 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Challenger : A Large-scale Dataset for Going Deeper in Image Understanding
Paper and Code

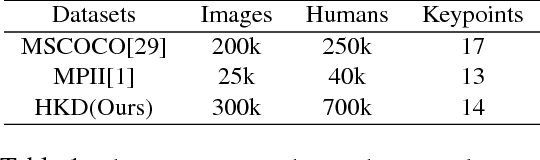
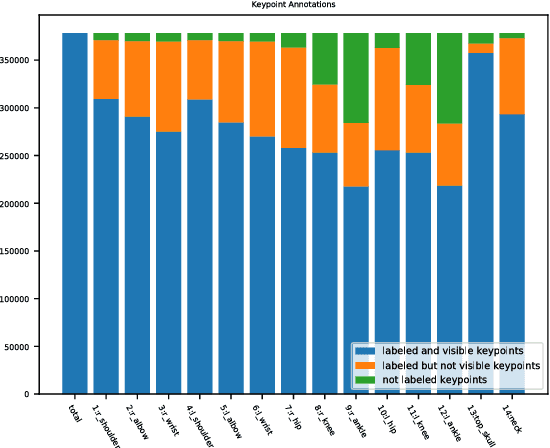
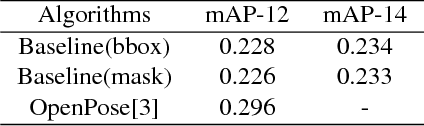
Significant progress has been achieved in Computer Vision by leveraging large-scale image datasets. However, large-scale datasets for complex Computer Vision tasks beyond classification are still limited. This paper proposed a large-scale dataset named AIC (AI Challenger) with three sub-datasets, human keypoint detection (HKD), large-scale attribute dataset (LAD) and image Chinese captioning (ICC). In this dataset, we annotate class labels (LAD), keypoint coordinate (HKD), bounding box (HKD and LAD), attribute (LAD) and caption (ICC). These rich annotations bridge the semantic gap between low-level images and high-level concepts. The proposed dataset is an effective benchmark to evaluate and improve different computational methods. In addition, for related tasks, others can also use our dataset as a new resource to pre-train their models.