 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVVLoc: Prior-free 3-DoF Vehicle Visual Localization
Jan 31, 2026Localization is a critical technology in autonomous driving, encompassing both topological localization, which identifies the most similar map keyframe to the current observation, and metric localization, which provides precise spatial coordinates. Conventional methods typically address these tasks independently, rely on single-camera setups, and often require additional 3D semantic or pose priors, while lacking mechanisms to quantify the confidence of localization results, making them less feasible for real industrial applications. In this paper, we propose VVLoc, a unified pipeline that employs a single neural network to concurrently achieve topological and metric vehicle localization using multi-camera system. VVLoc first evaluates the geo-proximity between visual observations, then estimates their relative metric poses using a matching strategy, while also providing a confidence measure. Additionally, the training process for VVLoc is highly efficient, requiring only pairs of visual data and corresponding ground-truth poses, eliminating the need for complex supplementary data. We evaluate VVLoc not only on the publicly available datasets, but also on a more challenging self-collected dataset, demonstrating its ability to deliver state-of-the-art localization accuracy across a wide range of localization tasks.
DG-SLAM: Robust Dynamic Gaussian Splatting SLAM with Hybrid Pose Optimization
Nov 13, 2024



Achieving robust and precise pose estimation in dynamic scenes is a significant research challenge in Visual Simultaneous Localization and Mapping (SLAM). Recent advancements integrating Gaussian Splatting into SLAM systems have proven effective in creating high-quality renderings using explicit 3D Gaussian models, significantly improving environmental reconstruction fidelity. However, these approaches depend on a static environment assumption and face challenges in dynamic environments due to inconsistent observations of geometry and photometry. To address this problem, we propose DG-SLAM, the first robust dynamic visual SLAM system grounded in 3D Gaussians, which provides precise camera pose estimation alongside high-fidelity reconstructions. Specifically, we propose effective strategies, including motion mask generation, adaptive Gaussian point management, and a hybrid camera tracking algorithm to improve the accuracy and robustness of pose estimation. Extensive experiments demonstrate that DG-SLAM delivers state-of-the-art performance in camera pose estimation, map reconstruction, and novel-view synthesis in dynamic scenes, outperforming existing methods meanwhile preserving real-time rendering ability.
A Survey on Monocular Re-Localization: From the Perspective of Scene Map Representation
Nov 27, 2023



Monocular Re-Localization (MRL) is a critical component in numerous autonomous applications, which estimates 6 degree-of-freedom poses with regards to the scene map based on a single monocular image. In recent decades, significant progress has been made in the development of MRL techniques. Numerous landmark algorithms have accomplished extraordinary success in terms of localization accuracy and robustness against visual interference. In MRL research, scene maps are represented in various forms, and they determine how MRL methods work and even how MRL methods perform. However, to the best of our knowledge, existing surveys do not provide systematic reviews of MRL from the respective of map. This survey fills the gap by comprehensively reviewing MRL methods employing monocular cameras as main sensors, promoting further research. 1) We commence by delving into the problem definition of MRL and exploring current challenges, while also comparing ours with with previous published surveys. 2) MRL methods are then categorized into five classes according to the representation forms of utilized map, i.e., geo-tagged frames, visual landmarks, point clouds, and vectorized semantic map, and we review the milestone MRL works of each category. 3) To quantitatively and fairly compare MRL methods with various map, we also review some public datasets and provide the performances of some typical MRL methods. The strengths and weakness of different types of MRL methods are analyzed. 4) We finally introduce some topics of interest in this field and give personal opinions. This survey can serve as a valuable referenced materials for newcomers and researchers interested in MRL, and a continuously updated summary of this survey, including reviewed papers and datasets, is publicly available to the community at: https://github.com/jinyummiao/map-in-mono-reloc.
Poses as Queries: Image-to-LiDAR Map Localization with Transformers
May 07, 2023



High-precision vehicle localization with commercial setups is a crucial technique for high-level autonomous driving tasks. Localization with a monocular camera in LiDAR map is a newly emerged approach that achieves promising balance between cost and accuracy, but estimating pose by finding correspondences between such cross-modal sensor data is challenging, thereby damaging the localization accuracy. In this paper, we address the problem by proposing a novel Transformer-based neural network to register 2D images into 3D LiDAR map in an end-to-end manner. Poses are implicitly represented as high-dimensional feature vectors called pose queries and can be iteratively updated by interacting with the retrieved relevant information from cross-model features using attention mechanism in a proposed POse Estimator Transformer (POET) module. Moreover, we apply a multiple hypotheses aggregation method that estimates the final poses by performing parallel optimization on multiple randomly initialized pose queries to reduce the network uncertainty. Comprehensive analysis and experimental results on public benchmark conclude that the proposed image-to-LiDAR map localization network could achieve state-of-the-art performances in challenging cross-modal localization tasks.
Map Container: A Map-based Framework for Cooperative Perception
Aug 28, 2022
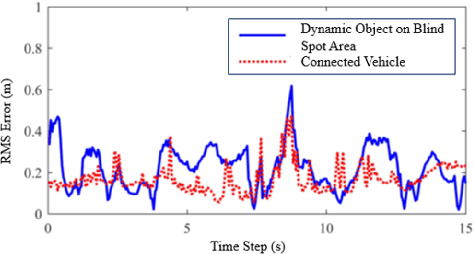
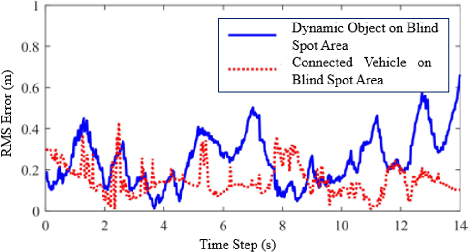

The idea of cooperative perception is to benefit from shared perception data between multiple vehicles and overcome the limitations of on-board sensors on single vehicle. However, the fusion of multi-vehicle information is still challenging due to inaccurate localization, limited communication bandwidth and ambiguous fusion. Past practices simplify the problem by placing a precise GNSS localization system, manually specify the number of connected vehicles and determine the fusion strategy. This paper proposes a map-based cooperative perception framework, named map container, to improve the accuracy and robustness of cooperative perception, which ultimately overcomes this problem. The concept 'Map Container' denotes that the map serves as the platform to transform all information into the map coordinate space automatically and incorporate different sources of information in a distributed fusion architecture. In the proposed map container, the GNSS signal and the matching relationship between sensor feature and map feature are considered to optimize the estimation of environment states. Evaluation on simulation dataset and real-vehicle platform result validates the effectiveness of the proposed method.
Multi-layer VI-GNSS Global Positioning Framework with Numerical Solution aided MAP Initialization
Jan 05, 2022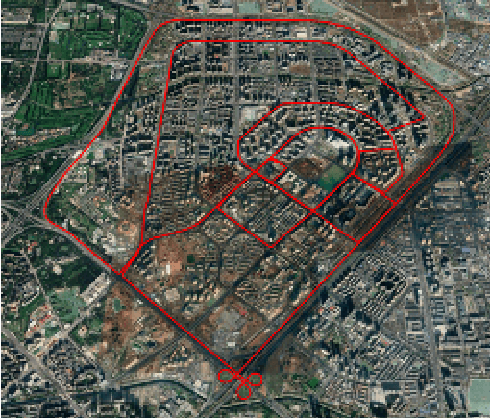
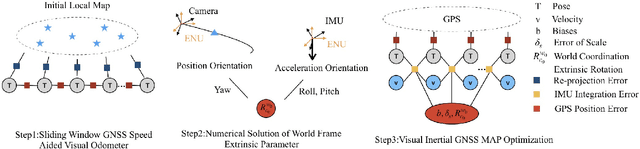
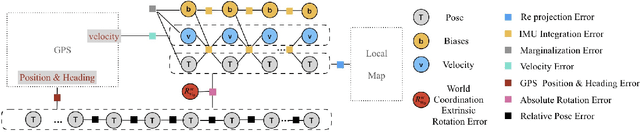
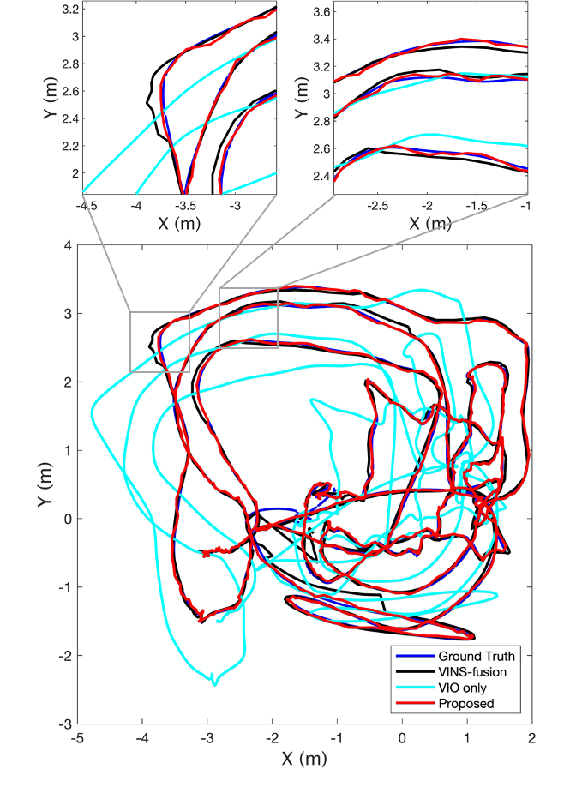
Motivated by the goal of achieving long-term drift-free camera pose estimation in complex scenarios, we propose a global positioning framework fusing visual, inertial and Global Navigation Satellite System (GNSS) measurements in multiple layers. Different from previous loosely- and tightly- coupled methods, the proposed multi-layer fusion allows us to delicately correct the drift of visual odometry and keep reliable positioning while GNSS degrades. In particular, local motion estimation is conducted in the inner-layer, solving the problem of scale drift and inaccurate bias estimation in visual odometry by fusing the velocity of GNSS, pre-integration of Inertial Measurement Unit (IMU) and camera measurement in a tightly-coupled way. The global localization is achieved in the outer-layer, where the local motion is further fused with GNSS position and course in a long-term period in a loosely-coupled way. Furthermore, a dedicated initialization method is proposed to guarantee fast and accurate estimation for all state variables and parameters. We give exhaustive tests of the proposed framework on indoor and outdoor public datasets. The mean localization error is reduced up to 63%, with a promotion of 69% in initialization accuracy compared with state-of-the-art works. We have applied the algorithm to Augmented Reality (AR) navigation, crowd sourcing high-precision map update and other large-scale applications.
Monocular Vehicle Self-localization method based on Compact Semantic Map
May 16, 2018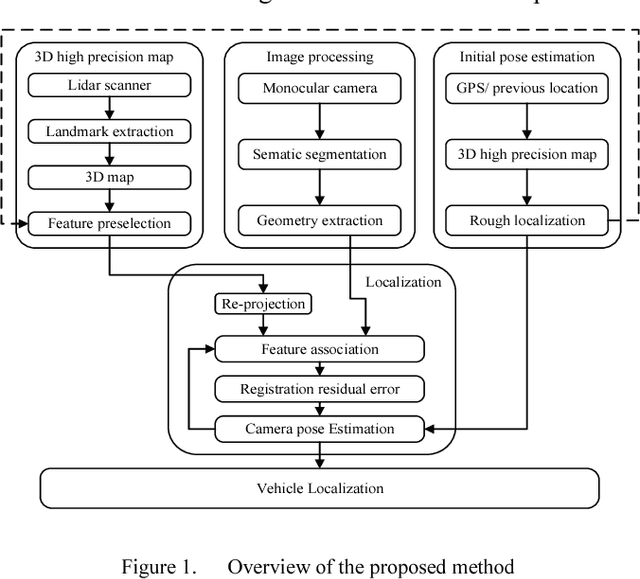

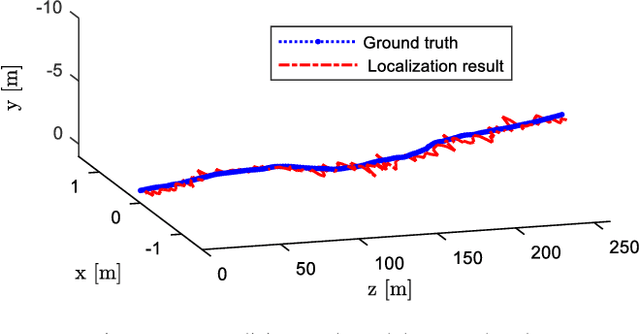

High precision localization is a crucial requirement for the autonomous driving system. Traditional positioning methods have some limitations in providing stable and accurate vehicle poses, especially in an urban environment. Herein, we propose a novel self-localizing method using a monocular camera and a 3D compact semantic map. Pre-collected information of the road landmarks is stored in a self-defined map with a minimal amount of data. We recognize landmarks using a deep neural network, followed with a geometric feature extraction process which promotes the measurement accuracy. The vehicle location and posture are estimated by minimizing a self-defined re-projection residual error to evaluate the map-to-image registration, together with a robust association method. We validate the effectiveness of our approach by applying this method to localize a vehicle in an open dataset, achieving the RMS accuracy of 0.345 meter with reduced sensor setup and map storage compared to the state of art approaches. We also evaluate some key steps and discuss the contribution of the subsystems.