 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Paper and Code
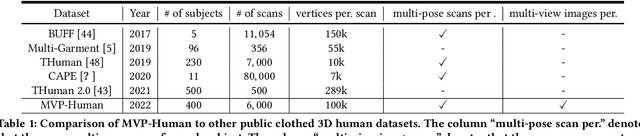
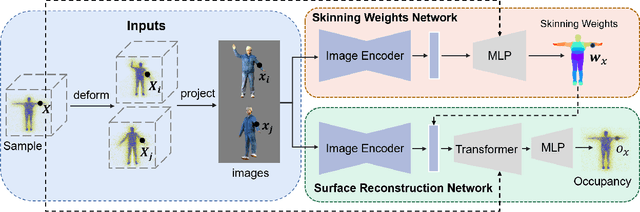
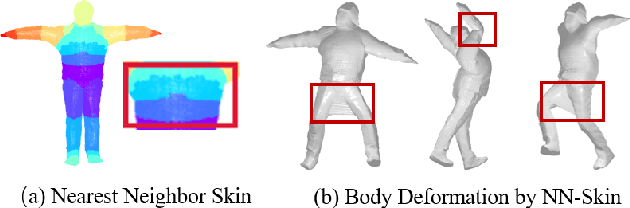
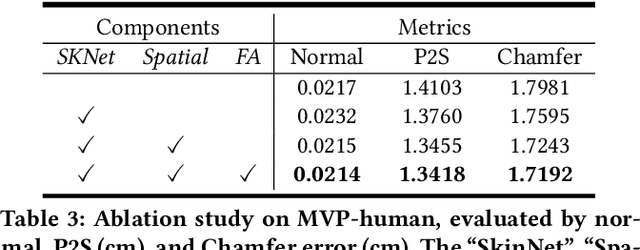
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.