 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-WorldBench: Towards a Comprehensive Interaction-Centric Evaluation for World Models
Mar 23, 2026Video--based world models have emerged along two dominant paradigms: video generation and 3D reconstruction. However, existing evaluation benchmarks either focus narrowly on visual fidelity and text--video alignment for generative models, or rely on static 3D reconstruction metrics that fundamentally neglect temporal dynamics. We argue that the future of world modeling lies in 4D generation, which jointly models spatial structure and temporal evolution. In this paradigm, the core capability is interactive response: the ability to faithfully reflect how interaction actions drive state transitions across space and time. Yet no existing benchmark systematically evaluates this critical dimension. To address this gap, we propose Omni--WorldBench, a comprehensive benchmark specifically designed to evaluate the interactive response capabilities of world models in 4D settings. Omni--WorldBench comprises two key components: Omni--WorldSuite, a systematic prompt suite spanning diverse interaction levels and scene types; and Omni--Metrics, an agent-based evaluation framework that quantifies world modeling capabilities by measuring the causal impact of interaction actions on both final outcomes and intermediate state evolution trajectories. We conduct extensive evaluations of 18 representative world models across multiple paradigms. Our analysis reveals critical limitations of current world models in interactive response, providing actionable insights for future research. Omni-WorldBench will be publicly released to foster progress in interactive 4D world modeling.
Latent Temporal Discrepancy as Motion Prior: A Loss-Weighting Strategy for Dynamic Fidelity in T2V
Jan 28, 2026Video generation models have achieved notable progress in static scenarios, yet their performance in motion video generation remains limited, with quality degrading under drastic dynamic changes. This is due to noise disrupting temporal coherence and increasing the difficulty of learning dynamic regions. {Unfortunately, existing diffusion models rely on static loss for all scenarios, constraining their ability to capture complex dynamics.} To address this issue, we introduce Latent Temporal Discrepancy (LTD) as a motion prior to guide loss weighting. LTD measures frame-to-frame variation in the latent space, assigning larger penalties to regions with higher discrepancy while maintaining regular optimization for stable regions. This motion-aware strategy stabilizes training and enables the model to better reconstruct high-frequency dynamics. Extensive experiments on the general benchmark VBench and the motion-focused VMBench show consistent gains, with our method outperforming strong baselines by 3.31% on VBench and 3.58% on VMBench, achieving significant improvements in motion quality.
Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
Aug 12, 2025Visual effects (VFX) are essential visual enhancements fundamental to modern cinematic production. Although video generation models offer cost-efficient solutions for VFX production, current methods are constrained by per-effect LoRA training, which limits generation to single effects. This fundamental limitation impedes applications that require spatially controllable composite effects, i.e., the concurrent generation of multiple effects at designated locations. However, integrating diverse effects into a unified framework faces major challenges: interference from effect variations and spatial uncontrollability during multi-VFX joint training. To tackle these challenges, we propose Omni-Effects, a first unified framework capable of generating prompt-guided effects and spatially controllable composite effects. The core of our framework comprises two key innovations: (1) LoRA-based Mixture of Experts (LoRA-MoE), which employs a group of expert LoRAs, integrating diverse effects within a unified model while effectively mitigating cross-task interference. (2) Spatial-Aware Prompt (SAP) incorporates spatial mask information into the text token, enabling precise spatial control. Furthermore, we introduce an Independent-Information Flow (IIF) module integrated within the SAP, isolating the control signals corresponding to individual effects to prevent any unwanted blending. To facilitate this research, we construct a comprehensive VFX dataset Omni-VFX via a novel data collection pipeline combining image editing and First-Last Frame-to-Video (FLF2V) synthesis, and introduce a dedicated VFX evaluation framework for validating model performance. Extensive experiments demonstrate that Omni-Effects achieves precise spatial control and diverse effect generation, enabling users to specify both the category and location of desired effects.
VMBench: A Benchmark for Perception-Aligned Video Motion Generation
Mar 13, 2025



Video generation has advanced rapidly, improving evaluation methods, yet assessing video's motion remains a major challenge. Specifically, there are two key issues: 1) current motion metrics do not fully align with human perceptions; 2) the existing motion prompts are limited. Based on these findings, we introduce VMBench--a comprehensive Video Motion Benchmark that has perception-aligned motion metrics and features the most diverse types of motion. VMBench has several appealing properties: 1) Perception-Driven Motion Evaluation Metrics, we identify five dimensions based on human perception in motion video assessment and develop fine-grained evaluation metrics, providing deeper insights into models' strengths and weaknesses in motion quality. 2) Meta-Guided Motion Prompt Generation, a structured method that extracts meta-information, generates diverse motion prompts with LLMs, and refines them through human-AI validation, resulting in a multi-level prompt library covering six key dynamic scene dimensions. 3) Human-Aligned Validation Mechanism, we provide human preference annotations to validate our benchmarks, with our metrics achieving an average 35.3% improvement in Spearman's correlation over baseline methods. This is the first time that the quality of motion in videos has been evaluated from the perspective of human perception alignment. Additionally, we will soon release VMBench at https://github.com/GD-AIGC/VMBench, setting a new standard for evaluating and advancing motion generation models.
How Texts Help? A Fine-grained Evaluation to Reveal the Role of Language in Vision-Language Tracking
Nov 23, 2024



Vision-language tracking (VLT) extends traditional single object tracking by incorporating textual information, providing semantic guidance to enhance tracking performance under challenging conditions like fast motion and deformations. However, current VLT trackers often underperform compared to single-modality methods on multiple benchmarks, with semantic information sometimes becoming a "distraction." To address this, we propose VLTVerse, the first fine-grained evaluation framework for VLT trackers that comprehensively considers multiple challenge factors and diverse semantic information, hoping to reveal the role of language in VLT. Our contributions include: (1) VLTVerse introduces 10 sequence-level challenge labels and 6 types of multi-granularity semantic information, creating a flexible and multi-dimensional evaluation space for VLT; (2) leveraging 60 subspaces formed by combinations of challenge factors and semantic types, we conduct systematic fine-grained evaluations of three mainstream SOTA VLT trackers, uncovering their performance bottlenecks across complex scenarios and offering a novel perspective on VLT evaluation; (3) through decoupled analysis of experimental results, we examine the impact of various semantic types on specific challenge factors in relation to different algorithms, providing essential guidance for enhancing VLT across data, evaluation, and algorithmic dimensions. The VLTVerse, toolkit, and results will be available at \url{http://metaverse.aitestunion.com}.
DTVLT: A Multi-modal Diverse Text Benchmark for Visual Language Tracking Based on LLM
Oct 03, 2024



Visual language tracking (VLT) has emerged as a cutting-edge research area, harnessing linguistic data to enhance algorithms with multi-modal inputs and broadening the scope of traditional single object tracking (SOT) to encompass video understanding applications. Despite this, most VLT benchmarks still depend on succinct, human-annotated text descriptions for each video. These descriptions often fall short in capturing the nuances of video content dynamics and lack stylistic variety in language, constrained by their uniform level of detail and a fixed annotation frequency. As a result, algorithms tend to default to a "memorize the answer" strategy, diverging from the core objective of achieving a deeper understanding of video content. Fortunately, the emergence of large language models (LLMs) has enabled the generation of diverse text. This work utilizes LLMs to generate varied semantic annotations (in terms of text lengths and granularities) for representative SOT benchmarks, thereby establishing a novel multi-modal benchmark. Specifically, we (1) propose a new visual language tracking benchmark with diverse texts, named DTVLT, based on five prominent VLT and SOT benchmarks, including three sub-tasks: short-term tracking, long-term tracking, and global instance tracking. (2) We offer four granularity texts in our benchmark, considering the extent and density of semantic information. We expect this multi-granular generation strategy to foster a favorable environment for VLT and video understanding research. (3) We conduct comprehensive experimental analyses on DTVLT, evaluating the impact of diverse text on tracking performance and hope the identified performance bottlenecks of existing algorithms can support further research in VLT and video understanding. The proposed benchmark, experimental results and toolkit will be released gradually on http://videocube.aitestunion.com/.
Visual Language Tracking with Multi-modal Interaction: A Robust Benchmark
Sep 13, 2024


Visual Language Tracking (VLT) enhances tracking by mitigating the limitations of relying solely on the visual modality, utilizing high-level semantic information through language. This integration of the language enables more advanced human-machine interaction. The essence of interaction is cognitive alignment, which typically requires multiple information exchanges, especially in the sequential decision-making process of VLT. However, current VLT benchmarks do not account for multi-round interactions during tracking. They provide only an initial text and bounding box (bbox) in the first frame, with no further interaction as tracking progresses, deviating from the original motivation of the VLT task. To address these limitations, we propose a novel and robust benchmark, VLT-MI (Visual Language Tracking with Multi-modal Interaction), which introduces multi-round interaction into the VLT task for the first time. (1) We generate diverse, multi-granularity texts for multi-round, multi-modal interaction based on existing mainstream VLT benchmarks using DTLLM-VLT, leveraging the world knowledge of LLMs. (2) We propose a new VLT interaction paradigm that achieves multi-round interaction through text updates and object recovery. When multiple tracking failures occur, we provide the tracker with more aligned texts and corrected bboxes through interaction, thereby expanding the scope of VLT downstream tasks. (3) We conduct comparative experiments on both traditional VLT benchmarks and VLT-MI, evaluating and analyzing the accuracy and robustness of trackers under the interactive paradigm. This work offers new insights and paradigms for the VLT task, enabling a fine-grained evaluation of multi-modal trackers. We believe this approach can be extended to additional datasets in the future, supporting broader evaluations and comparisons of video-language model capabilities.
Revealing the Dark Secrets of Extremely Large Kernel ConvNets on Robustness
Jul 12, 2024



Robustness is a vital aspect to consider when deploying deep learning models into the wild. Numerous studies have been dedicated to the study of the robustness of vision transformers (ViTs), which have dominated as the mainstream backbone choice for vision tasks since the dawn of 2020s. Recently, some large kernel convnets make a comeback with impressive performance and efficiency. However, it still remains unclear whether large kernel networks are robust and the attribution of their robustness. In this paper, we first conduct a comprehensive evaluation of large kernel convnets' robustness and their differences from typical small kernel counterparts and ViTs on six diverse robustness benchmark datasets. Then to analyze the underlying factors behind their strong robustness, we design experiments from both quantitative and qualitative perspectives to reveal large kernel convnets' intriguing properties that are completely different from typical convnets. Our experiments demonstrate for the first time that pure CNNs can achieve exceptional robustness comparable or even superior to that of ViTs. Our analysis on occlusion invariance, kernel attention patterns and frequency characteristics provide novel insights into the source of robustness.
DTLLM-VLT: Diverse Text Generation for Visual Language Tracking Based on LLM
May 20, 2024Visual Language Tracking (VLT) enhances single object tracking (SOT) by integrating natural language descriptions from a video, for the precise tracking of a specified object. By leveraging high-level semantic information, VLT guides object tracking, alleviating the constraints associated with relying on a visual modality. Nevertheless, most VLT benchmarks are annotated in a single granularity and lack a coherent semantic framework to provide scientific guidance. Moreover, coordinating human annotators for high-quality annotations is laborious and time-consuming. To address these challenges, we introduce DTLLM-VLT, which automatically generates extensive and multi-granularity text to enhance environmental diversity. (1) DTLLM-VLT generates scientific and multi-granularity text descriptions using a cohesive prompt framework. Its succinct and highly adaptable design allows seamless integration into various visual tracking benchmarks. (2) We select three prominent benchmarks to deploy our approach: short-term tracking, long-term tracking, and global instance tracking. We offer four granularity combinations for these benchmarks, considering the extent and density of semantic information, thereby showcasing the practicality and versatility of DTLLM-VLT. (3) We conduct comparative experiments on VLT benchmarks with different text granularities, evaluating and analyzing the impact of diverse text on tracking performance. Conclusionally, this work leverages LLM to provide multi-granularity semantic information for VLT task from efficient and diverse perspectives, enabling fine-grained evaluation of multi-modal trackers. In the future, we believe this work can be extended to more datasets to support vision datasets understanding.
See Your Heart: Psychological states Interpretation through Visual Creations
Feb 11, 2023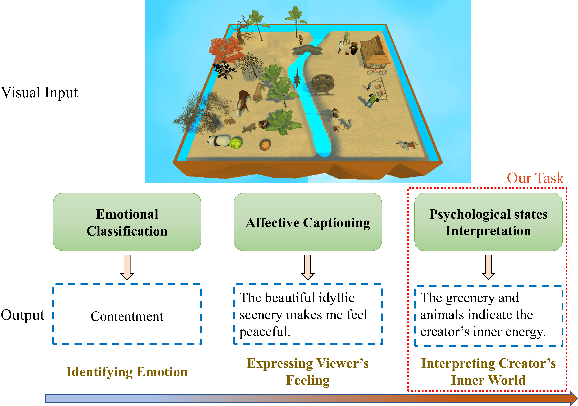

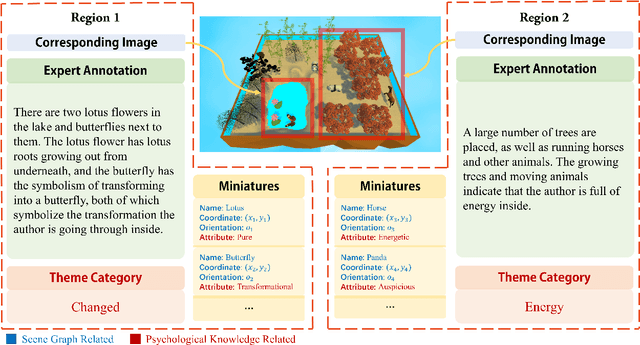

In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.