 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Graph-based Features For Shape Recognition
Sep 08, 2019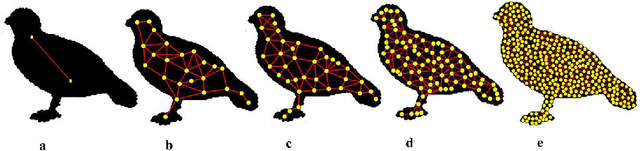

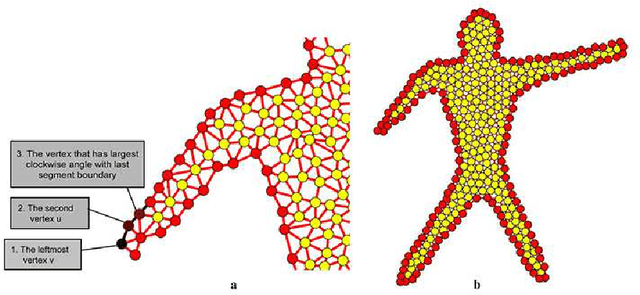

Shape recognition is the main challenging problem in computer vision. Different approaches and tools are used to solve this problem. Most existing approaches to object recognition are based on pixels. Pixel-based methods are dependent on the geometry and nature of the pixels, so the destruction of pixels reduces their performance. In this paper, we study the ability of graphs as shape recognition. We construct a graph that captures the topological and geometrical properties of the object. Then, using the coordinate and relation of its vertices, we extract features that are robust to noise, rotation, scale variation, and articulation. To evaluate our method, we provide different comparisons with state-of-the-art results on various known benchmarks, including Kimia's, Tari56, Tetrapod, and Articulated dataset. We provide an analysis of our method against different variations. The results confirm our performance, especially against noise.
Physical Attribute Prediction Using Deep Residual Neural Networks
Dec 19, 2018

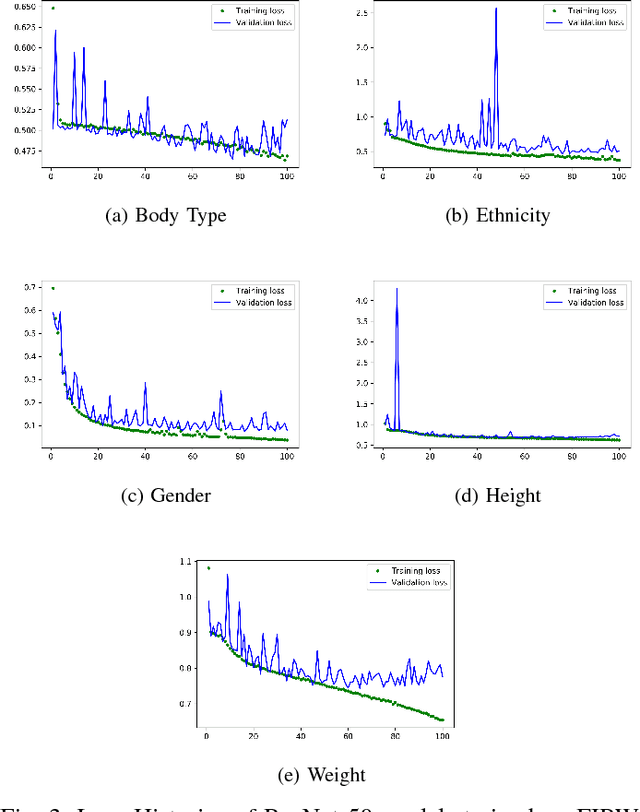
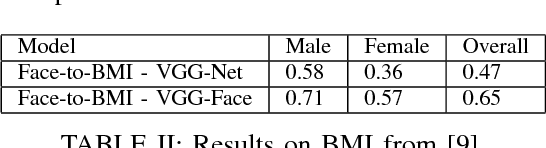
Images taken from the Internet have been used alongside Deep Learning for many different tasks such as: smile detection, ethnicity, hair style, hair colour, gender and age prediction. After witnessing these usages, we were wondering what other attributes can be predicted from facial images available on the Internet. In this paper we tackle the prediction of physical attributes from face images using Convolutional Neural Networks trained on our dataset named FIRW. We crawled around 61, 000 images from the web, then use face detection to crop faces from these real world images. We choose ResNet-50 as our base network architecture. This network was pretrained for the task of face recognition by using the VGG-Face dataset, and we finetune it by using our own dataset to predict physical attributes. Separate networks are trained for the prediction of body type, ethnicity, gender, height and weight; our models achieve the following accuracies for theses tasks, respectively: 84.58%, 87.34%, 97.97%, 70.51%, 63.99%. To validate our choice of ResNet-50 as the base architecture, we also tackle the famous CelebA dataset. Our models achieve an averagy accuracy of 91.19% on CelebA, which is comparable to state-of-the-art approaches.
Multi-Level Contextual Network for Biomedical Image Segmentation
Sep 30, 2018
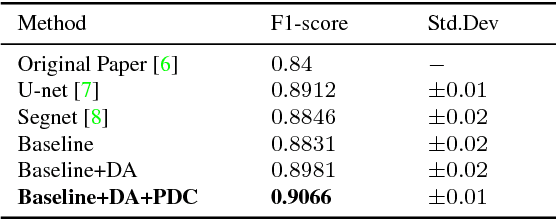
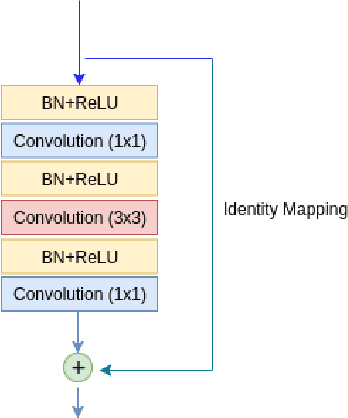
Accurate and reliable image segmentation is an essential part of biomedical image analysis. In this paper, we consider the problem of biomedical image segmentation using deep convolutional neural networks. We propose a new end-to-end network architecture that effectively integrates local and global contextual patterns of histologic primitives to obtain a more reliable segmentation result. Specifically, we introduce a deep fully convolution residual network with a new skip connection strategy to control the contextual information passed forward. Moreover, our trained model is also computationally inexpensive due to its small number of network parameters. We evaluate our method on two public datasets for epithelium segmentation and tubule segmentation tasks. Our experimental results show that the proposed method provides a fast and effective way of producing a pixel-wise dense prediction of biomedical images.
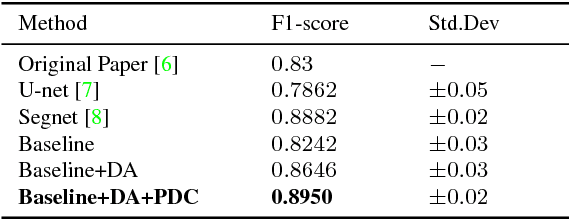
HGR-Net: A Two-stage Convolutional Neural Network for Hand Gesture Segmentation and Recognition
Jun 14, 2018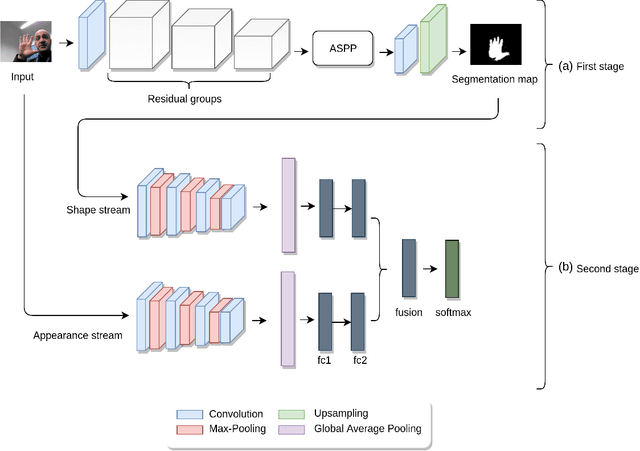
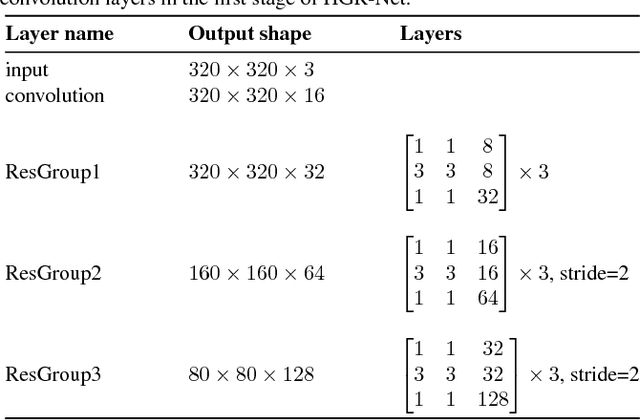
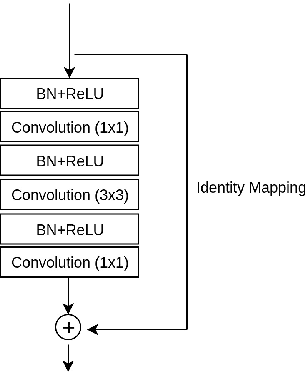
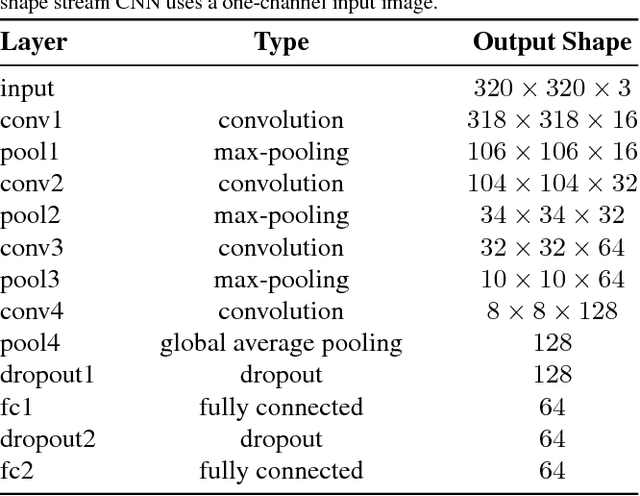
Robust recognition of hand gesture in real-world applications is still a challenging task due to the many aspects such as cluttered backgrounds and uncontrolled environment factors. In most existing methods hand segmentation is a primary step for hand gesture recognition, because it reduces redundant information from the image background, before passing them to the recognition stages. Therefore, in this paper we propose a two-stage deep convolutional neural network (CNN) architecture called HGR-Net, where the first stage performs accurate pixel-level semantic segmentation into hand region and the second stage identifies hand gesture style. The segmentation stage architecture is based on the combination of fully convolutional deep residual neural network and atrous spatial pyramid pooling. Although the segmentation sub-network is trained without using depth information, it is robust enough against challenging situations such as changes in the lightning and complex backgrounds. In the recognition stage a two-stream CNN is used to obtain the best classification score. We also apply an effective data augmentation technique for maximizing the generalization capability of HGR-Net. Extensive experiments on public hand gesture datasets show that our deep architecture achieves prominent performance in segmentation and recognition for static hand gestures.