 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiOpt: Bi-Level Optimization for Few-Shot Segmentation
Nov 23, 2020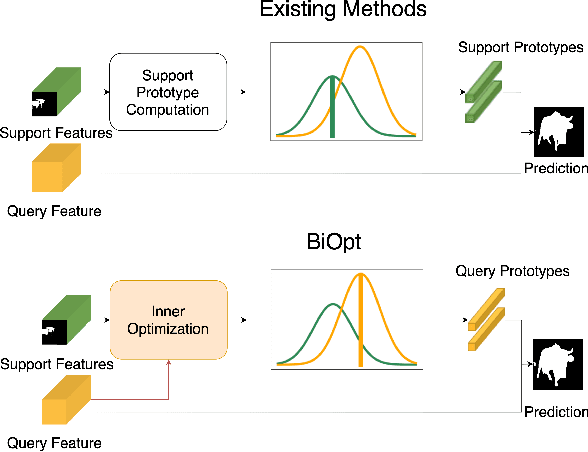
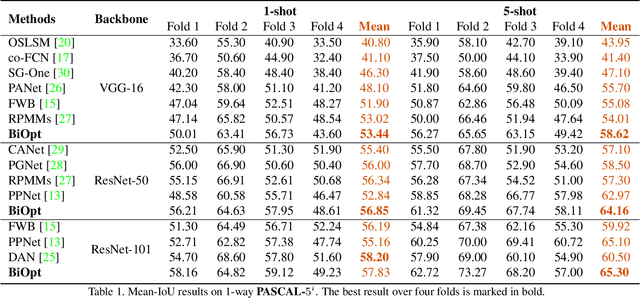

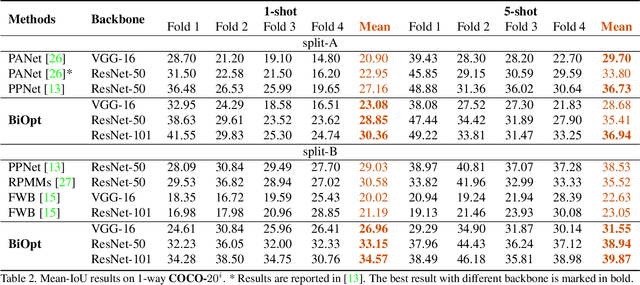
Few-shot segmentation is a challenging task that aims to segment objects of new classes given scarce support images. In the inductive setting, existing prototype-based methods focus on extracting prototypes from the support images; however, they fail to utilize semantic information of the query images. In this paper, we propose Bi-level Optimization (BiOpt), which succeeds to compute class prototypes from the query images under inductive setting. The learning procedure of BiOpt is decomposed into two nested loops: inner and outer loop. On each task, the inner loop aims to learn optimized prototypes from the query images. An init step is conducted to fully exploit knowledge from both support and query features, so as to give reasonable initialized prototypes into the inner loop. The outer loop aims to learn a discriminative embedding space across different tasks. Extensive experiments on two benchmarks verify the superiority of our proposed BiOpt algorithm. In particular, we consistently achieve the state-of-the-art performance on 5-shot PASCAL-$5^i$ and 1-shot COCO-$20^i$.
Prototype Refinement Network for Few-Shot Segmentation
Feb 10, 2020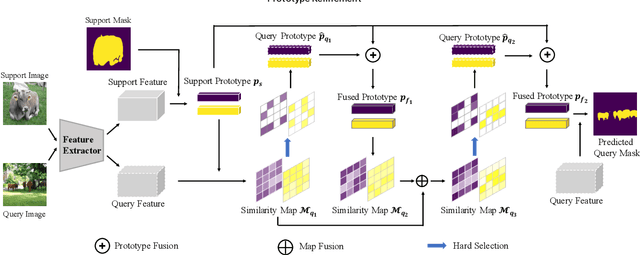
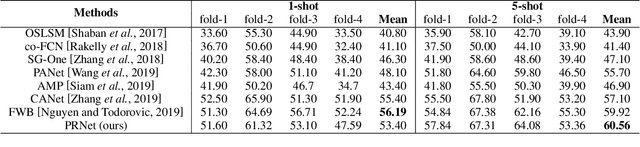

Few-shot segmentation targets to segment new classes with few annotated images provided. It is more challenging than traditional semantic segmentation tasks that segment pre-defined classes with abundant annotated data. In this paper, we propose Prototype Refinement Network (PRNet) to attack the challenge of few-shot segmentation. PRNet learns to bidirectionally extract prototypes from both support and query images, which is different from existing methods. To extract representative prototypes of the new classes, we use adaptation and fusion for prototype refinement. The adaptation of PRNet is implemented by fine-tuning on the support set. Furthermore, prototype fusion is adopted to fuse support prototypes with query prototypes, incorporating the knowledge from both sides. Refined in this way, the prototypes become more discriminative in low-data regimes. Experiments on PASAL-$5^i$ and COCO-$20^i$ demonstrate the superiority of our method. Especially on COCO-$20^i$, PRNet significantly outperforms previous methods by a large margin of 13.1% in 1-shot setting and 17.4% in 5-shot setting respectively.
Hierarchical Attention Networks for Medical Image Segmentation
Nov 25, 2019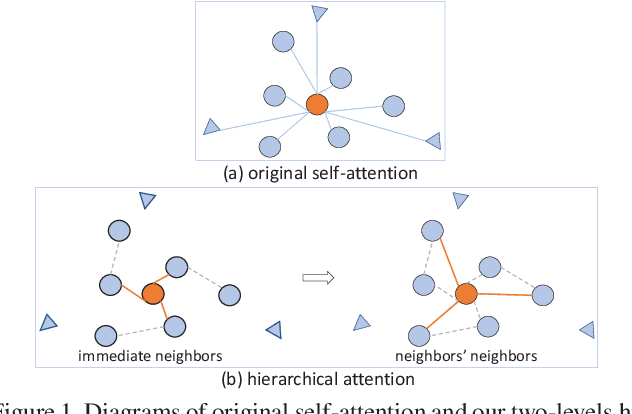
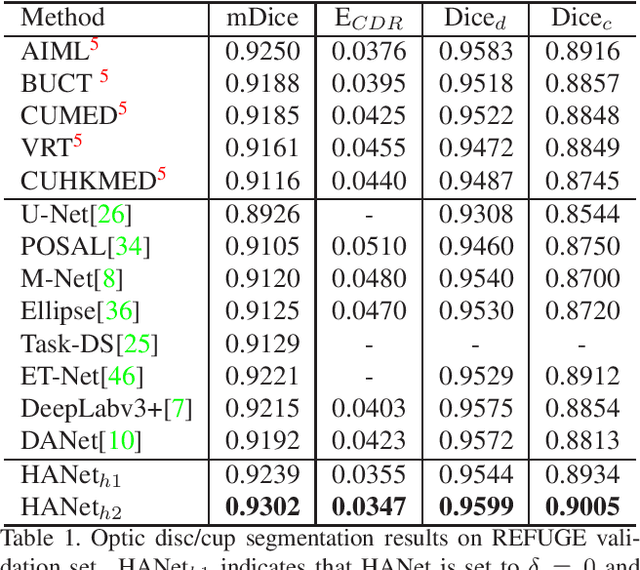
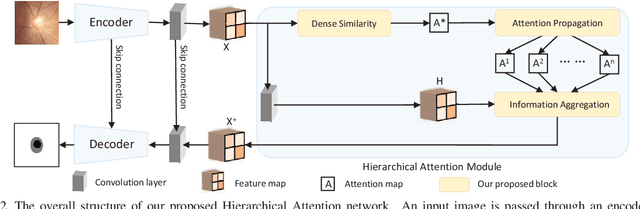
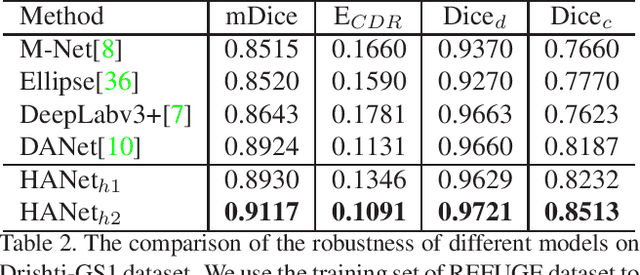
The medical image is characterized by the inter-class indistinction, high variability, and noise, where the recognition of pixels is challenging. Unlike previous self-attention based methods that capture context information from one level, we reformulate the self-attention mechanism from the view of the high-order graph and propose a novel method, namely Hierarchical Attention Network (HANet), to address the problem of medical image segmentation. Concretely, an HA module embedded in the HANet captures context information from neighbors of multiple levels, where these neighbors are extracted from the high-order graph. In the high-order graph, there will be an edge between two nodes only if the correlation between them is high enough, which naturally reduces the noisy attention information caused by the inter-class indistinction. The proposed HA module is robust to the variance of input and can be flexibly inserted into the existing convolution neural networks. We conduct experiments on three medical image segmentation tasks including optic disc/cup segmentation, blood vessel segmentation, and lung segmentation. Extensive results show our method is more effective and robust than the existing state-of-the-art methods.
Fast and Generalized Adaptation for Few-Shot Learning
Nov 25, 2019
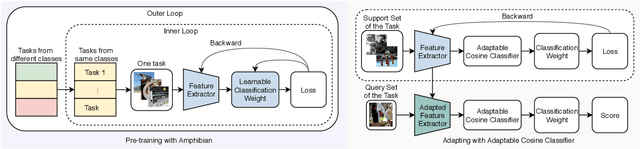
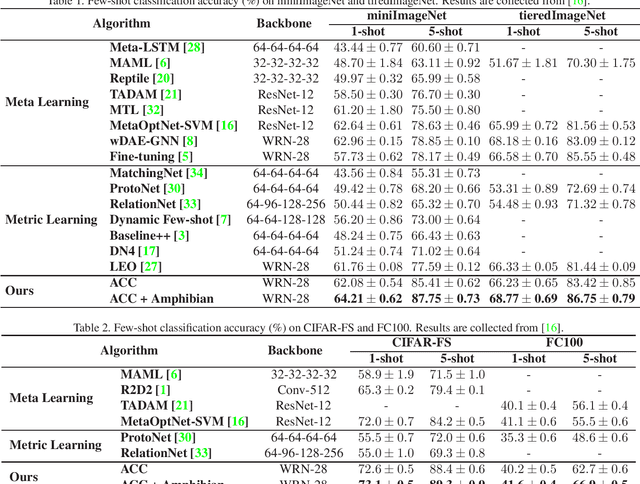
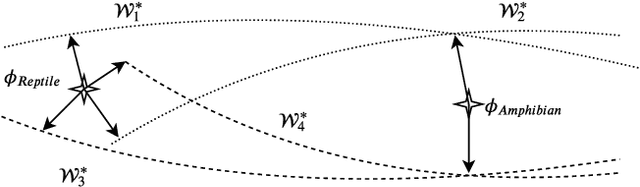
The ability of fast generalizing to novel tasks from a few examples is critical in dealing with few-shot learning problems. However, deep learning models severely suffer from overfitting in extreme low data regime. In this paper, we propose Adaptable Cosine Classifier (ACC) and Amphibian to achieve fast and generalized adaptation for few-shot learning. The ACC realizes the flexible retraining of a deep network on small data without overfitting. The Amphibian learns a good weight initialization in the parameter space where optimal solutions for the tasks of the same class cluster tightly. It enables rapid adaptation to novel tasks with few gradient updates. We conduct comprehensive experiments on four few-shot datasets and achieve state-of-the-art performance in all cases. Notably, we achieve the accuracy of 87.75% on 5-shot miniImageNet which approximately outperforms existing methods by 10%. We also conduct experiment on cross-domain few-shot tasks and provide the best results.
Prototype Rectification for Few-Shot Learning
Nov 25, 2019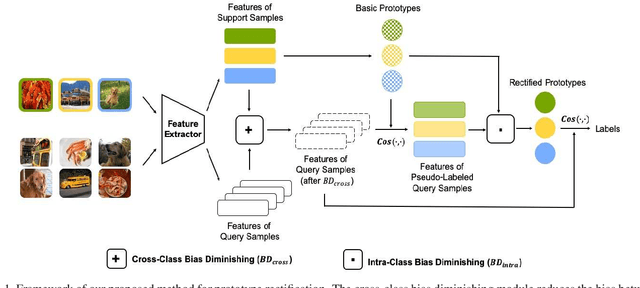
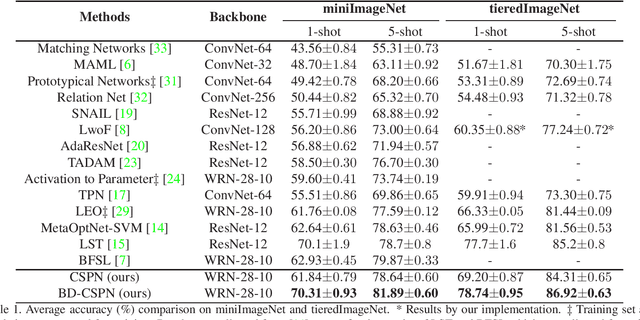

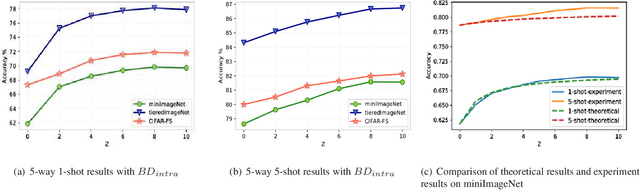
Few-shot learning is a challenging problem that requires a model to recognize novel classes with few labeled data. In this paper, we aim to find the expected prototypes of the novel classes, which have the maximum cosine similarity with the samples of the same class. Firstly, we propose a cosine similarity based prototypical network to compute basic prototypes of the novel classes from the few samples. A bias diminishing module is further proposed for prototype rectification since the basic prototypes computed in the low-data regime are biased against the expected prototypes. In our method, the intra-class bias and the cross-class bias are diminished to modify the prototypes. Then we give a theoretical analysis of the impact of the bias diminishing module on the expected performance of our method. We conduct extensive experiments on four few-shot benchmarks and further analyze the advantage of the bias diminishing module. The bias diminishing module brings in significant improvement by a large margin of 3% to 9% in general. Notably, our approach achieves state-of-the-art performance on miniImageNet (70.31% in 1-shot and 81.89% in 5-shot) and tieredImageNet (78.74% in 1-shot and 86.92% in 5-shot), which demonstrates the superiority of the proposed method.
Imagination Based Sample Construction for Zero-Shot Learning
Oct 29, 2018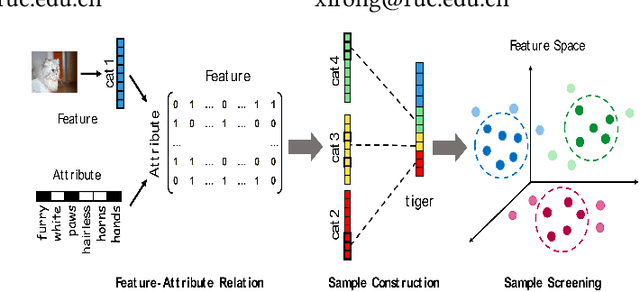
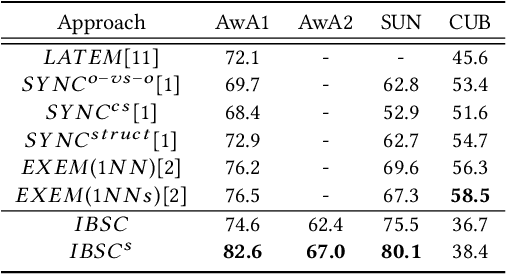
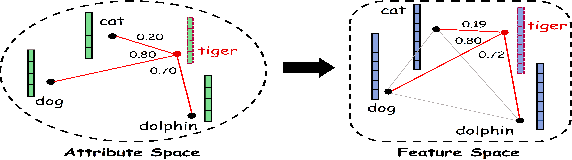
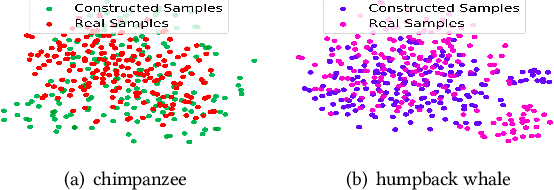
Zero-shot learning (ZSL) which aims to recognize unseen classes with no labeled training sample, efficiently tackles the problem of missing labeled data in image retrieval. Nowadays there are mainly two types of popular methods for ZSL to recognize images of unseen classes: probabilistic reasoning and feature projection. Different from these existing types of methods, we propose a new method: sample construction to deal with the problem of ZSL. Our proposed method, called Imagination Based Sample Construction (IBSC), innovatively constructs image samples of target classes in feature space by mimicking human associative cognition process. Based on an association between attribute and feature, target samples are constructed from different parts of various samples. Furthermore, dissimilarity representation is employed to select high-quality constructed samples which are used as labeled data to train a specific classifier for those unseen classes. In this way, zero-shot learning is turned into a supervised learning problem. As far as we know, it is the first work to construct samples for ZSL thus, our work is viewed as a baseline for future sample construction methods. Experiments on four benchmark datasets show the superiority of our proposed method.