 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaTrace: Synthesizing Realistic Digital Footprints with LLM Agents
Mar 12, 2026Digital footprints (records of individuals' interactions with digital systems) are essential for studying behavior, developing personalized applications, and training machine learning models. However, research in this area is often hindered by the scarcity of diverse and accessible data. To address this limitation, we propose a novel method for synthesizing realistic digital footprints using large language model (LLM) agents. Starting from a structured user profile, our approach generates diverse and plausible sequences of user events, ultimately producing corresponding digital artifacts such as emails, messages, calendar entries, reminders, etc. Intrinsic evaluation results demonstrate that the generated dataset is more diverse and realistic than existing baselines. Moreover, models fine-tuned on our synthetic data outperform those trained on other synthetic datasets when evaluated on real-world out-of-distribution tasks.
Context Attention Network for Skeleton Extraction
May 24, 2022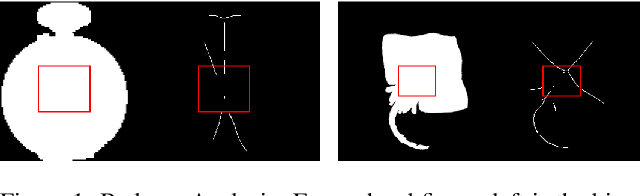

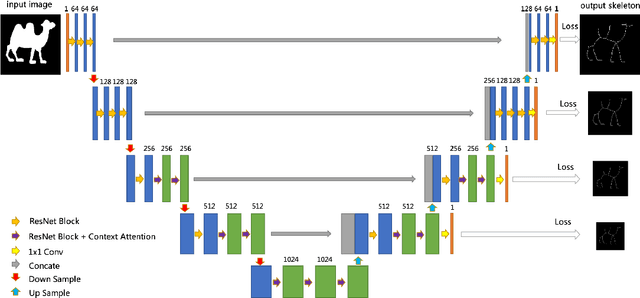

Skeleton extraction is a task focused on providing a simple representation of an object by extracting the skeleton from the given binary or RGB image. In recent years many attractive works in skeleton extraction have been made. But as far as we know, there is little research on how to utilize the context information in the binary shape of objects. In this paper, we propose an attention-based model called Context Attention Network (CANet), which integrates the context extraction module in a UNet architecture and can effectively improve the ability of network to extract the skeleton pixels. Meanwhile, we also use some novel techniques including distance transform, weight focal loss to achieve good results on the given dataset. Finally, without model ensemble and with only 80% of the training images, our method achieves 0.822 F1 score during the development phase and 0.8507 F1 score during the final phase of the Pixel SkelNetOn Competition, ranking 1st place on the leaderboard.
MVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Apr 24, 2022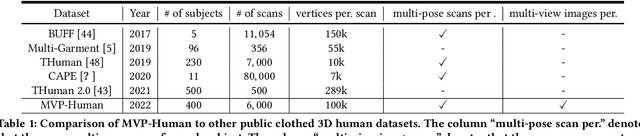
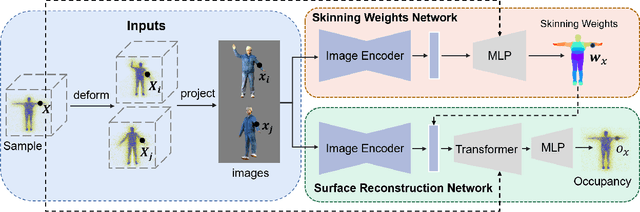
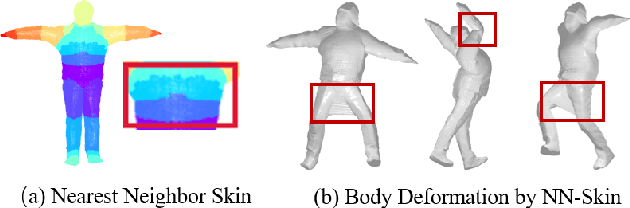
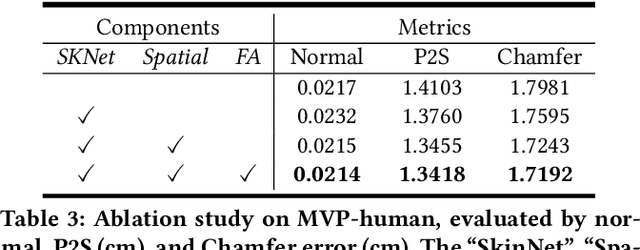
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.
Simple Baseline for Single Human Motion Forecasting
Oct 14, 2021
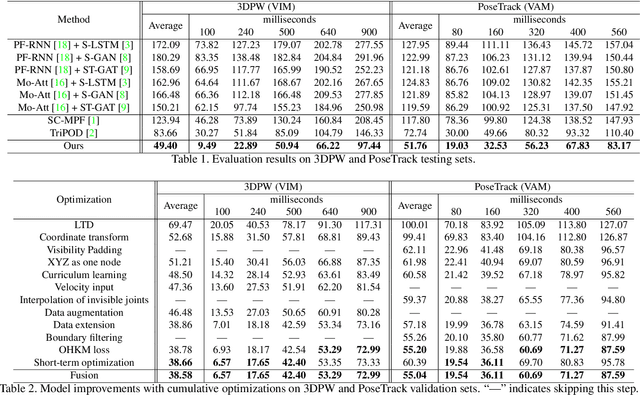
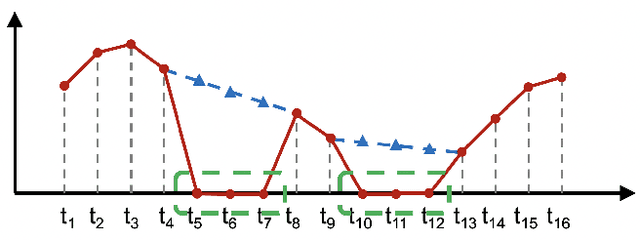

Global human motion forecasting is important in many fields, which is the combination of global human trajectory prediction and local human pose prediction. Visual and social information are often used to boost model performance, however, they may consume too much computational resource. In this paper, we establish a simple but effective baseline for single human motion forecasting without visual and social information, equipped with useful training tricks. Our method "futuremotion_ICCV21" outperforms existing methods by a large margin on SoMoF benchmark. We hope our work provide new ideas for future research.
Affinity-aware Compression and Expansion Network for Human Parsing
Aug 24, 2020
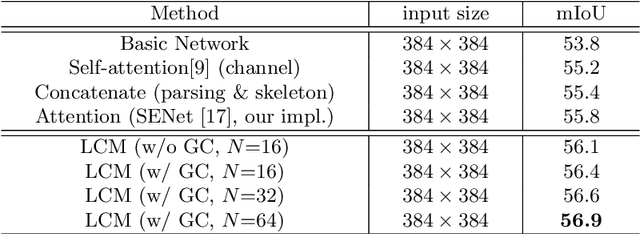
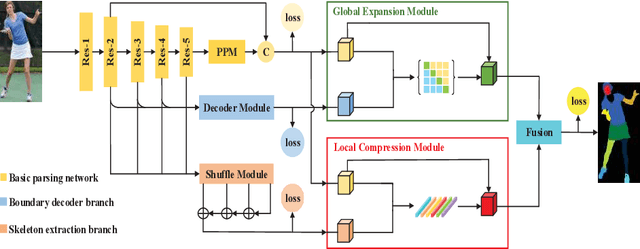
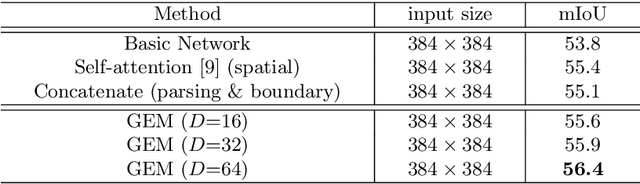
As a fine-grained segmentation task, human parsing is still faced with two challenges: inter-part indistinction and intra-part inconsistency, due to the ambiguous definitions and confusing relationships between similar human parts. To tackle these two problems, this paper proposes a novel \textit{Affinity-aware Compression and Expansion} Network (ACENet), which mainly consists of two modules: Local Compression Module (LCM) and Global Expansion Module (GEM). Specifically, LCM compresses parts-correlation information through structural skeleton points, obtained from an extra skeleton branch. It can decrease the inter-part interference, and strengthen structural relationships between ambiguous parts. Furthermore, GEM expands semantic information of each part into a complete piece by incorporating the spatial affinity with boundary guidance, which can effectively enhance the semantic consistency of intra-part as well. ACENet achieves new state-of-the-art performance on the challenging LIP and Pascal-Person-Part datasets. In particular, 58.1% mean IoU is achieved on the LIP benchmark.
Low-Latency Human Action Recognition with Weighted Multi-Region Convolutional Neural Network
May 08, 2018

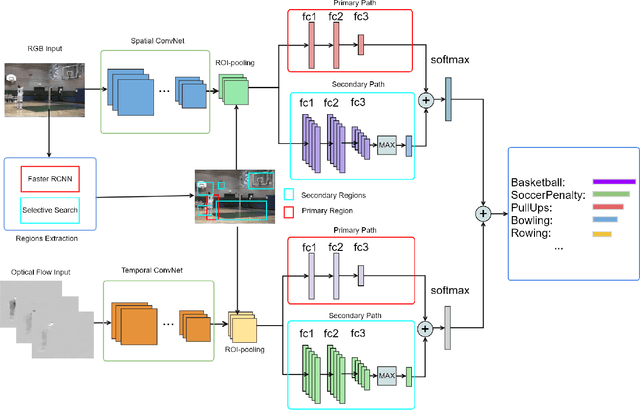

Spatio-temporal contexts are crucial in understanding human actions in videos. Recent state-of-the-art Convolutional Neural Network (ConvNet) based action recognition systems frequently involve 3D spatio-temporal ConvNet filters, chunking videos into fixed length clips and Long Short Term Memory (LSTM) networks. Such architectures are designed to take advantage of both short term and long term temporal contexts, but also requires the accumulation of a predefined number of video frames (e.g., to construct video clips for 3D ConvNet filters, to generate enough inputs for LSTMs). For applications that require low-latency online predictions of fast-changing action scenes, a new action recognition system is proposed in this paper. Termed "Weighted Multi-Region Convolutional Neural Network" (WMR ConvNet), the proposed system is LSTM-free, and is based on 2D ConvNet that does not require the accumulation of video frames for 3D ConvNet filtering. Unlike early 2D ConvNets that are based purely on RGB frames and optical flow frames, the WMR ConvNet is designed to simultaneously capture multiple spatial and short term temporal cues (e.g., human poses, occurrences of objects in the background) with both the primary region (foreground) and secondary regions (mostly background). On both the UCF101 and HMDB51 datasets, the proposed WMR ConvNet achieves the state-of-the-art performance among competing low-latency algorithms. Furthermore, WMR ConvNet even outperforms the 3D ConvNet based C3D algorithm that requires video frame accumulation. In an ablation study with the optical flow ConvNet stream removed, the ablated WMR ConvNet nevertheless outperforms competing algorithms.
Visual Attribute-augmented Three-dimensional Convolutional Neural Network for Enhanced Human Action Recognition
May 08, 2018

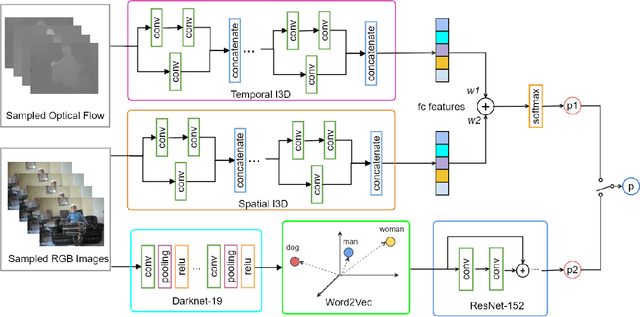
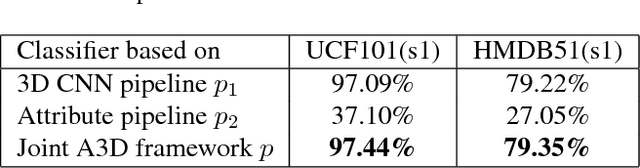
Visual attributes in individual video frames, such as the presence of characteristic objects and scenes, offer substantial information for action recognition in videos. With individual 2D video frame as input, visual attributes extraction could be achieved effectively and efficiently with more sophisticated convolutional neural network than current 3D CNNs with spatio-temporal filters, thanks to fewer parameters in 2D CNNs. In this paper, the integration of visual attributes (including detection, encoding and classification) into multi-stream 3D CNN is proposed for action recognition in trimmed videos, with the proposed visual Attribute-augmented 3D CNN (A3D) framework. The visual attribute pipeline includes an object detection network, an attributes encoding network and a classification network. Our proposed A3D framework achieves state-of-the-art performance on both the HMDB51 and the UCF101 datasets.