 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee Your Heart: Psychological states Interpretation through Visual Creations
Paper and Code
Feb 11, 2023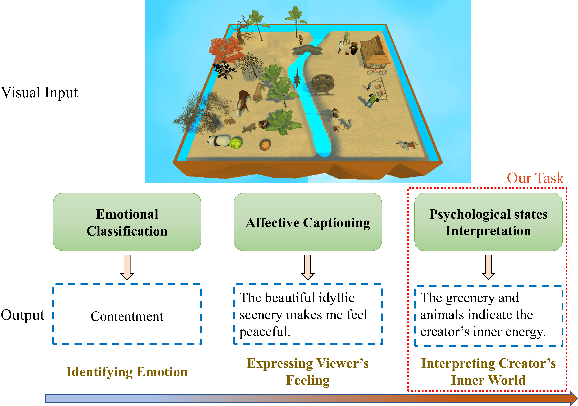

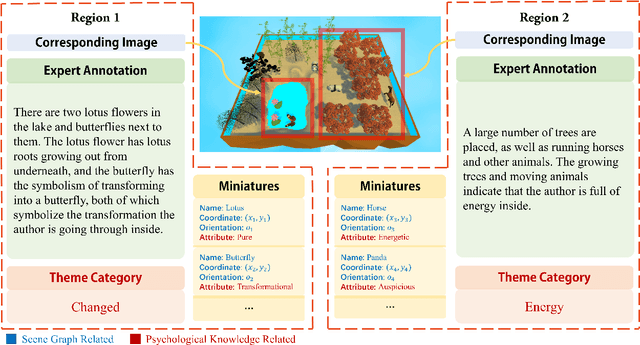

In psychoanalysis, generating interpretations to one's psychological state through visual creations is facing significant demands. The two main tasks of existing studies in the field of computer vision, sentiment/emotion classification and affective captioning, can hardly satisfy the requirement of psychological interpreting. To meet the demands for psychoanalysis, we introduce a challenging task, \textbf{V}isual \textbf{E}motion \textbf{I}nterpretation \textbf{T}ask (VEIT). VEIT requires AI to generate reasonable interpretations of creator's psychological state through visual creations. To support the task, we present a multimodal dataset termed SpyIn (\textbf{S}and\textbf{p}la\textbf{y} \textbf{In}terpretation Dataset), which is psychological theory supported and professional annotated. Dataset analysis illustrates that SpyIn is not only able to support VEIT, but also more challenging compared with other captioning datasets. Building on SpyIn, we conduct experiments of several image captioning method, and propose a visual-semantic combined model which obtains a SOTA result on SpyIn. The results indicate that VEIT is a more challenging task requiring scene graph information and psychological knowledge. Our work also show a promise for AI to analyze and explain inner world of humanity through visual creations.