 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Learning for Self-Supervised Video Representation via Similarity-based Knowledge Distillation
Paper and Code
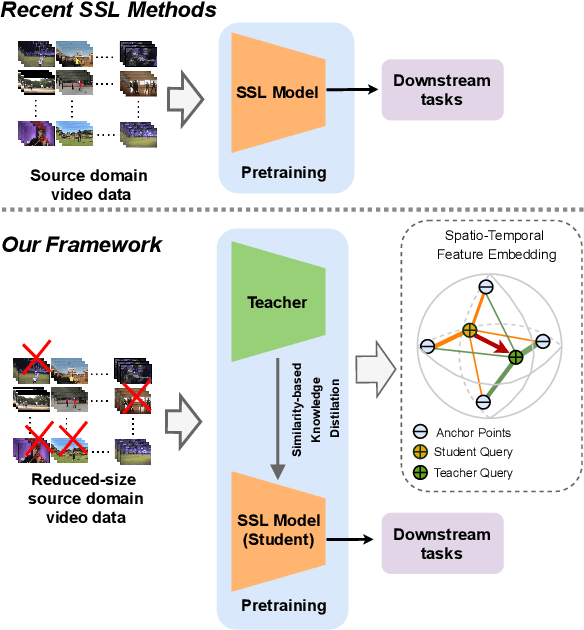
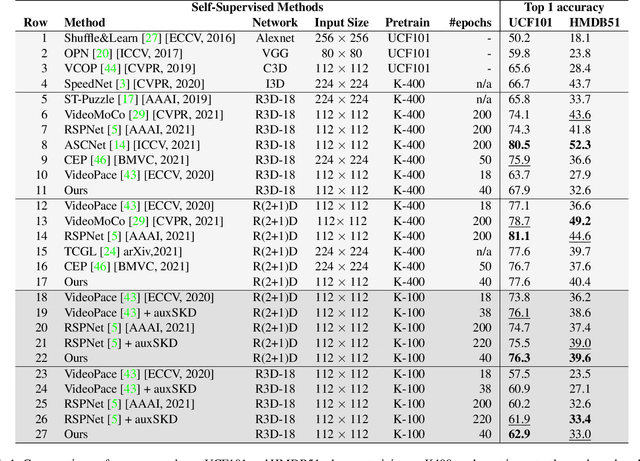
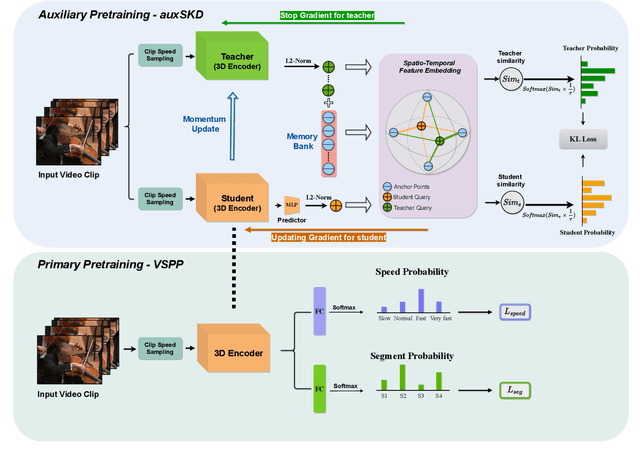
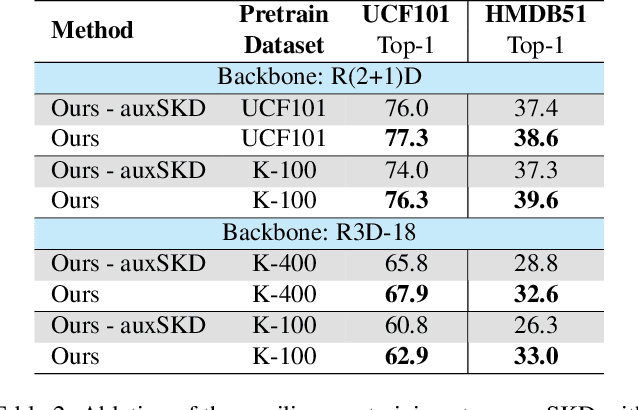
Despite the outstanding success of self-supervised pretraining methods for video representation learning, they generalise poorly when the unlabeled dataset for pretraining is small or the domain difference between unlabelled data in source task (pretraining) and labeled data in target task (finetuning) is significant. To mitigate these issues, we propose a novel approach to complement self-supervised pretraining via an auxiliary pretraining phase, based on knowledge similarity distillation, auxSKD, for better generalisation with a significantly smaller amount of video data, e.g. Kinetics-100 rather than Kinetics-400. Our method deploys a teacher network that iteratively distils its knowledge to the student model by capturing the similarity information between segments of unlabelled video data. The student model then solves a pretext task by exploiting this prior knowledge. We also introduce a novel pretext task, Video Segment Pace Prediction or VSPP, which requires our model to predict the playback speed of a randomly selected segment of the input video to provide more reliable self-supervised representations. Our experimental results show superior results to the state of the art on both UCF101 and HMDB51 datasets when pretraining on K100. Additionally, we show that our auxiliary pertaining, auxSKD, when added as an extra pretraining phase to recent state of the art self-supervised methods (e.g. VideoPace and RSPNet), improves their results on UCF101 and HMDB51. Our code will be released soon.