 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Connected Neural Decision Classifier and Regressor with Dynamic Softing Pruning
Nov 20, 2019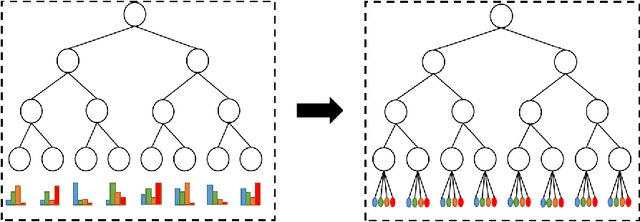
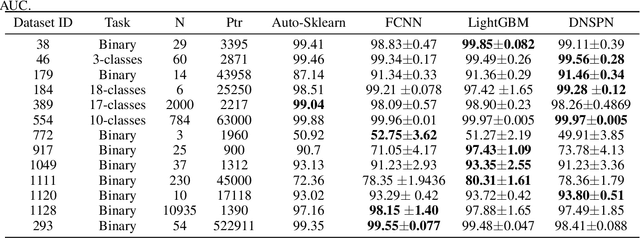
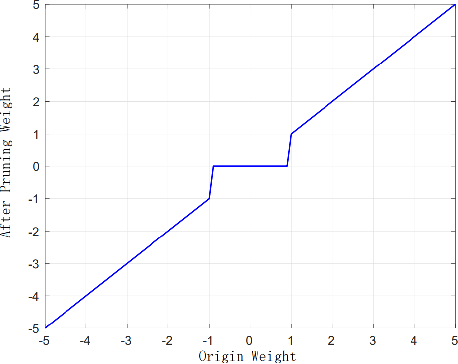
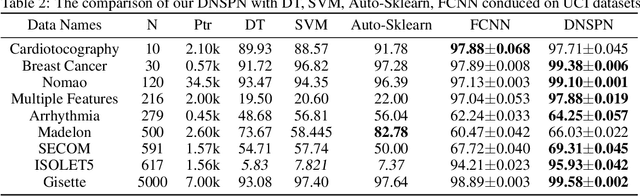
To deal with datasets of different complexity, this paper presents an efficient learning model that combines the proposed Dynamic Connected Neural Decision Networks (DNDN) and a new pruning method--Dynamic Soft Pruning (DSP). DNDN is a combination of random forests and deep neural networks thereby it enjoys both the properties of powerful classification capability and representation learning functionality. Different from Deep Neural Decision Forests (DNDF), this paper adopts an end-to-end training approach by representing the classification distribution with multiple randomly initialized softmax layers, which enables the placement of the forest trees after each layer in the neural network and greatly improves the training speed and stability. Furthermore, DSP is proposed to reduce the redundant connections of the network in a soft fashion which has high flexibility but demonstrates no performance loss compared with previous approaches. Extensive experiments on different datasets demonstrate the superiority of the proposed model over other popular algorithms in solving classification tasks.
Regression via Arbitrary Quantile Modeling
Nov 13, 2019
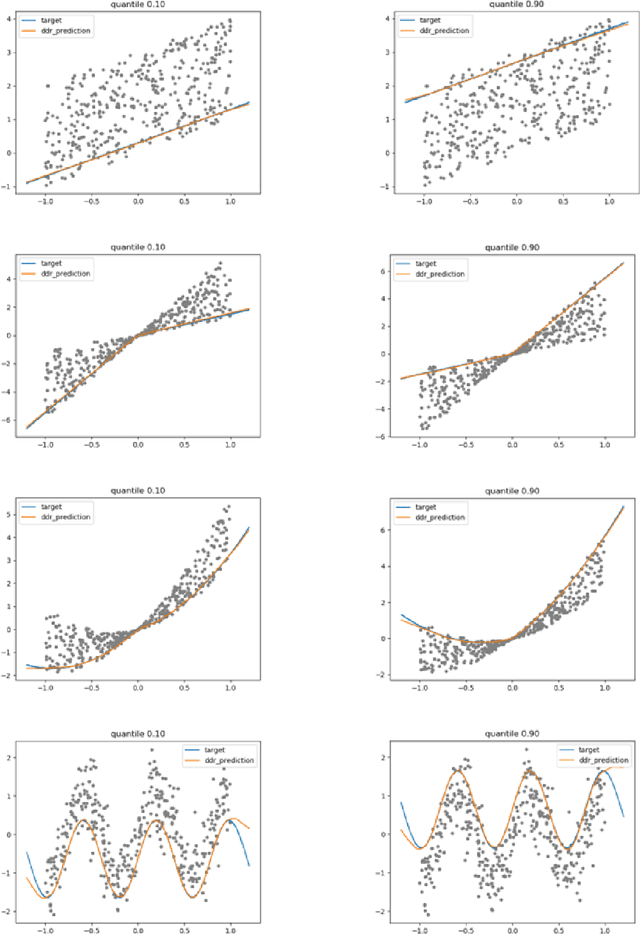
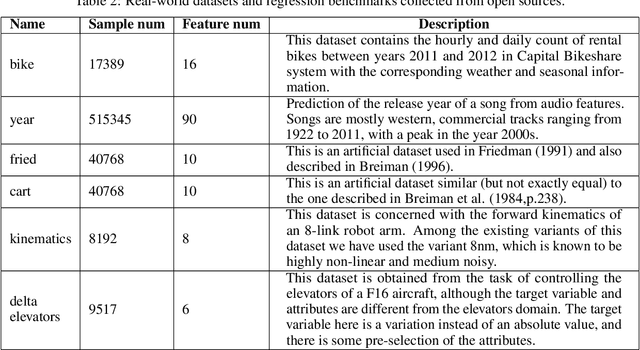

In the regression problem, L1 and L2 are the most commonly used loss functions, which produce mean predictions with different biases. However, the predictions are neither robust nor adequate enough since they only capture a few conditional distributions instead of the whole distribution, especially for small datasets. To address this problem, we proposed arbitrary quantile modeling to regulate the prediction, which achieved better performance compared to traditional loss functions. More specifically, a new distribution regression method, Deep Distribution Regression (DDR), is proposed to estimate arbitrary quantiles of the response variable. Our DDR method consists of two models: a Q model, which predicts the corresponding value for arbitrary quantile, and an F model, which predicts the corresponding quantile for arbitrary value. Furthermore, the duality between Q and F models enables us to design a novel loss function for joint training and perform a dual inference mechanism. Our experiments demonstrate that our DDR-joint and DDR-disjoint methods outperform previous methods such as AdaBoost, random forest, LightGBM, and neural networks both in terms of mean and quantile prediction.