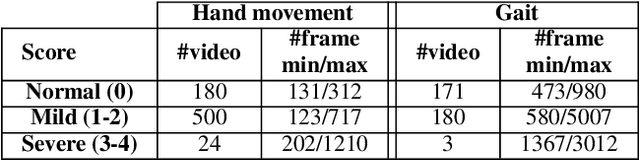
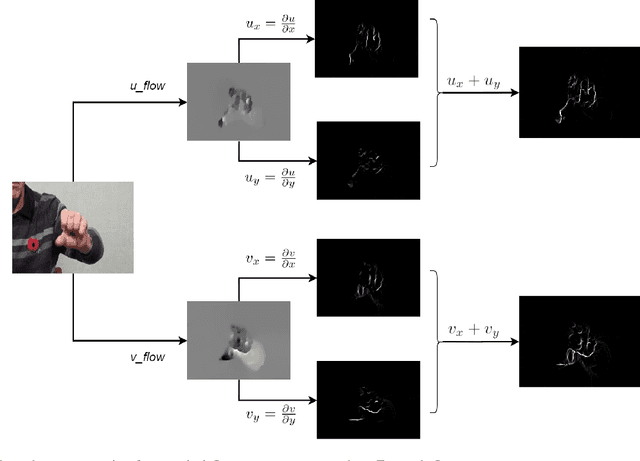
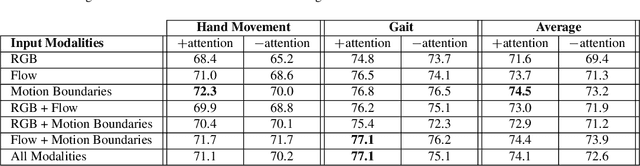
Evaluating neurological disorders such as Parkinson's disease (PD) is a challenging task that requires the assessment of several motor and non-motor functions. In this paper, we present an end-to-end deep learning framework to measure PD severity in two important components, hand movement and gait, of the Unified Parkinson's Disease Rating Scale (UPDRS). Our method leverages on an Inflated 3D CNN trained by a temporal segment framework to learn spatial and long temporal structure in video data. We also deploy a temporal attention mechanism to boost the performance of our model. Further, motion boundaries are explored as an extra input modality to assist in obfuscating the effects of camera motion for better movement assessment. We ablate the effects of different data modalities on the accuracy of the proposed network and compare with other popular architectures. We evaluate our proposed method on a dataset of 25 PD patients, obtaining 72.3% and 77.1% top-1 accuracy on hand movement and gait tasks respectively.