 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorRefine: Synergy-Manipulation Based on Trajectory Anchor and Residual Refinement for Vision-Language-Action Models
Apr 20, 2026Precision-critical manipulation requires both global trajectory organization and local execution correction, yet most vision-language-action (VLA) policies generate actions within a single unified space. This monolithic formulation forces macro-level transport and micro-level refinement to be optimized under the same objective, causing large motions to dominate learning while suppressing small but failure-critical corrective signals. In contrast, human manipulation is structured by global movement planning together with continuous local adjustment during execution. Motivated by this principle, we propose AnchorRefine, a hierarchical framework that factorizes VLA action modeling into trajectory anchor and residual refinement. The anchor planner predicts a coarse motion scaffold, while the refinement module corrects execution-level deviations to improve geometric and contact precision. We further introduce a decision-aware gripper refinement mechanism to better capture the discrete and boundary-sensitive nature of gripper control. Experiments on LIBERO, CALVIN, and real-robot tasks demonstrate that AnchorRefine consistently improves both regression-based and diffusion-based VLA backbones, yielding gains of up to 7.8% in simulation success rate and 18% in real-world success rate.
MVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Apr 24, 2022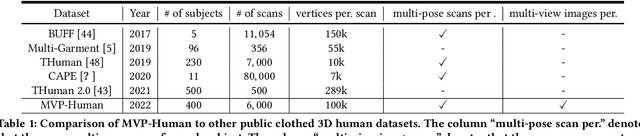
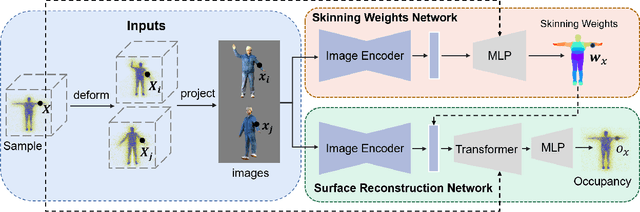
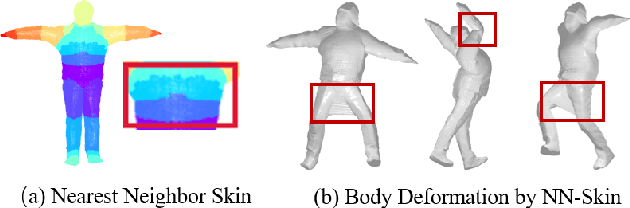
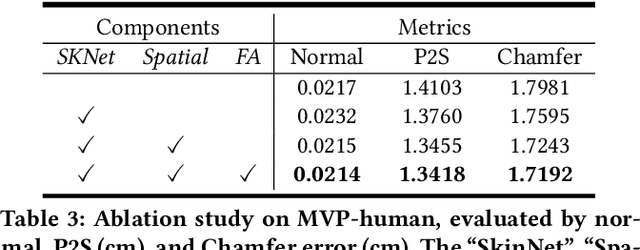
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.
Augmented Bi-path Network for Few-shot Learning
Jul 15, 2020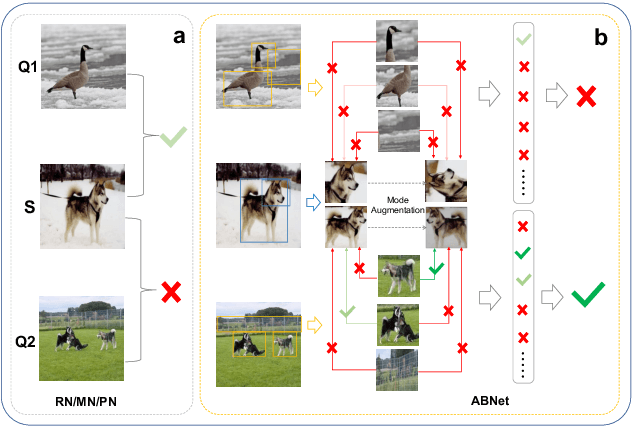
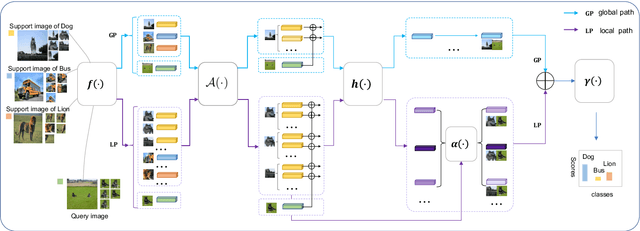
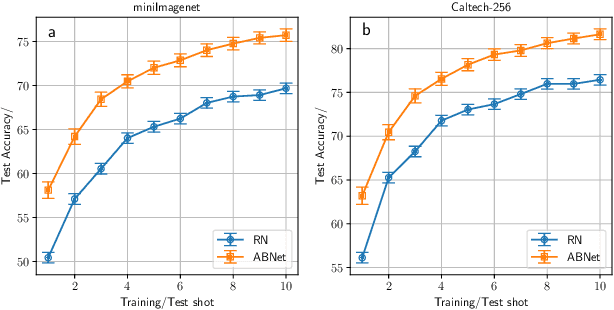

Few-shot Learning (FSL) which aims to learn from few labeled training data is becoming a popular research topic, due to the expensive labeling cost in many real-world applications. One kind of successful FSL method learns to compare the testing (query) image and training (support) image by simply concatenating the features of two images and feeding it into the neural network. However, with few labeled data in each class, the neural network has difficulty in learning or comparing the local features of two images. Such simple image-level comparison may cause serious mis-classification. To solve this problem, we propose Augmented Bi-path Network (ABNet) for learning to compare both global and local features on multi-scales. Specifically, the salient patches are extracted and embedded as the local features for every image. Then, the model learns to augment the features for better robustness. Finally, the model learns to compare global and local features separately, i.e., in two paths, before merging the similarities. Extensive experiments show that the proposed ABNet outperforms the state-of-the-art methods. Both quantitative and visual ablation studies are provided to verify that the proposed modules lead to more precise comparison results.