 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
CroBIM-U: Uncertainty-Driven Referring Remote Sensing Image Segmentation
Jan 07, 2026Referring remote sensing image segmentation aims to localize specific targets described by natural language within complex overhead imagery. However, due to extreme scale variations, dense similar distractors, and intricate boundary structures, the reliability of cross-modal alignment exhibits significant \textbf{spatial non-uniformity}. Existing methods typically employ uniform fusion and refinement strategies across the entire image, which often introduces unnecessary linguistic perturbations in visually clear regions while failing to provide sufficient disambiguation in confused areas. To address this, we propose an \textbf{uncertainty-guided framework} that explicitly leverages a pixel-wise \textbf{referring uncertainty map} as a spatial prior to orchestrate adaptive inference. Specifically, we introduce a plug-and-play \textbf{Referring Uncertainty Scorer (RUS)}, which is trained via an online error-consistency supervision strategy to interpretably predict the spatial distribution of referential ambiguity. Building on this prior, we design two plug-and-play modules: 1) \textbf{Uncertainty-Gated Fusion (UGF)}, which dynamically modulates language injection strength to enhance constraints in high-uncertainty regions while suppressing noise in low-uncertainty ones; and 2) \textbf{Uncertainty-Driven Local Refinement (UDLR)}, which utilizes uncertainty-derived soft masks to focus refinement on error-prone boundaries and fine details. Extensive experiments demonstrate that our method functions as a unified, plug-and-play solution that significantly improves robustness and geometric fidelity in complex remote sensing scenes without altering the backbone architecture.
DG-SLAM: Robust Dynamic Gaussian Splatting SLAM with Hybrid Pose Optimization
Nov 13, 2024



Achieving robust and precise pose estimation in dynamic scenes is a significant research challenge in Visual Simultaneous Localization and Mapping (SLAM). Recent advancements integrating Gaussian Splatting into SLAM systems have proven effective in creating high-quality renderings using explicit 3D Gaussian models, significantly improving environmental reconstruction fidelity. However, these approaches depend on a static environment assumption and face challenges in dynamic environments due to inconsistent observations of geometry and photometry. To address this problem, we propose DG-SLAM, the first robust dynamic visual SLAM system grounded in 3D Gaussians, which provides precise camera pose estimation alongside high-fidelity reconstructions. Specifically, we propose effective strategies, including motion mask generation, adaptive Gaussian point management, and a hybrid camera tracking algorithm to improve the accuracy and robustness of pose estimation. Extensive experiments demonstrate that DG-SLAM delivers state-of-the-art performance in camera pose estimation, map reconstruction, and novel-view synthesis in dynamic scenes, outperforming existing methods meanwhile preserving real-time rendering ability.
RoDyn-SLAM: Robust Dynamic Dense RGB-D SLAM with Neural Radiance Fields
Jul 01, 2024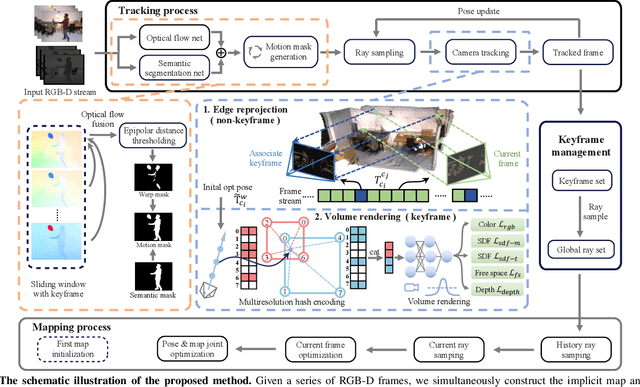
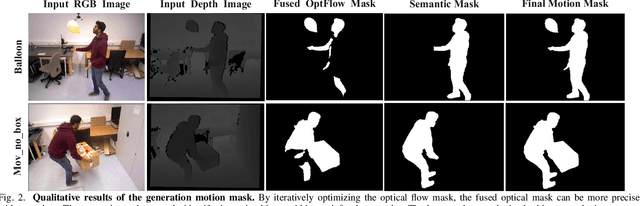


Leveraging neural implicit representation to conduct dense RGB-D SLAM has been studied in recent years. However, this approach relies on a static environment assumption and does not work robustly within a dynamic environment due to the inconsistent observation of geometry and photometry. To address the challenges presented in dynamic environments, we propose a novel dynamic SLAM framework with neural radiance field. Specifically, we introduce a motion mask generation method to filter out the invalid sampled rays. This design effectively fuses the optical flow mask and semantic mask to enhance the precision of motion mask. To further improve the accuracy of pose estimation, we have designed a divide-and-conquer pose optimization algorithm that distinguishes between keyframes and non-keyframes. The proposed edge warp loss can effectively enhance the geometry constraints between adjacent frames. Extensive experiments are conducted on the two challenging datasets, and the results show that RoDyn-SLAM achieves state-of-the-art performance among recent neural RGB-D methods in both accuracy and robustness.
OpenOcc: Open Vocabulary 3D Scene Reconstruction via Occupancy Representation
Mar 18, 20243D reconstruction has been widely used in autonomous navigation fields of mobile robotics. However, the former research can only provide the basic geometry structure without the capability of open-world scene understanding, limiting advanced tasks like human interaction and visual navigation. Moreover, traditional 3D scene understanding approaches rely on expensive labeled 3D datasets to train a model for a single task with supervision. Thus, geometric reconstruction with zero-shot scene understanding i.e. Open vocabulary 3D Understanding and Reconstruction, is crucial for the future development of mobile robots. In this paper, we propose OpenOcc, a novel framework unifying the 3D scene reconstruction and open vocabulary understanding with neural radiance fields. We model the geometric structure of the scene with occupancy representation and distill the pre-trained open vocabulary model into a 3D language field via volume rendering for zero-shot inference. Furthermore, a novel semantic-aware confidence propagation (SCP) method has been proposed to relieve the issue of language field representation degeneracy caused by inconsistent measurements in distilled features. Experimental results show that our approach achieves competitive performance in 3D scene understanding tasks, especially for small and long-tail objects.
NaSGEC: a Multi-Domain Chinese Grammatical Error Correction Dataset from Native Speaker Texts
May 25, 2023



We introduce NaSGEC, a new dataset to facilitate research on Chinese grammatical error correction (CGEC) for native speaker texts from multiple domains. Previous CGEC research primarily focuses on correcting texts from a single domain, especially learner essays. To broaden the target domain, we annotate multiple references for 12,500 sentences from three native domains, i.e., social media, scientific writing, and examination. We provide solid benchmark results for NaSGEC by employing cutting-edge CGEC models and different training data. We further perform detailed analyses of the connections and gaps between our domains from both empirical and statistical views. We hope this work can inspire future studies on an important but under-explored direction--cross-domain GEC.
Mining Error Templates for Grammatical Error Correction
Jun 23, 2022
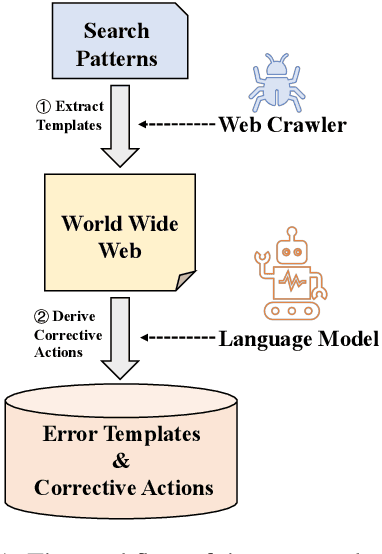

Some grammatical error correction (GEC) systems incorporate hand-crafted rules and achieve positive results. However, manually defining rules is time-consuming and laborious. In view of this, we propose a method to mine error templates for GEC automatically. An error template is a regular expression aiming at identifying text errors. We use the web crawler to acquire such error templates from the Internet. For each template, we further select the corresponding corrective action by using the language model perplexity as a criterion. We have accumulated 1,119 error templates for Chinese GEC based on this method. Experimental results on the newly proposed CTC-2021 Chinese GEC benchmark show that combing our error templates can effectively improve the performance of a strong GEC system, especially on two error types with very little training data. Our error templates are available at \url{https://github.com/HillZhang1999/gec_error_template}.