 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynGEC: Syntax-Enhanced Grammatical Error Correction with a Tailored GEC-Oriented Parser
Oct 22, 2022This work proposes a syntax-enhanced grammatical error correction (GEC) approach named SynGEC that effectively incorporates dependency syntactic information into the encoder part of GEC models. The key challenge for this idea is that off-the-shelf parsers are unreliable when processing ungrammatical sentences. To confront this challenge, we propose to build a tailored GEC-oriented parser (GOPar) using parallel GEC training data as a pivot. First, we design an extended syntax representation scheme that allows us to represent both grammatical errors and syntax in a unified tree structure. Then, we obtain parse trees of the source incorrect sentences by projecting trees of the target correct sentences. Finally, we train GOPar with such projected trees. For GEC, we employ the graph convolution network to encode source-side syntactic information produced by GOPar, and fuse them with the outputs of the Transformer encoder. Experiments on mainstream English and Chinese GEC datasets show that our proposed SynGEC approach consistently and substantially outperforms strong baselines and achieves competitive performance. Our code and data are all publicly available at https://github.com/HillZhang1999/SynGEC.
Mining Error Templates for Grammatical Error Correction
Jun 23, 2022
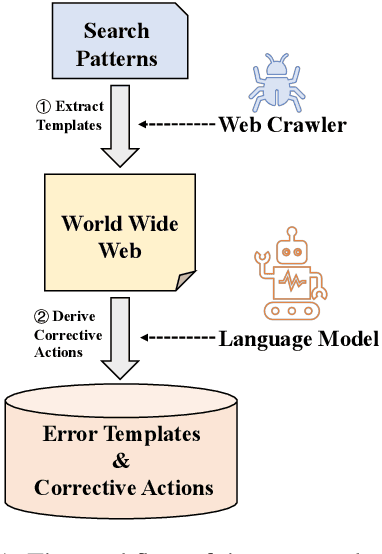

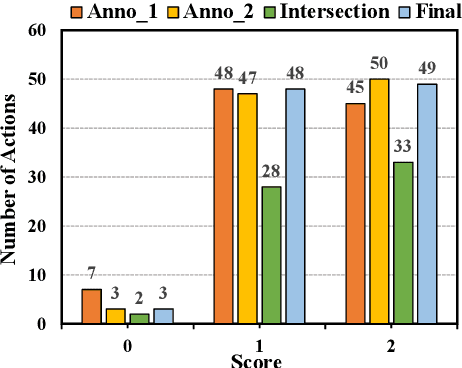
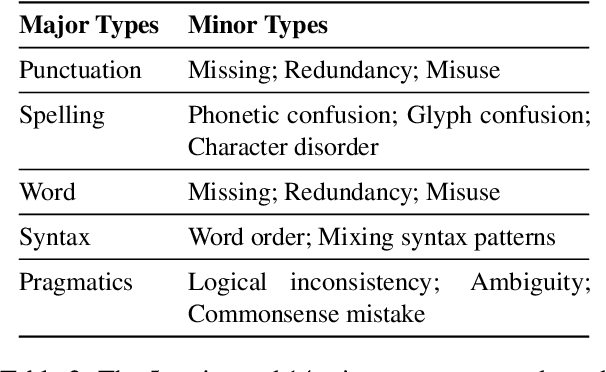
Some grammatical error correction (GEC) systems incorporate hand-crafted rules and achieve positive results. However, manually defining rules is time-consuming and laborious. In view of this, we propose a method to mine error templates for GEC automatically. An error template is a regular expression aiming at identifying text errors. We use the web crawler to acquire such error templates from the Internet. For each template, we further select the corresponding corrective action by using the language model perplexity as a criterion. We have accumulated 1,119 error templates for Chinese GEC based on this method. Experimental results on the newly proposed CTC-2021 Chinese GEC benchmark show that combing our error templates can effectively improve the performance of a strong GEC system, especially on two error types with very little training data. Our error templates are available at \url{https://github.com/HillZhang1999/gec_error_template}.
MuCGEC: a Multi-Reference Multi-Source Evaluation Dataset for Chinese Grammatical Error Correction
May 04, 2022
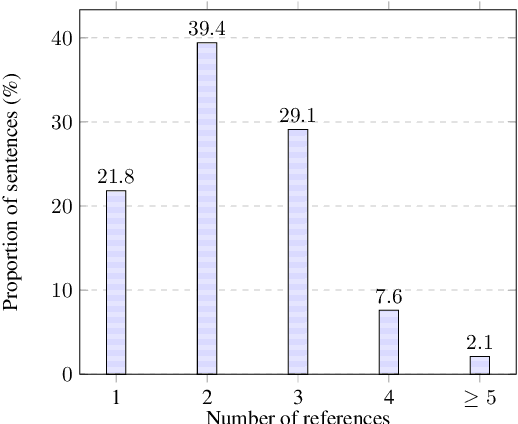
This paper presents MuCGEC, a multi-reference multi-source evaluation dataset for Chinese Grammatical Error Correction (CGEC), consisting of 7,063 sentences collected from three Chinese-as-a-Second-Language (CSL) learner sources. Each sentence is corrected by three annotators, and their corrections are carefully reviewed by a senior annotator, resulting in 2.3 references per sentence. We conduct experiments with two mainstream CGEC models, i.e., the sequence-to-sequence model and the sequence-to-edit model, both enhanced with large pretrained language models, achieving competitive benchmark performance on previous and our datasets. We also discuss CGEC evaluation methodologies, including the effect of multiple references and using a char-based metric. Our annotation guidelines, data, and code are available at \url{https://github.com/HillZhang1999/MuCGEC}.
Entity Relation Extraction as Dependency Parsing in Visually Rich Documents
Oct 19, 2021
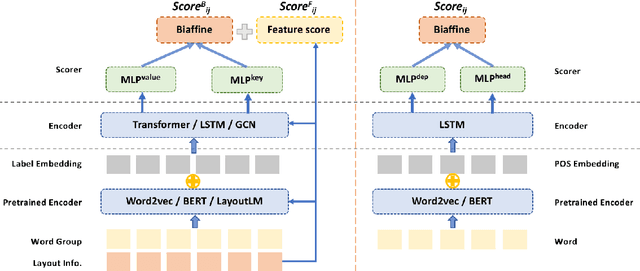
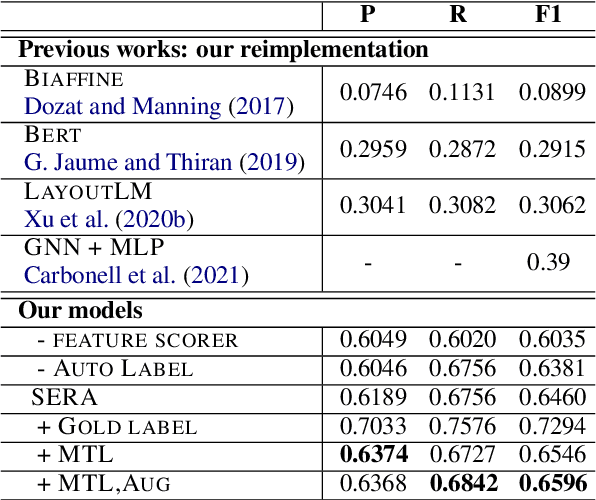
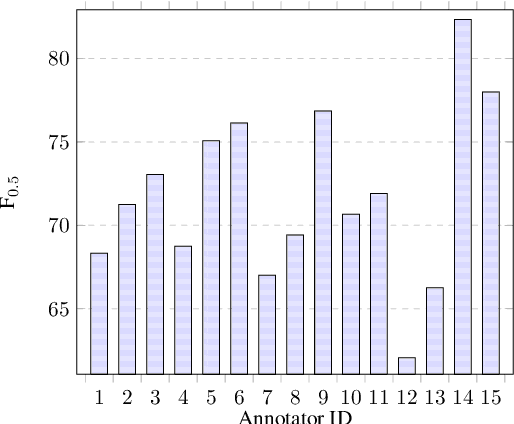
Previous works on key information extraction from visually rich documents (VRDs) mainly focus on labeling the text within each bounding box (i.e., semantic entity), while the relations in-between are largely unexplored. In this paper, we adapt the popular dependency parsing model, the biaffine parser, to this entity relation extraction task. Being different from the original dependency parsing model which recognizes dependency relations between words, we identify relations between groups of words with layout information instead. We have compared different representations of the semantic entity, different VRD encoders, and different relation decoders. The results demonstrate that our proposed model achieves 65.96% F1 score on the FUNSD dataset. As for the real-world application, our model has been applied to the in-house customs data, achieving reliable performance in the production setting.
Low-Resource Sequence Labeling via Unsupervised Multilingual Contextualized Representations
Oct 24, 2019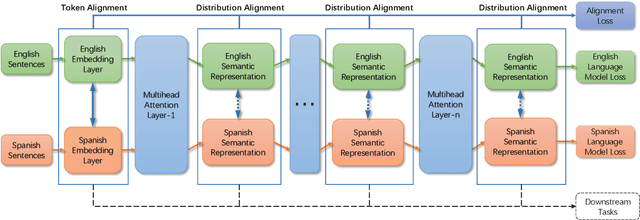
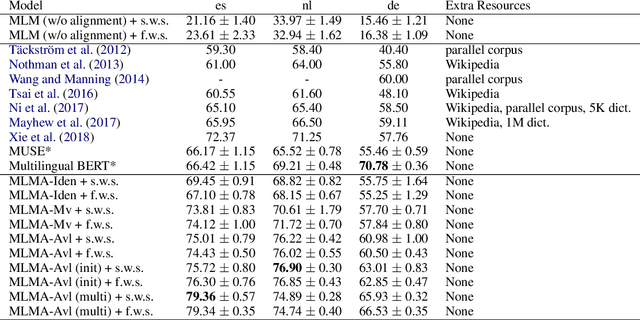
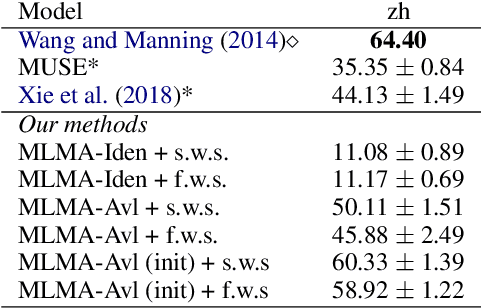
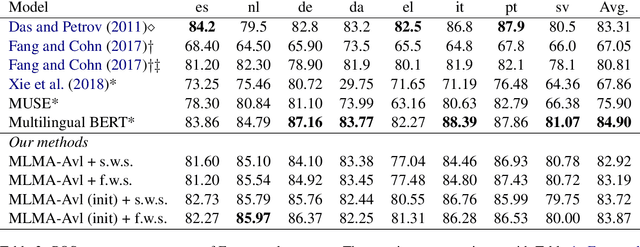
Previous work on cross-lingual sequence labeling tasks either requires parallel data or bridges the two languages through word-byword matching. Such requirements and assumptions are infeasible for most languages, especially for languages with large linguistic distances, e.g., English and Chinese. In this work, we propose a Multilingual Language Model with deep semantic Alignment (MLMA) to generate language-independent representations for cross-lingual sequence labeling. Our methods require only monolingual corpora with no bilingual resources at all and take advantage of deep contextualized representations. Experimental results show that our approach achieves new state-of-the-art NER and POS performance across European languages, and is also effective on distant language pairs such as English and Chinese.
StructBERT: Incorporating Language Structures into Pre-training for Deep Language Understanding
Aug 16, 2019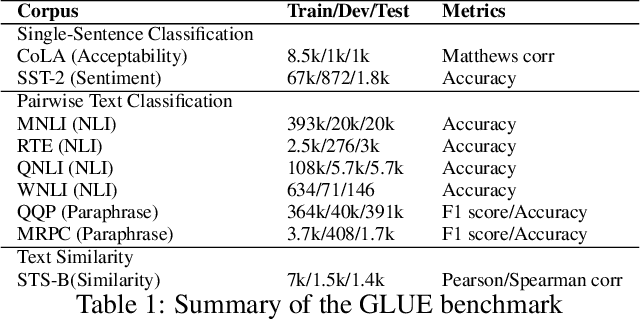
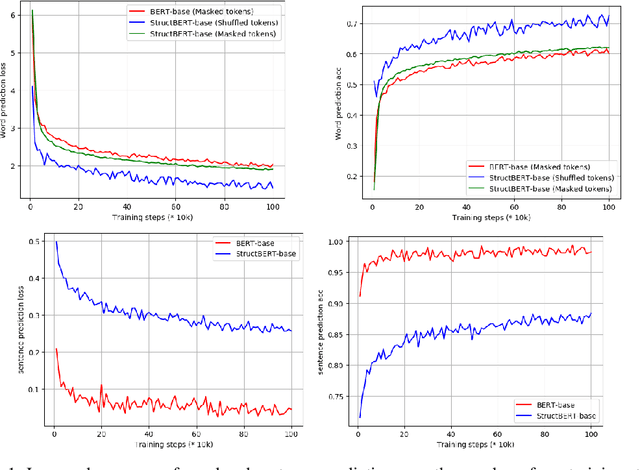
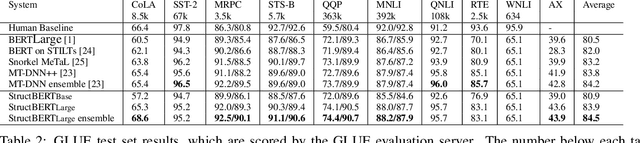

Recently, the pre-trained language model, BERT, has attracted a lot of attention in natural language understanding (NLU), and achieved state-of-the-art accuracy in various NLU tasks, such as sentiment classification, natural language inference, semantic textual similarity and question answering. Inspired by the linearization exploration work of Elman, we extend BERT to a new model, StructBERT, by incorporating language structures into pre-training. Specifically, we pre-train StructBERT with two auxiliary tasks to make the most of the sequential order of words and sentences, which leverage language structures at the word and sentence levels, respectively. As a result, the new model is adapted to different levels of language understanding required by downstream tasks. The StructBERT with structural pre-training gives surprisingly good empirical results on a variety of downstream tasks, including pushing the state-of-the-art on the GLUE benchmark to 84.5 (with Top 1 achievement on the Leaderboard at the time of paper submission), the F1 score on SQuAD v1.1 question answering to 93.0, the accuracy on SNLI to 91.7.