 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuCGEC: a Multi-Reference Multi-Source Evaluation Dataset for Chinese Grammatical Error Correction
Paper and Code

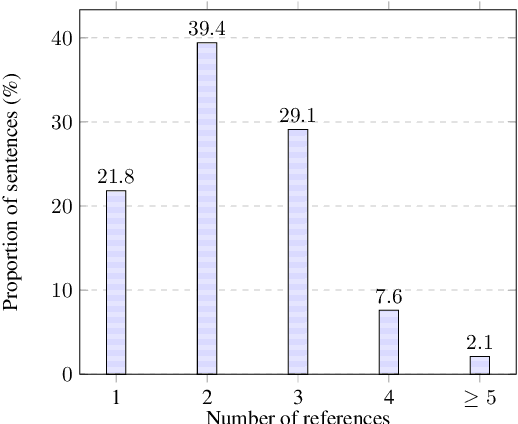
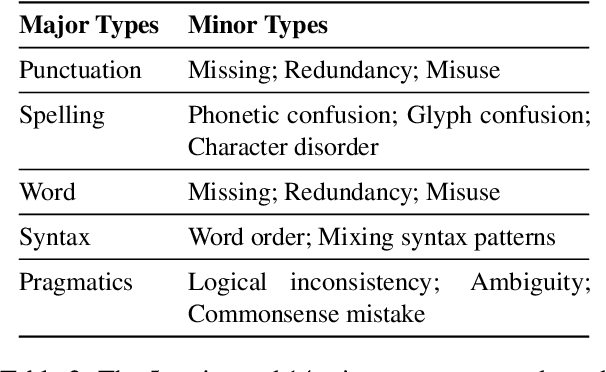
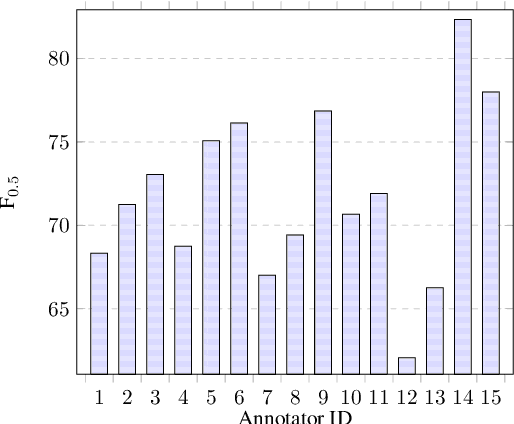
This paper presents MuCGEC, a multi-reference multi-source evaluation dataset for Chinese Grammatical Error Correction (CGEC), consisting of 7,063 sentences collected from three Chinese-as-a-Second-Language (CSL) learner sources. Each sentence is corrected by three annotators, and their corrections are carefully reviewed by a senior annotator, resulting in 2.3 references per sentence. We conduct experiments with two mainstream CGEC models, i.e., the sequence-to-sequence model and the sequence-to-edit model, both enhanced with large pretrained language models, achieving competitive benchmark performance on previous and our datasets. We also discuss CGEC evaluation methodologies, including the effect of multiple references and using a char-based metric. Our annotation guidelines, data, and code are available at \url{https://github.com/HillZhang1999/MuCGEC}.