 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATS-V2V: A Real-World Vehicle-to-Vehicle Cooperative Perception Dataset with Complex Adverse Traffic Scenarios
Nov 14, 2025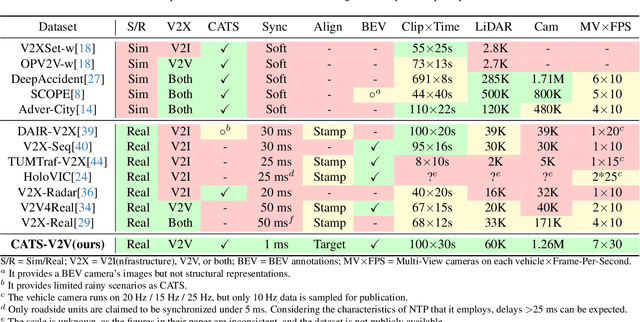


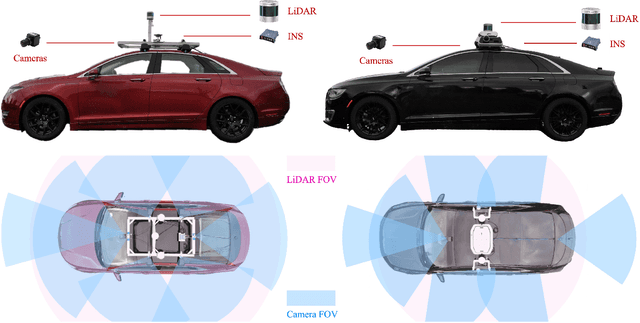
Vehicle-to-Vehicle (V2V) cooperative perception has great potential to enhance autonomous driving performance by overcoming perception limitations in complex adverse traffic scenarios (CATS). Meanwhile, data serves as the fundamental infrastructure for modern autonomous driving AI. However, due to stringent data collection requirements, existing datasets focus primarily on ordinary traffic scenarios, constraining the benefits of cooperative perception. To address this challenge, we introduce CATS-V2V, the first-of-its-kind real-world dataset for V2V cooperative perception under complex adverse traffic scenarios. The dataset was collected by two hardware time-synchronized vehicles, covering 10 weather and lighting conditions across 10 diverse locations. The 100-clip dataset includes 60K frames of 10 Hz LiDAR point clouds and 1.26M multi-view 30 Hz camera images, along with 750K anonymized yet high-precision RTK-fixed GNSS and IMU records. Correspondingly, we provide time-consistent 3D bounding box annotations for objects, as well as static scenes to construct a 4D BEV representation. On this basis, we propose a target-based temporal alignment method, ensuring that all objects are precisely aligned across all sensor modalities. We hope that CATS-V2V, the largest-scale, most supportive, and highest-quality dataset of its kind to date, will benefit the autonomous driving community in related tasks.
Monocular Vehicle Self-localization method based on Compact Semantic Map
May 16, 2018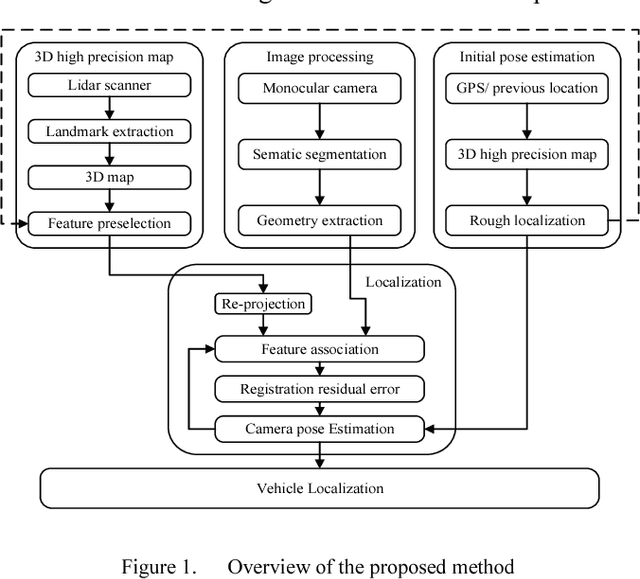

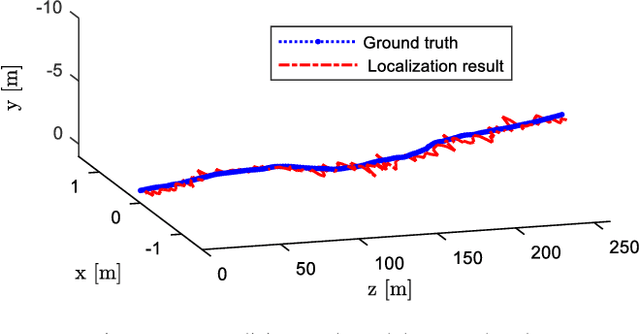

High precision localization is a crucial requirement for the autonomous driving system. Traditional positioning methods have some limitations in providing stable and accurate vehicle poses, especially in an urban environment. Herein, we propose a novel self-localizing method using a monocular camera and a 3D compact semantic map. Pre-collected information of the road landmarks is stored in a self-defined map with a minimal amount of data. We recognize landmarks using a deep neural network, followed with a geometric feature extraction process which promotes the measurement accuracy. The vehicle location and posture are estimated by minimizing a self-defined re-projection residual error to evaluate the map-to-image registration, together with a robust association method. We validate the effectiveness of our approach by applying this method to localize a vehicle in an open dataset, achieving the RMS accuracy of 0.345 meter with reduced sensor setup and map storage compared to the state of art approaches. We also evaluate some key steps and discuss the contribution of the subsystems.