 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fine-to-Coarse Cuboid Shape Abstraction
Feb 03, 2025



The abstraction of 3D objects with simple geometric primitives like cuboids allows to infer structural information from complex geometry. It is important for 3D shape understanding, structural analysis and geometric modeling. We introduce a novel fine-to-coarse unsupervised learning approach to abstract collections of 3D shapes. Our architectural design allows us to reduce the number of primitives from hundreds (fine reconstruction) to only a few (coarse abstraction) during training. This allows our network to optimize the reconstruction error and adhere to a user-specified number of primitives per shape while simultaneously learning a consistent structure across the whole collection of data. We achieve this through our abstraction loss formulation which increasingly penalizes redundant primitives. Furthermore, we introduce a reconstruction loss formulation to account not only for surface approximation but also volume preservation. Combining both contributions allows us to represent 3D shapes more precisely with fewer cuboid primitives than previous work. We evaluate our method on collections of man-made and humanoid shapes comparing with previous state-of-the-art learning methods on commonly used benchmarks. Our results confirm an improvement over previous cuboid-based shape abstraction techniques. Furthermore, we demonstrate our cuboid abstraction in downstream tasks like clustering, retrieval, and partial symmetry detection.
Multidimensional Byte Pair Encoding: Shortened Sequences for Improved Visual Data Generation
Nov 15, 2024



In language processing, transformers benefit greatly from text being condensed. This is achieved through a larger vocabulary that captures word fragments instead of plain characters. This is often done with Byte Pair Encoding. In the context of images, tokenisation of visual data is usually limited to regular grids obtained from quantisation methods, without global content awareness. Our work improves tokenisation of visual data by bringing Byte Pair Encoding from 1D to multiple dimensions, as a complementary add-on to existing compression. We achieve this through counting constellations of token pairs and replacing the most frequent token pair with a newly introduced token. The multidimensionality only increases the computation time by a factor of 2 for images, making it applicable even to large datasets like ImageNet within minutes on consumer hardware. This is a lossless preprocessing step. Our evaluation shows improved training and inference performance of transformers on visual data achieved by compressing frequent constellations of tokens: The resulting sequences are shorter, with more uniformly distributed information content, e.g. condensing empty regions in an image into single tokens. As our experiments show, these condensed sequences are easier to process. We additionally introduce a strategy to amplify this compression further by clustering the vocabulary.
4Dynamic: Text-to-4D Generation with Hybrid Priors
Jul 17, 2024

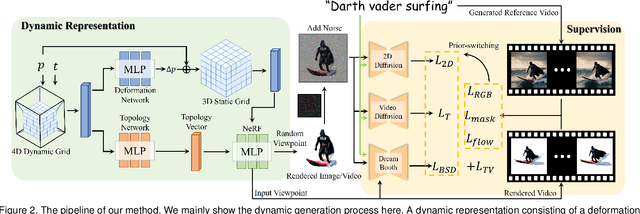

Due to the fascinating generative performance of text-to-image diffusion models, growing text-to-3D generation works explore distilling the 2D generative priors into 3D, using the score distillation sampling (SDS) loss, to bypass the data scarcity problem. The existing text-to-3D methods have achieved promising results in realism and 3D consistency, but text-to-4D generation still faces challenges, including lack of realism and insufficient dynamic motions. In this paper, we propose a novel method for text-to-4D generation, which ensures the dynamic amplitude and authenticity through direct supervision provided by a video prior. Specifically, we adopt a text-to-video diffusion model to generate a reference video and divide 4D generation into two stages: static generation and dynamic generation. The static 3D generation is achieved under the guidance of the input text and the first frame of the reference video, while in the dynamic generation stage, we introduce a customized SDS loss to ensure multi-view consistency, a video-based SDS loss to improve temporal consistency, and most importantly, direct priors from the reference video to ensure the quality of geometry and texture. Moreover, we design a prior-switching training strategy to avoid conflicts between different priors and fully leverage the benefits of each prior. In addition, to enrich the generated motion, we further introduce a dynamic modeling representation composed of a deformation network and a topology network, which ensures dynamic continuity while modeling topological changes. Our method not only supports text-to-4D generation but also enables 4D generation from monocular videos. The comparison experiments demonstrate the superiority of our method compared to existing methods.
Quantised Global Autoencoder: A Holistic Approach to Representing Visual Data
Jul 16, 2024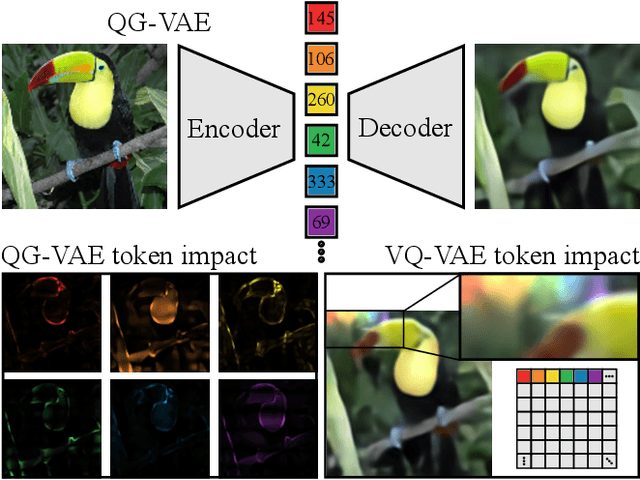
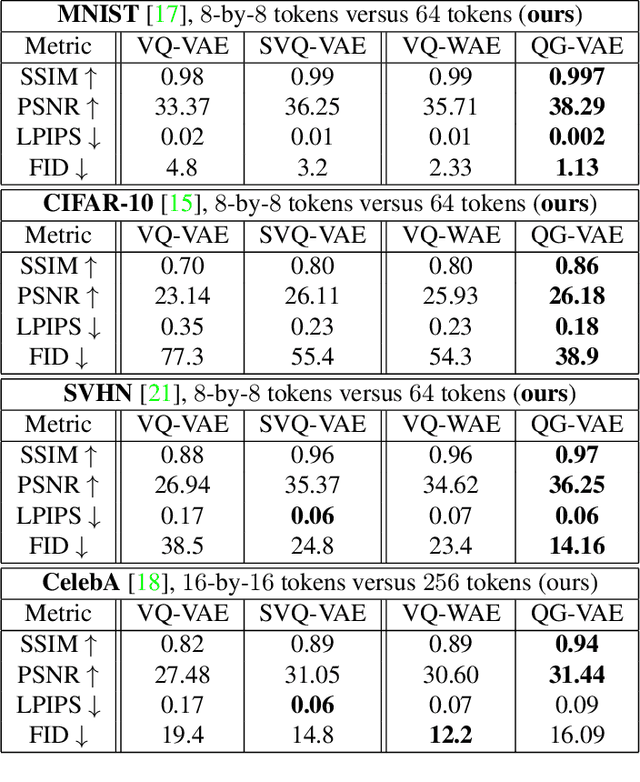
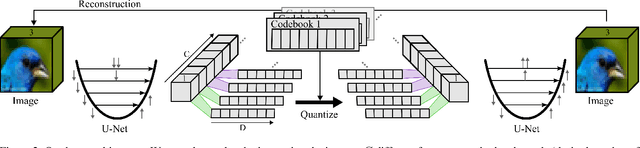
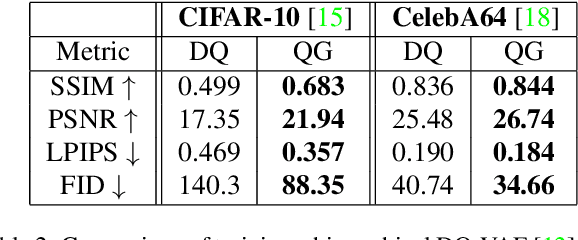
In quantised autoencoders, images are usually split into local patches, each encoded by one token. This representation is redundant in the sense that the same number of tokens is spend per region, regardless of the visual information content in that region. Adaptive discretisation schemes like quadtrees are applied to allocate tokens for patches with varying sizes, but this just varies the region of influence for a token which nevertheless remains a local descriptor. Modern architectures add an attention mechanism to the autoencoder which infuses some degree of global information into the local tokens. Despite the global context, tokens are still associated with a local image region. In contrast, our method is inspired by spectral decompositions which transform an input signal into a superposition of global frequencies. Taking the data-driven perspective, we learn custom basis functions corresponding to the codebook entries in our VQ-VAE setup. Furthermore, a decoder combines these basis functions in a non-linear fashion, going beyond the simple linear superposition of spectral decompositions. We can achieve this global description with an efficient transpose operation between features and channels and demonstrate our performance on compression.
DeferredGS: Decoupled and Editable Gaussian Splatting with Deferred Shading
Apr 15, 2024



Reconstructing and editing 3D objects and scenes both play crucial roles in computer graphics and computer vision. Neural radiance fields (NeRFs) can achieve realistic reconstruction and editing results but suffer from inefficiency in rendering. Gaussian splatting significantly accelerates rendering by rasterizing Gaussian ellipsoids. However, Gaussian splatting utilizes a single Spherical Harmonic (SH) function to model both texture and lighting, limiting independent editing capabilities of these components. Recently, attempts have been made to decouple texture and lighting with the Gaussian splatting representation but may fail to produce plausible geometry and decomposition results on reflective scenes. Additionally, the forward shading technique they employ introduces noticeable blending artifacts during relighting, as the geometry attributes of Gaussians are optimized under the original illumination and may not be suitable for novel lighting conditions. To address these issues, we introduce DeferredGS, a method for decoupling and editing the Gaussian splatting representation using deferred shading. To achieve successful decoupling, we model the illumination with a learnable environment map and define additional attributes such as texture parameters and normal direction on Gaussians, where the normal is distilled from a jointly trained signed distance function. More importantly, we apply deferred shading, resulting in more realistic relighting effects compared to previous methods. Both qualitative and quantitative experiments demonstrate the superior performance of DeferredGS in novel view synthesis and editing tasks.
Partial Symmetry Detection for 3D Geometry using Contrastive Learning with Geodesic Point Cloud Patches
Dec 13, 2023



Symmetry detection, especially partial and extrinsic symmetry, is essential for various downstream tasks, like 3D geometry completion, segmentation, compression and structure-aware shape encoding or generation. In order to detect partial extrinsic symmetries, we propose to learn rotation, reflection, translation and scale invariant local shape features for geodesic point cloud patches via contrastive learning, which are robust across multiple classes and generalize over different datasets. We show that our approach is able to extract multiple valid solutions for this ambiguous problem. Furthermore, we introduce a novel benchmark test for partial extrinsic symmetry detection to evaluate our method. Lastly, we incorporate the detected symmetries together with a region growing algorithm to demonstrate a downstream task with the goal of computing symmetry-aware partitions of 3D shapes. To our knowledge, we are the first to propose a self-supervised data-driven method for partial extrinsic symmetry detection.
Retargeting Visual Data with Deformation Fields
Nov 22, 2023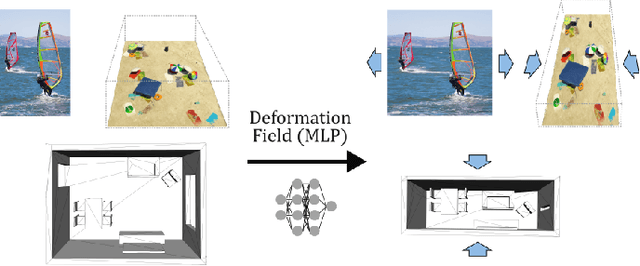

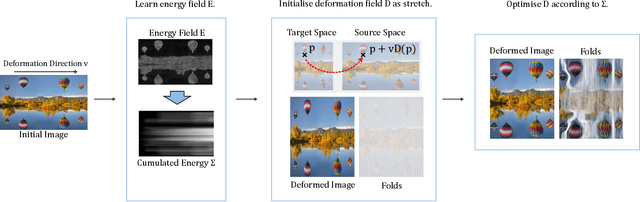
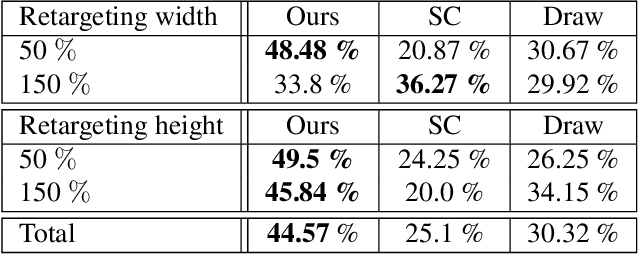
Seam carving is an image editing method that enable content-aware resizing, including operations like removing objects. However, the seam-finding strategy based on dynamic programming or graph-cut limits its applications to broader visual data formats and degrees of freedom for editing. Our observation is that describing the editing and retargeting of images more generally by a displacement field yields a generalisation of content-aware deformations. We propose to learn a deformation with a neural network that keeps the output plausible while trying to deform it only in places with low information content. This technique applies to different kinds of visual data, including images, 3D scenes given as neural radiance fields, or even polygon meshes. Experiments conducted on different visual data show that our method achieves better content-aware retargeting compared to previous methods.
Neural Implicit Shape Editing using Boundary Sensitivity
Apr 24, 2023



Neural fields are receiving increased attention as a geometric representation due to their ability to compactly store detailed and smooth shapes and easily undergo topological changes. Compared to classic geometry representations, however, neural representations do not allow the user to exert intuitive control over the shape. Motivated by this, we leverage boundary sensitivity to express how perturbations in parameters move the shape boundary. This allows to interpret the effect of each learnable parameter and study achievable deformations. With this, we perform geometric editing: finding a parameter update that best approximates a globally prescribed deformation. Prescribing the deformation only locally allows the rest of the shape to change according to some prior, such as semantics or deformation rigidity. Our method is agnostic to the model its training and updates the NN in-place. Furthermore, we show how boundary sensitivity helps to optimize and constrain objectives (such as surface area and volume), which are difficult to compute without first converting to another representation, such as a mesh.
Adaptive Voronoi NeRFs
Mar 30, 2023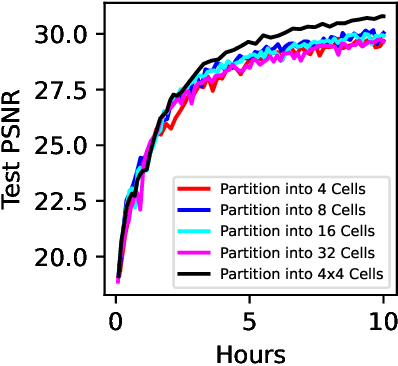
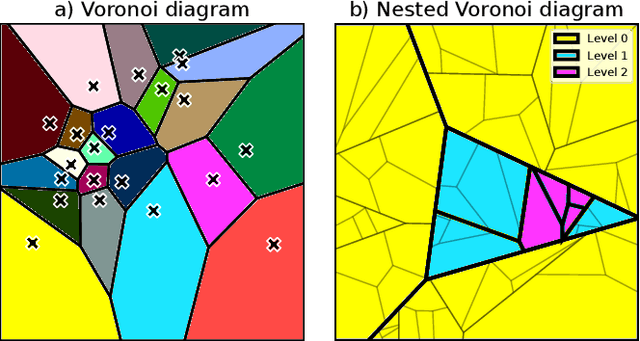

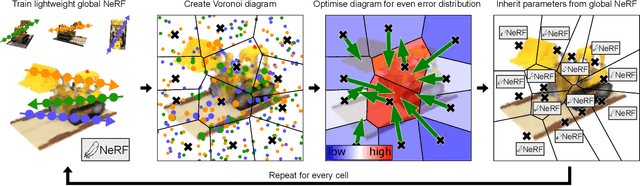
Neural Radiance Fields (NeRFs) learn to represent a 3D scene from just a set of registered images. Increasing sizes of a scene demands more complex functions, typically represented by neural networks, to capture all details. Training and inference then involves querying the neural network millions of times per image, which becomes impractically slow. Since such complex functions can be replaced by multiple simpler functions to improve speed, we show that a hierarchy of Voronoi diagrams is a suitable choice to partition the scene. By equipping each Voronoi cell with its own NeRF, our approach is able to quickly learn a scene representation. We propose an intuitive partitioning of the space that increases quality gains during training by distributing information evenly among the networks and avoids artifacts through a top-down adaptive refinement. Our framework is agnostic to the underlying NeRF method and easy to implement, which allows it to be applied to various NeRF variants for improved learning and rendering speeds.
Localized Latent Updates for Fine-Tuning Vision-Language Models
Dec 13, 2022



Although massive pre-trained vision-language models like CLIP show impressive generalization capabilities for many tasks, still it often remains necessary to fine-tune them for improved performance on specific datasets. When doing so, it is desirable that updating the model is fast and that the model does not lose its capabilities on data outside of the dataset, as is often the case with classical fine-tuning approaches. In this work we suggest a lightweight adapter, that only updates the models predictions close to seen datapoints. We demonstrate the effectiveness and speed of this relatively simple approach in the context of few-shot learning, where our results both on classes seen and unseen during training are comparable with or improve on the state of the art.