 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Flatland to Space: Teaching Vision-Language Models to Perceive and Reason in 3D
Mar 29, 2025
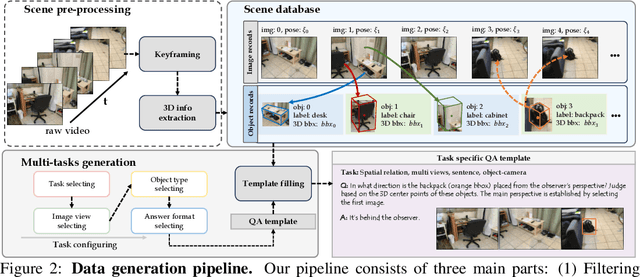
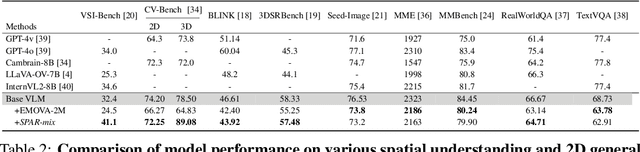

Recent advances in LVLMs have improved vision-language understanding, but they still struggle with spatial perception, limiting their ability to reason about complex 3D scenes. Unlike previous approaches that incorporate 3D representations into models to improve spatial understanding, we aim to unlock the potential of VLMs by leveraging spatially relevant image data. To this end, we introduce a novel 2D spatial data generation and annotation pipeline built upon scene data with 3D ground-truth. This pipeline enables the creation of a diverse set of spatial tasks, ranging from basic perception tasks to more complex reasoning tasks. Leveraging this pipeline, we construct SPAR-7M, a large-scale dataset generated from thousands of scenes across multiple public datasets. In addition, we introduce SPAR-Bench, a benchmark designed to offer a more comprehensive evaluation of spatial capabilities compared to existing spatial benchmarks, supporting both single-view and multi-view inputs. Training on both SPAR-7M and large-scale 2D datasets enables our models to achieve state-of-the-art performance on 2D spatial benchmarks. Further fine-tuning on 3D task-specific datasets yields competitive results, underscoring the effectiveness of our dataset in enhancing spatial reasoning.
DG-SLAM: Robust Dynamic Gaussian Splatting SLAM with Hybrid Pose Optimization
Nov 13, 2024



Achieving robust and precise pose estimation in dynamic scenes is a significant research challenge in Visual Simultaneous Localization and Mapping (SLAM). Recent advancements integrating Gaussian Splatting into SLAM systems have proven effective in creating high-quality renderings using explicit 3D Gaussian models, significantly improving environmental reconstruction fidelity. However, these approaches depend on a static environment assumption and face challenges in dynamic environments due to inconsistent observations of geometry and photometry. To address this problem, we propose DG-SLAM, the first robust dynamic visual SLAM system grounded in 3D Gaussians, which provides precise camera pose estimation alongside high-fidelity reconstructions. Specifically, we propose effective strategies, including motion mask generation, adaptive Gaussian point management, and a hybrid camera tracking algorithm to improve the accuracy and robustness of pose estimation. Extensive experiments demonstrate that DG-SLAM delivers state-of-the-art performance in camera pose estimation, map reconstruction, and novel-view synthesis in dynamic scenes, outperforming existing methods meanwhile preserving real-time rendering ability.
RoDyn-SLAM: Robust Dynamic Dense RGB-D SLAM with Neural Radiance Fields
Jul 01, 2024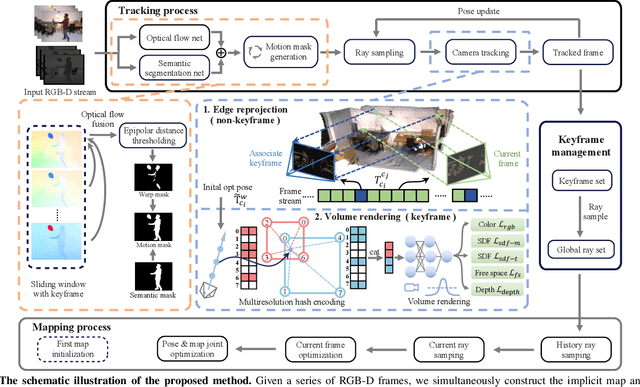
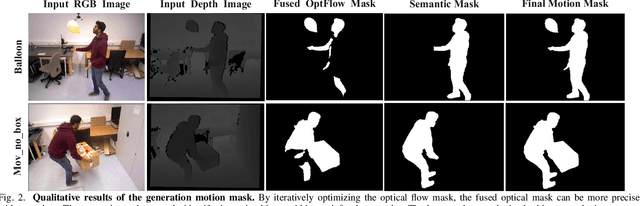


Leveraging neural implicit representation to conduct dense RGB-D SLAM has been studied in recent years. However, this approach relies on a static environment assumption and does not work robustly within a dynamic environment due to the inconsistent observation of geometry and photometry. To address the challenges presented in dynamic environments, we propose a novel dynamic SLAM framework with neural radiance field. Specifically, we introduce a motion mask generation method to filter out the invalid sampled rays. This design effectively fuses the optical flow mask and semantic mask to enhance the precision of motion mask. To further improve the accuracy of pose estimation, we have designed a divide-and-conquer pose optimization algorithm that distinguishes between keyframes and non-keyframes. The proposed edge warp loss can effectively enhance the geometry constraints between adjacent frames. Extensive experiments are conducted on the two challenging datasets, and the results show that RoDyn-SLAM achieves state-of-the-art performance among recent neural RGB-D methods in both accuracy and robustness.
OpenOcc: Open Vocabulary 3D Scene Reconstruction via Occupancy Representation
Mar 18, 20243D reconstruction has been widely used in autonomous navigation fields of mobile robotics. However, the former research can only provide the basic geometry structure without the capability of open-world scene understanding, limiting advanced tasks like human interaction and visual navigation. Moreover, traditional 3D scene understanding approaches rely on expensive labeled 3D datasets to train a model for a single task with supervision. Thus, geometric reconstruction with zero-shot scene understanding i.e. Open vocabulary 3D Understanding and Reconstruction, is crucial for the future development of mobile robots. In this paper, we propose OpenOcc, a novel framework unifying the 3D scene reconstruction and open vocabulary understanding with neural radiance fields. We model the geometric structure of the scene with occupancy representation and distill the pre-trained open vocabulary model into a 3D language field via volume rendering for zero-shot inference. Furthermore, a novel semantic-aware confidence propagation (SCP) method has been proposed to relieve the issue of language field representation degeneracy caused by inconsistent measurements in distilled features. Experimental results show that our approach achieves competitive performance in 3D scene understanding tasks, especially for small and long-tail objects.