 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZEN 2.0: Continue Training and Adaption for N-gram Enhanced Text Encoders
May 04, 2021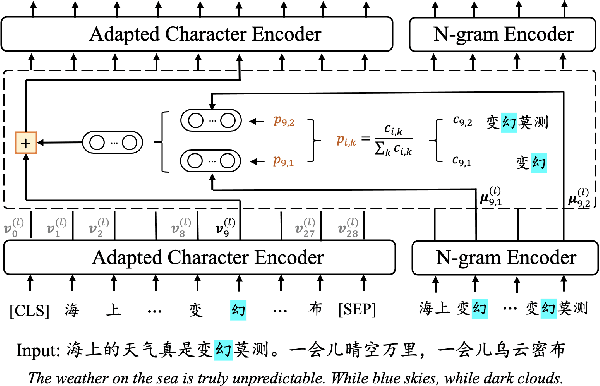
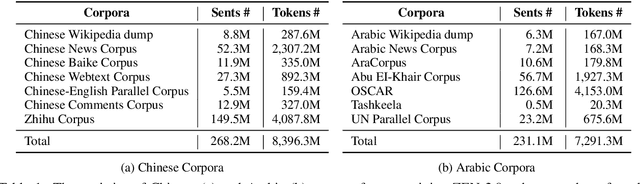
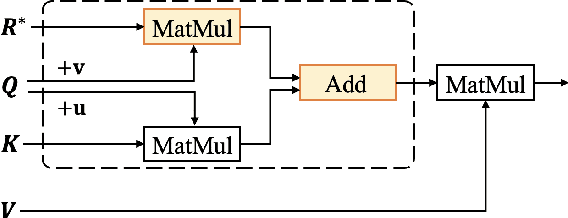
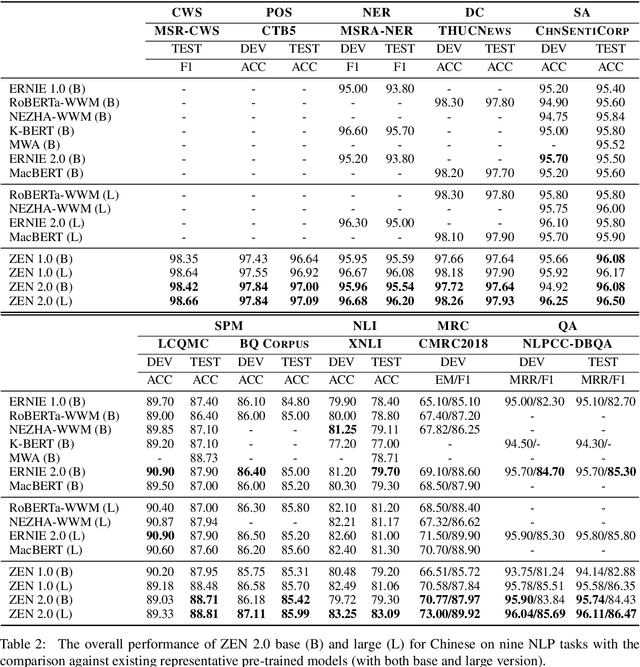
Pre-trained text encoders have drawn sustaining attention in natural language processing (NLP) and shown their capability in obtaining promising results in different tasks. Recent studies illustrated that external self-supervised signals (or knowledge extracted by unsupervised learning, such as n-grams) are beneficial to provide useful semantic evidence for understanding languages such as Chinese, so as to improve the performance on various downstream tasks accordingly. To further enhance the encoders, in this paper, we propose to pre-train n-gram-enhanced encoders with a large volume of data and advanced techniques for training. Moreover, we try to extend the encoder to different languages as well as different domains, where it is confirmed that the same architecture is applicable to these varying circumstances and new state-of-the-art performance is observed from a long list of NLP tasks across languages and domains.
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations
Nov 02, 2019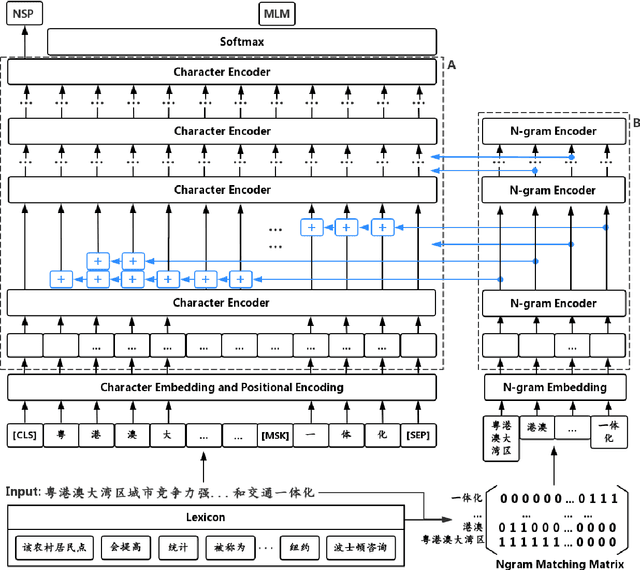
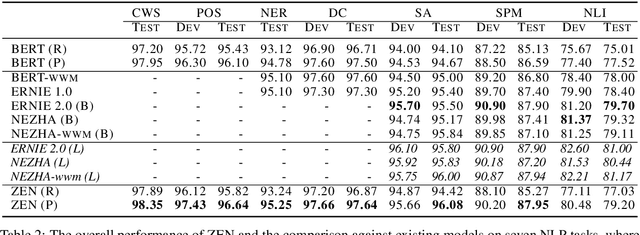
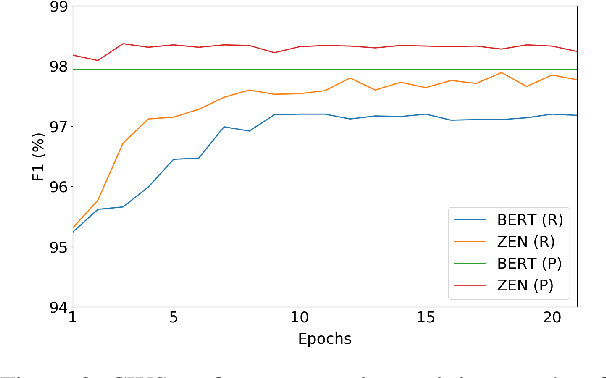
The pre-training of text encoders normally processes text as a sequence of tokens corresponding to small text units, such as word pieces in English and characters in Chinese. It omits information carried by larger text granularity, and thus the encoders cannot easily adapt to certain combinations of characters. This leads to a loss of important semantic information, which is especially problematic for Chinese because the language does not have explicit word boundaries. In this paper, we propose ZEN, a BERT-based Chinese (Z) text encoder Enhanced by N-gram representations, where different combinations of characters are considered during training. As a result, potential word or phase boundaries are explicitly pre-trained and fine-tuned with the character encoder (BERT). Therefore ZEN incorporates the comprehensive information of both the character sequence and words or phrases it contains. Experimental results illustrated the effectiveness of ZEN on a series of Chinese NLP tasks. We show that ZEN, using less resource than other published encoders, can achieve state-of-the-art performance on most tasks. Moreover, it is shown that reasonable performance can be obtained when ZEN is trained on a small corpus, which is important for applying pre-training techniques to scenarios with limited data. The code and pre-trained models of ZEN are available at https://github.com/sinovation/zen.
A Large-scale Attribute Dataset for Zero-shot Learning
May 16, 2018
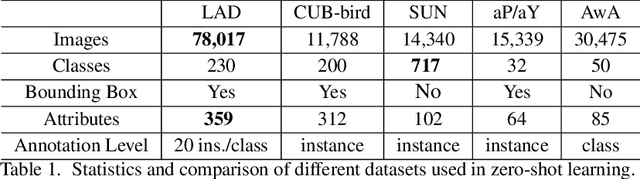
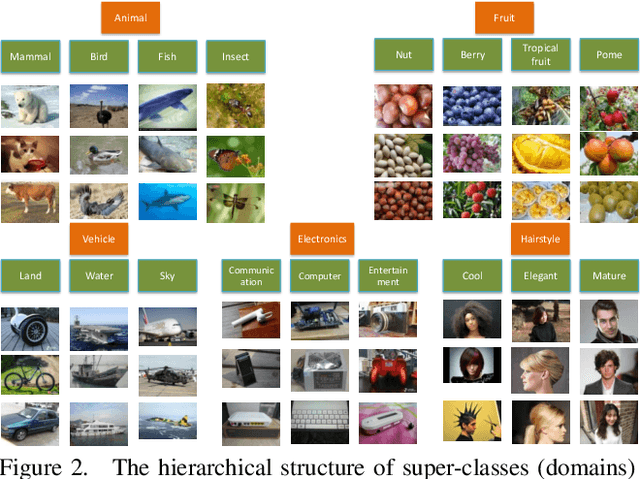
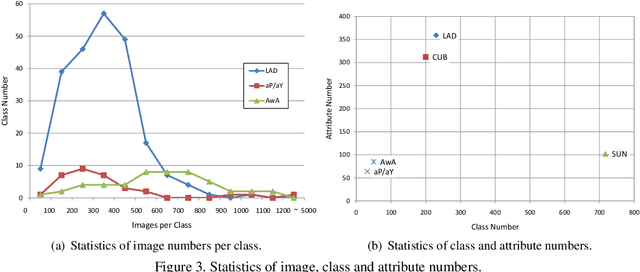
Zero-Shot Learning (ZSL) has attracted huge research attention over the past few years; it aims to learn the new concepts that have never been seen before. In classical ZSL algorithms, attributes are introduced as the intermediate semantic representation to realize the knowledge transfer from seen classes to unseen classes. Previous ZSL algorithms are tested on several benchmark datasets annotated with attributes. However, these datasets are defective in terms of the image distribution and attribute diversity. In addition, we argue that the "co-occurrence bias problem" of existing datasets, which is caused by the biased co-occurrence of objects, significantly hinders models from correctly learning the concept. To overcome these problems, we propose a Large-scale Attribute Dataset (LAD). Our dataset has 78,017 images of 5 super-classes, 230 classes. The image number of LAD is larger than the sum of the four most popular attribute datasets. 359 attributes of visual, semantic and subjective properties are defined and annotated in instance-level. We analyze our dataset by conducting both supervised learning and zero-shot learning tasks. Seven state-of-the-art ZSL algorithms are tested on this new dataset. The experimental results reveal the challenge of implementing zero-shot learning on our dataset.
AI Challenger : A Large-scale Dataset for Going Deeper in Image Understanding
Nov 17, 2017
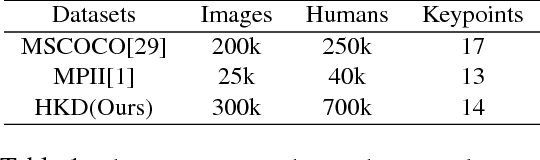
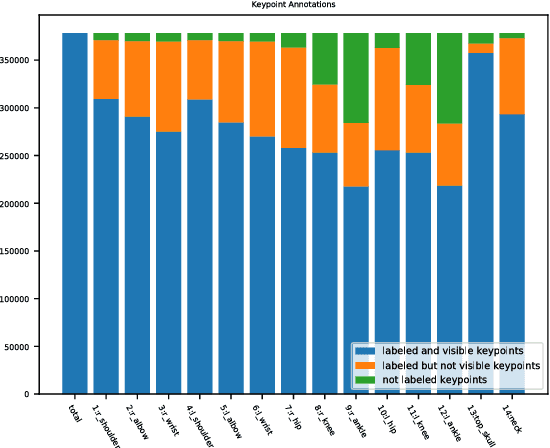
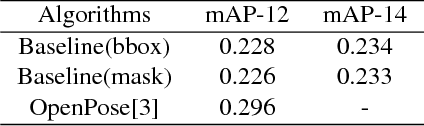
Significant progress has been achieved in Computer Vision by leveraging large-scale image datasets. However, large-scale datasets for complex Computer Vision tasks beyond classification are still limited. This paper proposed a large-scale dataset named AIC (AI Challenger) with three sub-datasets, human keypoint detection (HKD), large-scale attribute dataset (LAD) and image Chinese captioning (ICC). In this dataset, we annotate class labels (LAD), keypoint coordinate (HKD), bounding box (HKD and LAD), attribute (LAD) and caption (ICC). These rich annotations bridge the semantic gap between low-level images and high-level concepts. The proposed dataset is an effective benchmark to evaluate and improve different computational methods. In addition, for related tasks, others can also use our dataset as a new resource to pre-train their models.