 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Relation Extraction as Dependency Parsing in Visually Rich Documents
Paper and Code

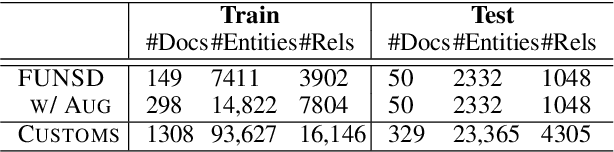
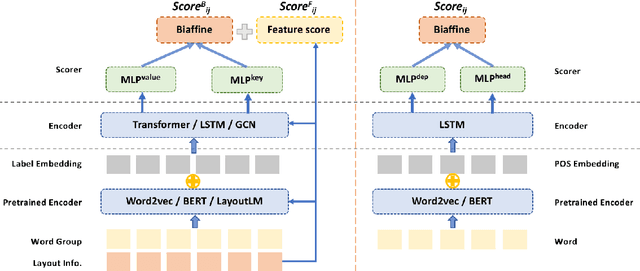
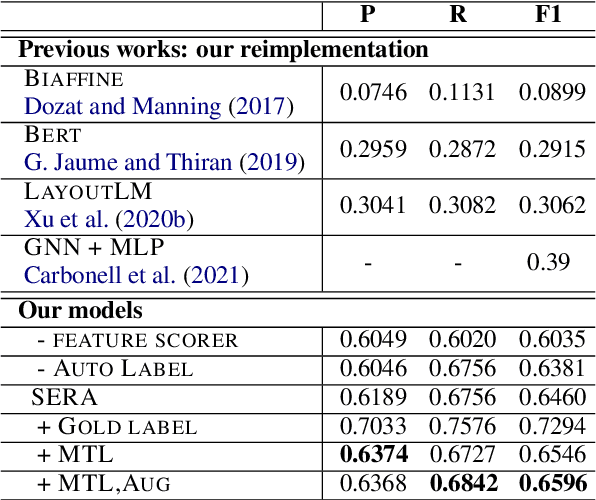
Previous works on key information extraction from visually rich documents (VRDs) mainly focus on labeling the text within each bounding box (i.e., semantic entity), while the relations in-between are largely unexplored. In this paper, we adapt the popular dependency parsing model, the biaffine parser, to this entity relation extraction task. Being different from the original dependency parsing model which recognizes dependency relations between words, we identify relations between groups of words with layout information instead. We have compared different representations of the semantic entity, different VRD encoders, and different relation decoders. The results demonstrate that our proposed model achieves 65.96% F1 score on the FUNSD dataset. As for the real-world application, our model has been applied to the in-house customs data, achieving reliable performance in the production setting.