 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Granularity Network with Modal Attention for Dense Affective Understanding
Jun 18, 2021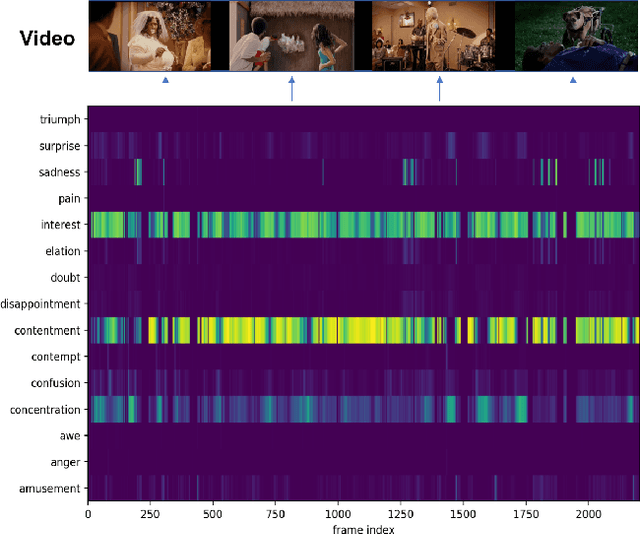

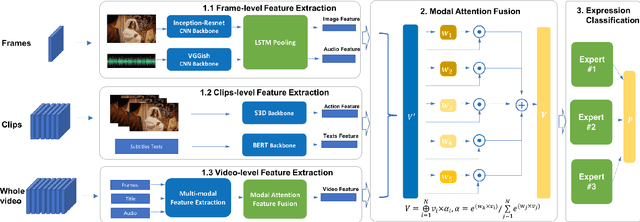
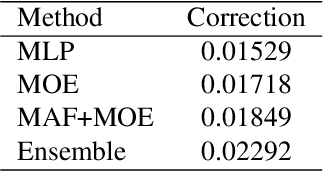
Video affective understanding, which aims to predict the evoked expressions by the video content, is desired for video creation and recommendation. In the recent EEV challenge, a dense affective understanding task is proposed and requires frame-level affective prediction. In this paper, we propose a multi-granularity network with modal attention (MGN-MA), which employs multi-granularity features for better description of the target frame. Specifically, the multi-granularity features could be divided into frame-level, clips-level and video-level features, which corresponds to visual-salient content, semantic-context and video theme information. Then the modal attention fusion module is designed to fuse the multi-granularity features and emphasize more affection-relevant modals. Finally, the fused feature is fed into a Mixtures Of Experts (MOE) classifier to predict the expressions. Further employing model-ensemble post-processing, the proposed method achieves the correlation score of 0.02292 in the EEV challenge.
Augmented Bi-path Network for Few-shot Learning
Jul 15, 2020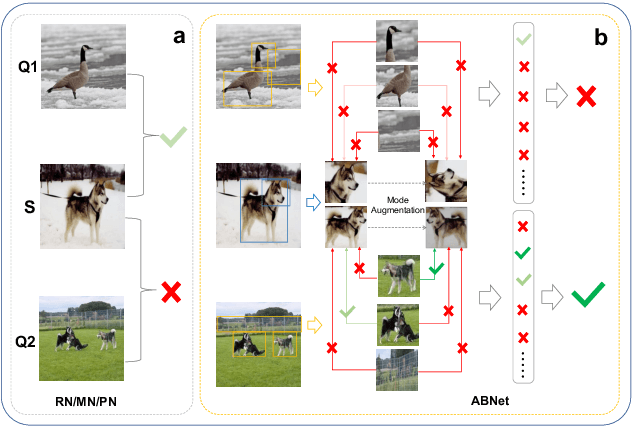
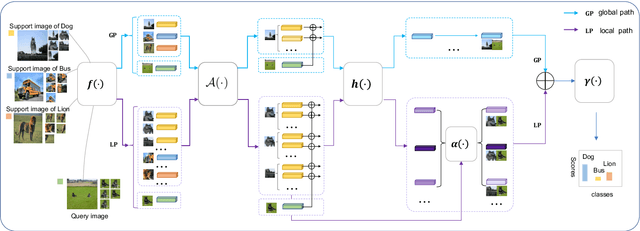
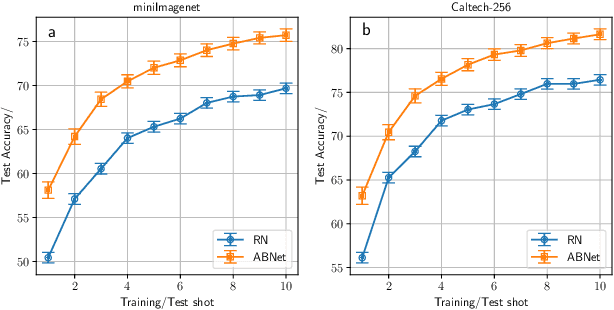

Few-shot Learning (FSL) which aims to learn from few labeled training data is becoming a popular research topic, due to the expensive labeling cost in many real-world applications. One kind of successful FSL method learns to compare the testing (query) image and training (support) image by simply concatenating the features of two images and feeding it into the neural network. However, with few labeled data in each class, the neural network has difficulty in learning or comparing the local features of two images. Such simple image-level comparison may cause serious mis-classification. To solve this problem, we propose Augmented Bi-path Network (ABNet) for learning to compare both global and local features on multi-scales. Specifically, the salient patches are extracted and embedded as the local features for every image. Then, the model learns to augment the features for better robustness. Finally, the model learns to compare global and local features separately, i.e., in two paths, before merging the similarities. Extensive experiments show that the proposed ABNet outperforms the state-of-the-art methods. Both quantitative and visual ablation studies are provided to verify that the proposed modules lead to more precise comparison results.
AI Challenger : A Large-scale Dataset for Going Deeper in Image Understanding
Nov 17, 2017
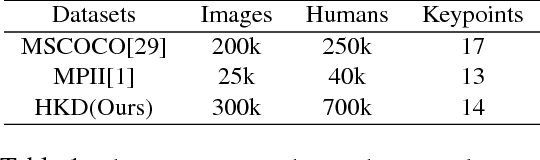
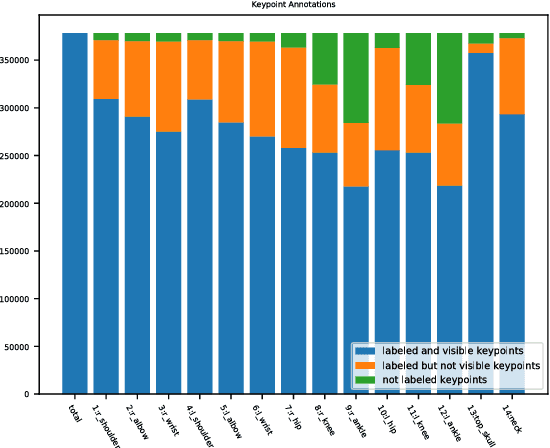
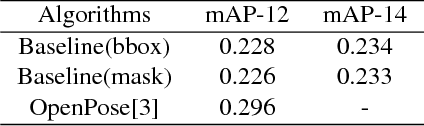
Significant progress has been achieved in Computer Vision by leveraging large-scale image datasets. However, large-scale datasets for complex Computer Vision tasks beyond classification are still limited. This paper proposed a large-scale dataset named AIC (AI Challenger) with three sub-datasets, human keypoint detection (HKD), large-scale attribute dataset (LAD) and image Chinese captioning (ICC). In this dataset, we annotate class labels (LAD), keypoint coordinate (HKD), bounding box (HKD and LAD), attribute (LAD) and caption (ICC). These rich annotations bridge the semantic gap between low-level images and high-level concepts. The proposed dataset is an effective benchmark to evaluate and improve different computational methods. In addition, for related tasks, others can also use our dataset as a new resource to pre-train their models.