 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking-aware Reinforcement Learning for Ordinal Ranking
Jan 28, 2026Ordinal regression and ranking are challenging due to inherent ordinal dependencies that conventional methods struggle to model. We propose Ranking-Aware Reinforcement Learning (RARL), a novel RL framework that explicitly learns these relationships. At its core, RARL features a unified objective that synergistically integrates regression and Learning-to-Rank (L2R), enabling mutual improvement between the two tasks. This is driven by a ranking-aware verifiable reward that jointly assesses regression precision and ranking accuracy, facilitating direct model updates via policy optimization. To further enhance training, we introduce Response Mutation Operations (RMO), which inject controlled noise to improve exploration and prevent stagnation at saddle points. The effectiveness of RARL is validated through extensive experiments on three distinct benchmarks.
Taming Hallucinations: Boosting MLLMs' Video Understanding via Counterfactual Video Generation
Dec 30, 2025Multimodal Large Language Models (MLLMs) have made remarkable progress in video understanding. However, they suffer from a critical vulnerability: an over-reliance on language priors, which can lead to visual ungrounded hallucinations, especially when processing counterfactual videos that defy common sense. This limitation, stemming from the intrinsic data imbalance between text and video, is challenging to address due to the substantial cost of collecting and annotating counterfactual data. To address this, we introduce DualityForge, a novel counterfactual data synthesis framework that employs controllable, diffusion-based video editing to transform real-world videos into counterfactual scenarios. By embedding structured contextual information into the video editing and QA generation processes, the framework automatically produces high-quality QA pairs together with original-edited video pairs for contrastive training. Based on this, we build DualityVidQA, a large-scale video dataset designed to reduce MLLM hallucinations. In addition, to fully exploit the contrastive nature of our paired data, we propose Duality-Normalized Advantage Training (DNA-Train), a two-stage SFT-RL training regime where the RL phase applies pair-wise $\ell_1$ advantage normalization, thereby enabling a more stable and efficient policy optimization. Experiments on DualityVidQA-Test demonstrate that our method substantially reduces model hallucinations on counterfactual videos, yielding a relative improvement of 24.0% over the Qwen2.5-VL-7B baseline. Moreover, our approach achieves significant gains across both hallucination and general-purpose benchmarks, indicating strong generalization capability. We will open-source our dataset and code.
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
Aug 12, 2025Visual effects (VFX) are essential visual enhancements fundamental to modern cinematic production. Although video generation models offer cost-efficient solutions for VFX production, current methods are constrained by per-effect LoRA training, which limits generation to single effects. This fundamental limitation impedes applications that require spatially controllable composite effects, i.e., the concurrent generation of multiple effects at designated locations. However, integrating diverse effects into a unified framework faces major challenges: interference from effect variations and spatial uncontrollability during multi-VFX joint training. To tackle these challenges, we propose Omni-Effects, a first unified framework capable of generating prompt-guided effects and spatially controllable composite effects. The core of our framework comprises two key innovations: (1) LoRA-based Mixture of Experts (LoRA-MoE), which employs a group of expert LoRAs, integrating diverse effects within a unified model while effectively mitigating cross-task interference. (2) Spatial-Aware Prompt (SAP) incorporates spatial mask information into the text token, enabling precise spatial control. Furthermore, we introduce an Independent-Information Flow (IIF) module integrated within the SAP, isolating the control signals corresponding to individual effects to prevent any unwanted blending. To facilitate this research, we construct a comprehensive VFX dataset Omni-VFX via a novel data collection pipeline combining image editing and First-Last Frame-to-Video (FLF2V) synthesis, and introduce a dedicated VFX evaluation framework for validating model performance. Extensive experiments demonstrate that Omni-Effects achieves precise spatial control and diverse effect generation, enabling users to specify both the category and location of desired effects.
VMBench: A Benchmark for Perception-Aligned Video Motion Generation
Mar 13, 2025Video generation has advanced rapidly, improving evaluation methods, yet assessing video's motion remains a major challenge. Specifically, there are two key issues: 1) current motion metrics do not fully align with human perceptions; 2) the existing motion prompts are limited. Based on these findings, we introduce VMBench--a comprehensive Video Motion Benchmark that has perception-aligned motion metrics and features the most diverse types of motion. VMBench has several appealing properties: 1) Perception-Driven Motion Evaluation Metrics, we identify five dimensions based on human perception in motion video assessment and develop fine-grained evaluation metrics, providing deeper insights into models' strengths and weaknesses in motion quality. 2) Meta-Guided Motion Prompt Generation, a structured method that extracts meta-information, generates diverse motion prompts with LLMs, and refines them through human-AI validation, resulting in a multi-level prompt library covering six key dynamic scene dimensions. 3) Human-Aligned Validation Mechanism, we provide human preference annotations to validate our benchmarks, with our metrics achieving an average 35.3% improvement in Spearman's correlation over baseline methods. This is the first time that the quality of motion in videos has been evaluated from the perspective of human perception alignment. Additionally, we will soon release VMBench at https://github.com/GD-AIGC/VMBench, setting a new standard for evaluating and advancing motion generation models.
Visual Alignment Constraint for Continuous Sign Language Recognition
Apr 06, 2021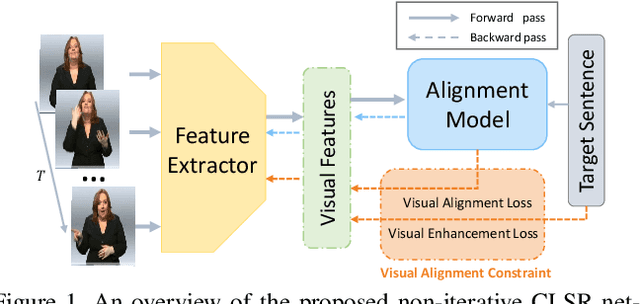

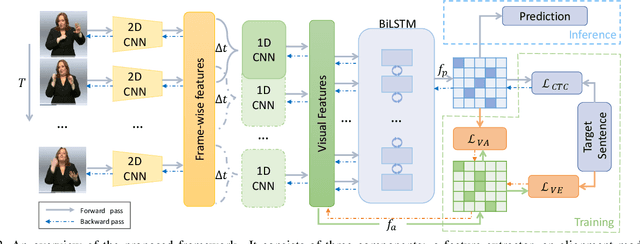
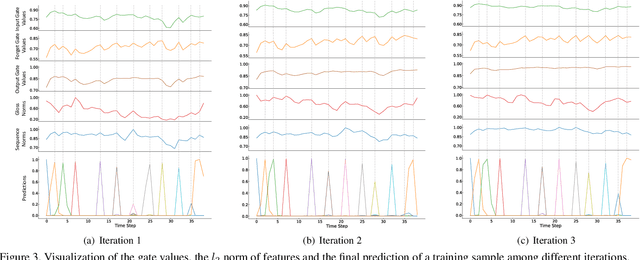
Vision-based Continuous Sign Language Recognition (CSLR) aims to recognize unsegmented gestures from image sequences. To better train CSLR models, the iterative training scheme is widely adopted to alleviate the overfitting of the alignment model. Although the iterative training scheme can improve performance, it will also increase the training time. In this work, we revisit the overfitting problem in recent CTC-based CSLR works and attribute it to the insufficient training of the feature extractor. To solve this problem, we propose a Visual Alignment Constraint (VAC) to enhance the feature extractor with more alignment supervision. Specifically, the proposed VAC is composed of two auxiliary losses: one makes predictions based on visual features only, and the other aligns short-term visual and long-term contextual features. Moreover, we further propose two metrics to evaluate the contributions of the feature extractor and the alignment model, which provide evidence for the overfitting problem. The proposed VAC achieves competitive performance on two challenging CSLR datasets and experimental results show its effectiveness.