 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReeM: Ensemble Building Thermodynamics Model for Efficient HVAC Control via Hierarchical Reinforcement Learning
May 05, 2025The building thermodynamics model, which predicts real-time indoor temperature changes under potential HVAC (Heating, Ventilation, and Air Conditioning) control operations, is crucial for optimizing HVAC control in buildings. While pioneering studies have attempted to develop such models for various building environments, these models often require extensive data collection periods and rely heavily on expert knowledge, making the modeling process inefficient and limiting the reusability of the models. This paper explores a model ensemble perspective that utilizes existing developed models as base models to serve a target building environment, thereby providing accurate predictions while reducing the associated efforts. Given that building data streams are non-stationary and the number of base models may increase, we propose a Hierarchical Reinforcement Learning (HRL) approach to dynamically select and weight the base models. Our approach employs a two-tiered decision-making process: the high-level focuses on model selection, while the low-level determines the weights of the selected models. We thoroughly evaluate the proposed approach through offline experiments and an on-site case study, and the experimental results demonstrate the effectiveness of our method.
Enabling Time-series Foundation Model for Building Energy Forecasting via Contrastive Curriculum Learning
Dec 23, 2024
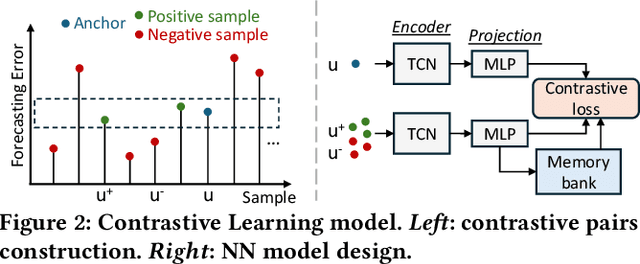
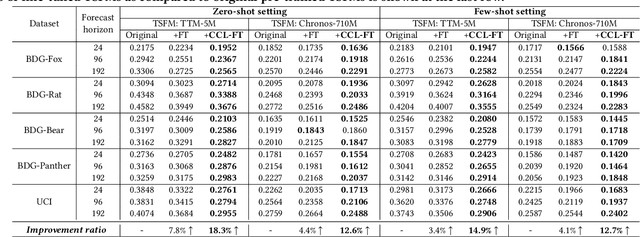
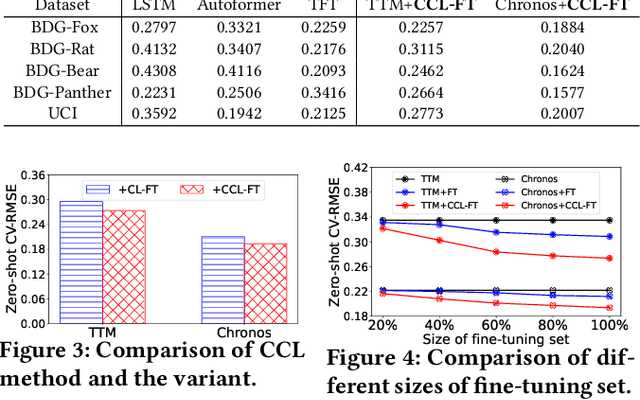
Advances in time-series forecasting are driving a shift from conventional machine learning models to foundation models (FMs) that are trained with generalized knowledge. However, existing FMs still perform poorly in the energy fields, such as building energy forecasting (BEF). This paper studies the adaptation of FM to BEF tasks. We demonstrate the shortcomings of fine-tuning FM straightforwardly from both the perspectives of FM and the data. To overcome these limitations, we propose a new \textit{contrastive curriculum learning}-based training method. Our method optimizes the ordering of training data in the context of TSFM adaptation. Experiments show that our method can improve the zero/few-shot performance by 14.6\% compared to the existing FMs. Our code and new TSFM will be available at <Anonymous Github Repo>.
A Large-scale Attribute Dataset for Zero-shot Learning
May 16, 2018
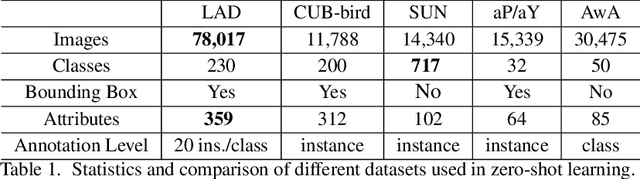
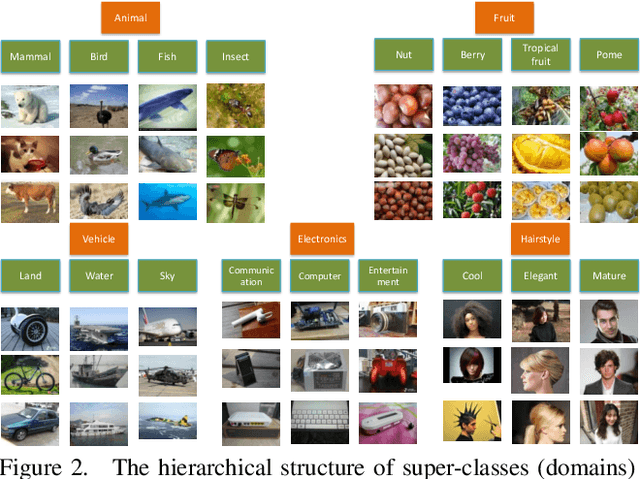
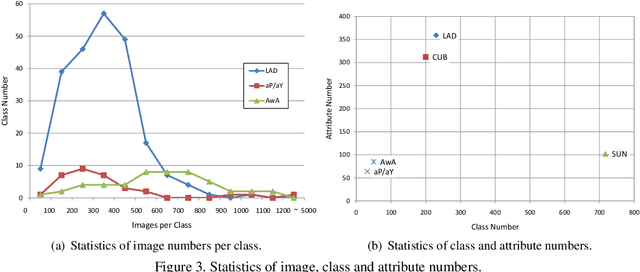
Zero-Shot Learning (ZSL) has attracted huge research attention over the past few years; it aims to learn the new concepts that have never been seen before. In classical ZSL algorithms, attributes are introduced as the intermediate semantic representation to realize the knowledge transfer from seen classes to unseen classes. Previous ZSL algorithms are tested on several benchmark datasets annotated with attributes. However, these datasets are defective in terms of the image distribution and attribute diversity. In addition, we argue that the "co-occurrence bias problem" of existing datasets, which is caused by the biased co-occurrence of objects, significantly hinders models from correctly learning the concept. To overcome these problems, we propose a Large-scale Attribute Dataset (LAD). Our dataset has 78,017 images of 5 super-classes, 230 classes. The image number of LAD is larger than the sum of the four most popular attribute datasets. 359 attributes of visual, semantic and subjective properties are defined and annotated in instance-level. We analyze our dataset by conducting both supervised learning and zero-shot learning tasks. Seven state-of-the-art ZSL algorithms are tested on this new dataset. The experimental results reveal the challenge of implementing zero-shot learning on our dataset.
AI Challenger : A Large-scale Dataset for Going Deeper in Image Understanding
Nov 17, 2017
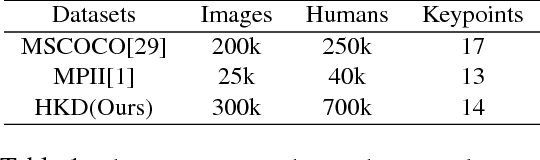
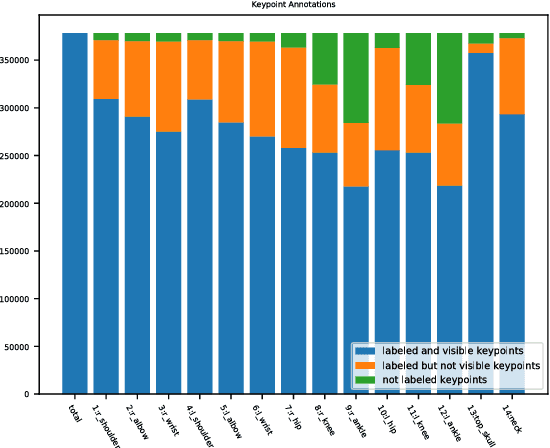
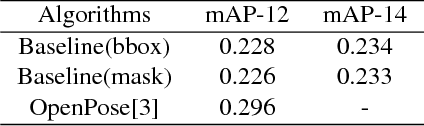
Significant progress has been achieved in Computer Vision by leveraging large-scale image datasets. However, large-scale datasets for complex Computer Vision tasks beyond classification are still limited. This paper proposed a large-scale dataset named AIC (AI Challenger) with three sub-datasets, human keypoint detection (HKD), large-scale attribute dataset (LAD) and image Chinese captioning (ICC). In this dataset, we annotate class labels (LAD), keypoint coordinate (HKD), bounding box (HKD and LAD), attribute (LAD) and caption (ICC). These rich annotations bridge the semantic gap between low-level images and high-level concepts. The proposed dataset is an effective benchmark to evaluate and improve different computational methods. In addition, for related tasks, others can also use our dataset as a new resource to pre-train their models.