 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultidimensional Byte Pair Encoding: Shortened Sequences for Improved Visual Data Generation
Nov 15, 2024



In language processing, transformers benefit greatly from text being condensed. This is achieved through a larger vocabulary that captures word fragments instead of plain characters. This is often done with Byte Pair Encoding. In the context of images, tokenisation of visual data is usually limited to regular grids obtained from quantisation methods, without global content awareness. Our work improves tokenisation of visual data by bringing Byte Pair Encoding from 1D to multiple dimensions, as a complementary add-on to existing compression. We achieve this through counting constellations of token pairs and replacing the most frequent token pair with a newly introduced token. The multidimensionality only increases the computation time by a factor of 2 for images, making it applicable even to large datasets like ImageNet within minutes on consumer hardware. This is a lossless preprocessing step. Our evaluation shows improved training and inference performance of transformers on visual data achieved by compressing frequent constellations of tokens: The resulting sequences are shorter, with more uniformly distributed information content, e.g. condensing empty regions in an image into single tokens. As our experiments show, these condensed sequences are easier to process. We additionally introduce a strategy to amplify this compression further by clustering the vocabulary.
Intuitive Shape Editing in Latent Space
Nov 24, 2021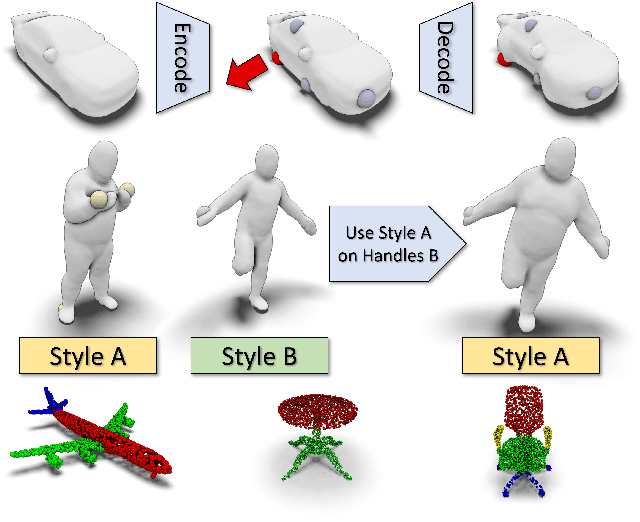
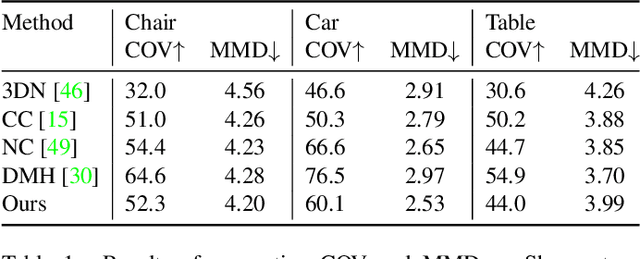
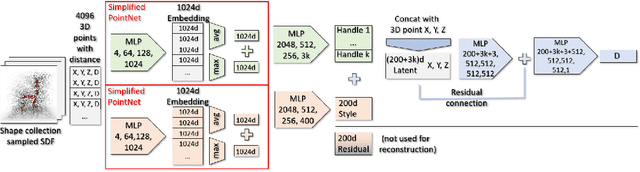
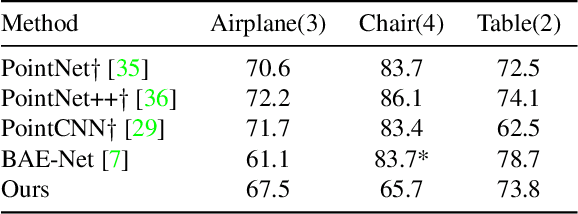
The use of autoencoders for shape generation and editing suffers from manipulations in latent space that may lead to unpredictable changes in the output shape. We present an autoencoder-based method that enables intuitive shape editing in latent space by disentangling latent sub-spaces to obtain control points on the surface and style variables that can be manipulated independently. The key idea is adding a Lipschitz-type constraint to the loss function, i.e. bounding the change of the output shape proportionally to the change in latent space, leading to interpretable latent space representations. The control points on the surface can then be freely moved around, allowing for intuitive shape editing directly in latent space. We evaluate our method by comparing it to state-of-the-art data-driven shape editing methods. Besides shape manipulation, we demonstrate the expressiveness of our control points by leveraging them for unsupervised part segmentation.
Highly accurate digital traffic recording as a basis for future mobility research: Methods and concepts of the research project HDV-Mess
Jun 08, 2021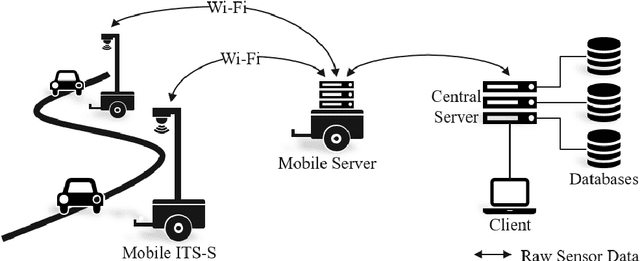
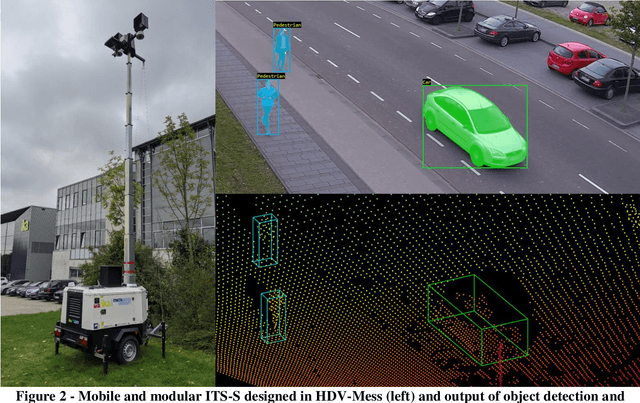
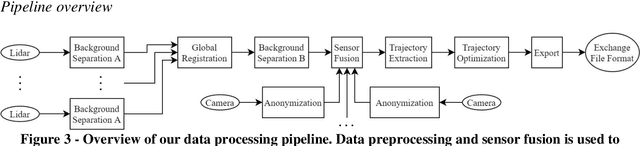
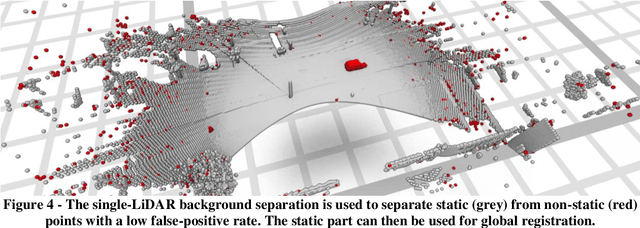
The research project HDV-Mess aims at a currently missing, but very crucial component for addressing important challenges in the field of connected and automated driving on public roads. The goal is to record traffic events at various relevant locations with high accuracy and to collect real traffic data as a basis for the development and validation of current and future sensor technologies as well as automated driving functions. For this purpose, it is necessary to develop a concept for a mobile modular system of measuring stations for highly accurate traffic data acquisition, which enables a temporary installation of a sensor and communication infrastructure at different locations. Within this paper, we first discuss the project goals before we present our traffic detection concept using mobile modular intelligent transport systems stations (ITS-Ss). We then explain the approaches for data processing of sensor raw data to refined trajectories, data communication, and data validation.