 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSM: Small but Powerful Biological Sequence Model for Genes and Proteins
Oct 15, 2024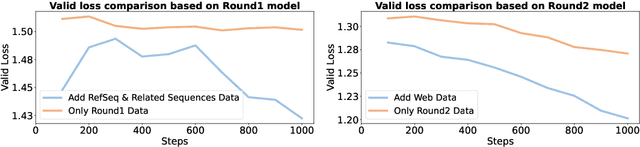

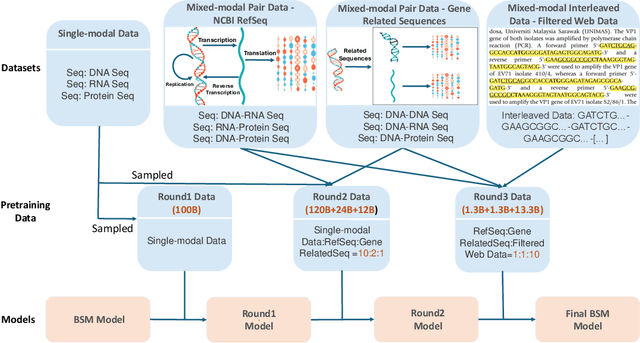
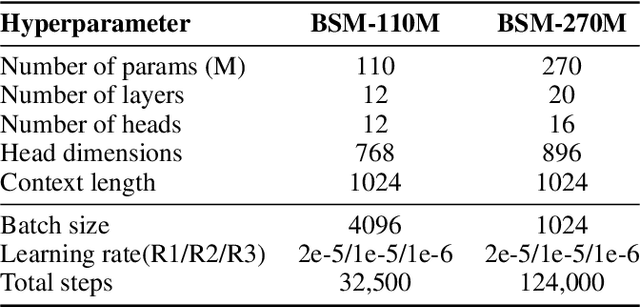
Modeling biological sequences such as DNA, RNA, and proteins is crucial for understanding complex processes like gene regulation and protein synthesis. However, most current models either focus on a single type or treat multiple types of data separately, limiting their ability to capture cross-modal relationships. We propose that by learning the relationships between these modalities, the model can enhance its understanding of each type. To address this, we introduce BSM, a small but powerful mixed-modal biological sequence foundation model, trained on three types of data: RefSeq, Gene Related Sequences, and interleaved biological sequences from the web. These datasets capture the genetic flow, gene-protein relationships, and the natural co-occurrence of diverse biological data, respectively. By training on mixed-modal data, BSM significantly enhances learning efficiency and cross-modal representation, outperforming models trained solely on unimodal data. With only 110M parameters, BSM achieves performance comparable to much larger models across both single-modal and mixed-modal tasks, and uniquely demonstrates in-context learning capability for mixed-modal tasks, which is absent in existing models. Further scaling to 270M parameters demonstrates even greater performance gains, highlighting the potential of BSM as a significant advancement in multimodal biological sequence modeling.
Visual Alignment Constraint for Continuous Sign Language Recognition
Apr 06, 2021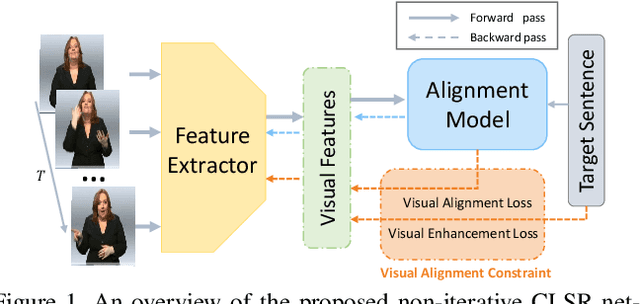

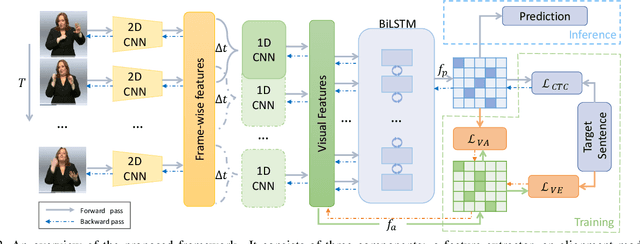
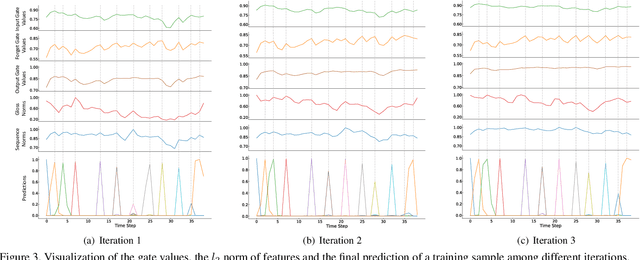
Vision-based Continuous Sign Language Recognition (CSLR) aims to recognize unsegmented gestures from image sequences. To better train CSLR models, the iterative training scheme is widely adopted to alleviate the overfitting of the alignment model. Although the iterative training scheme can improve performance, it will also increase the training time. In this work, we revisit the overfitting problem in recent CTC-based CSLR works and attribute it to the insufficient training of the feature extractor. To solve this problem, we propose a Visual Alignment Constraint (VAC) to enhance the feature extractor with more alignment supervision. Specifically, the proposed VAC is composed of two auxiliary losses: one makes predictions based on visual features only, and the other aligns short-term visual and long-term contextual features. Moreover, we further propose two metrics to evaluate the contributions of the feature extractor and the alignment model, which provide evidence for the overfitting problem. The proposed VAC achieves competitive performance on two challenging CSLR datasets and experimental results show its effectiveness.