 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding from Scratch: A Multi-Agent Framework with Human-in-the-Loop for Multilingual Legal Terminology Mapping
Dec 15, 2025Accurately mapping legal terminology across languages remains a significant challenge, especially for language pairs like Chinese and Japanese, which share a large number of homographs with different meanings. Existing resources and standardized tools for these languages are limited. To address this, we propose a human-AI collaborative approach for building a multilingual legal terminology database, based on a multi-agent framework. This approach integrates advanced large language models and legal domain experts throughout the entire process-from raw document preprocessing, article-level alignment, to terminology extraction, mapping, and quality assurance. Unlike a single automated pipeline, our approach places greater emphasis on how human experts participate in this multi-agent system. Humans and AI agents take on different roles: AI agents handle specific, repetitive tasks, such as OCR, text segmentation, semantic alignment, and initial terminology extraction, while human experts provide crucial oversight, review, and supervise the outputs with contextual knowledge and legal judgment. We tested the effectiveness of this framework using a trilingual parallel corpus comprising 35 key Chinese statutes, along with their English and Japanese translations. The experimental results show that this human-in-the-loop, multi-agent workflow not only improves the precision and consistency of multilingual legal terminology mapping but also offers greater scalability compared to traditional manual methods.
CATS-V2V: A Real-World Vehicle-to-Vehicle Cooperative Perception Dataset with Complex Adverse Traffic Scenarios
Nov 14, 2025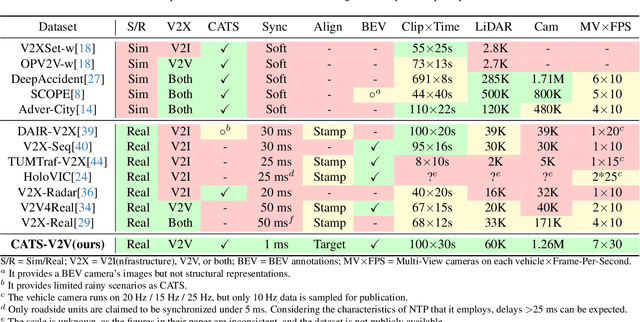


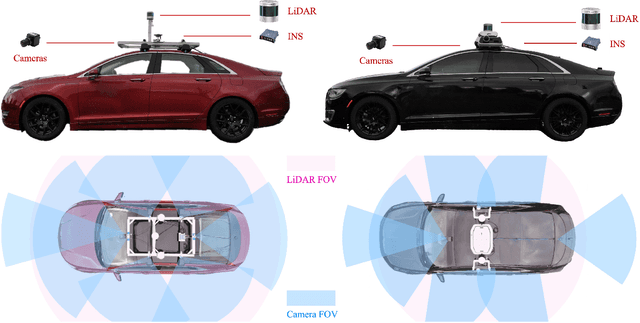
Vehicle-to-Vehicle (V2V) cooperative perception has great potential to enhance autonomous driving performance by overcoming perception limitations in complex adverse traffic scenarios (CATS). Meanwhile, data serves as the fundamental infrastructure for modern autonomous driving AI. However, due to stringent data collection requirements, existing datasets focus primarily on ordinary traffic scenarios, constraining the benefits of cooperative perception. To address this challenge, we introduce CATS-V2V, the first-of-its-kind real-world dataset for V2V cooperative perception under complex adverse traffic scenarios. The dataset was collected by two hardware time-synchronized vehicles, covering 10 weather and lighting conditions across 10 diverse locations. The 100-clip dataset includes 60K frames of 10 Hz LiDAR point clouds and 1.26M multi-view 30 Hz camera images, along with 750K anonymized yet high-precision RTK-fixed GNSS and IMU records. Correspondingly, we provide time-consistent 3D bounding box annotations for objects, as well as static scenes to construct a 4D BEV representation. On this basis, we propose a target-based temporal alignment method, ensuring that all objects are precisely aligned across all sensor modalities. We hope that CATS-V2V, the largest-scale, most supportive, and highest-quality dataset of its kind to date, will benefit the autonomous driving community in related tasks.
DSRC: Learning Density-insensitive and Semantic-aware Collaborative Representation against Corruptions
Dec 14, 2024



As a potential application of Vehicle-to-Everything (V2X) communication, multi-agent collaborative perception has achieved significant success in 3D object detection. While these methods have demonstrated impressive results on standard benchmarks, the robustness of such approaches in the face of complex real-world environments requires additional verification. To bridge this gap, we introduce the first comprehensive benchmark designed to evaluate the robustness of collaborative perception methods in the presence of natural corruptions typical of real-world environments. Furthermore, we propose DSRC, a robustness-enhanced collaborative perception method aiming to learn Density-insensitive and Semantic-aware collaborative Representation against Corruptions. DSRC consists of two key designs: i) a semantic-guided sparse-to-dense distillation framework, which constructs multi-view dense objects painted by ground truth bounding boxes to effectively learn density-insensitive and semantic-aware collaborative representation; ii) a feature-to-point cloud reconstruction approach to better fuse critical collaborative representation across agents. To thoroughly evaluate DSRC, we conduct extensive experiments on real-world and simulated datasets. The results demonstrate that our method outperforms SOTA collaborative perception methods in both clean and corrupted conditions. Code is available at https://github.com/Terry9a/DSRC.
A Comprehensive Study of PAPR Reduction Techniques for Deep Joint Source Channel Coding in OFDM Systems
Sep 21, 2023



Recently, deep joint source channel coding (DJSCC) techniques have been extensively studied and have shown significant performance with limited bandwidth and low signal to noise ratio. Most DJSCC work considers discrete-time analog transmission, while combining it with orthogonal frequency division multiplexing (OFDM) creates serious high peak-to-average power ratio (PAPR) problem. This paper conducts a comprehensive analysis on the use of various OFDM PAPR reduction techniques in the DJSCC system, including both conventional techniques such as clipping, companding, SLM and PTS, and deep learning-based PAPR reduction techniques such as PAPR loss and clipping with retraining. Our investigation shows that although conventional PAPR reduction techniques can be applied to DJSCC, their performance in DJSCC is different from the conventional split source channel coding. Moreover, we observe that for signal distortion PAPR reduction techniques, clipping with retraining achieves the best performance in terms of both PAPR reduction and recovery accuracy. It is also noticed that signal non-distortion PAPR reduction techniques can successfully reduce the PAPR in DJSCC without compromise to signal reconstruction.
Poses as Queries: Image-to-LiDAR Map Localization with Transformers
May 07, 2023



High-precision vehicle localization with commercial setups is a crucial technique for high-level autonomous driving tasks. Localization with a monocular camera in LiDAR map is a newly emerged approach that achieves promising balance between cost and accuracy, but estimating pose by finding correspondences between such cross-modal sensor data is challenging, thereby damaging the localization accuracy. In this paper, we address the problem by proposing a novel Transformer-based neural network to register 2D images into 3D LiDAR map in an end-to-end manner. Poses are implicitly represented as high-dimensional feature vectors called pose queries and can be iteratively updated by interacting with the retrieved relevant information from cross-model features using attention mechanism in a proposed POse Estimator Transformer (POET) module. Moreover, we apply a multiple hypotheses aggregation method that estimates the final poses by performing parallel optimization on multiple randomly initialized pose queries to reduce the network uncertainty. Comprehensive analysis and experimental results on public benchmark conclude that the proposed image-to-LiDAR map localization network could achieve state-of-the-art performances in challenging cross-modal localization tasks.