 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultidimensional Byte Pair Encoding: Shortened Sequences for Improved Visual Data Generation
Nov 15, 2024



In language processing, transformers benefit greatly from text being condensed. This is achieved through a larger vocabulary that captures word fragments instead of plain characters. This is often done with Byte Pair Encoding. In the context of images, tokenisation of visual data is usually limited to regular grids obtained from quantisation methods, without global content awareness. Our work improves tokenisation of visual data by bringing Byte Pair Encoding from 1D to multiple dimensions, as a complementary add-on to existing compression. We achieve this through counting constellations of token pairs and replacing the most frequent token pair with a newly introduced token. The multidimensionality only increases the computation time by a factor of 2 for images, making it applicable even to large datasets like ImageNet within minutes on consumer hardware. This is a lossless preprocessing step. Our evaluation shows improved training and inference performance of transformers on visual data achieved by compressing frequent constellations of tokens: The resulting sequences are shorter, with more uniformly distributed information content, e.g. condensing empty regions in an image into single tokens. As our experiments show, these condensed sequences are easier to process. We additionally introduce a strategy to amplify this compression further by clustering the vocabulary.
Quantised Global Autoencoder: A Holistic Approach to Representing Visual Data
Jul 16, 2024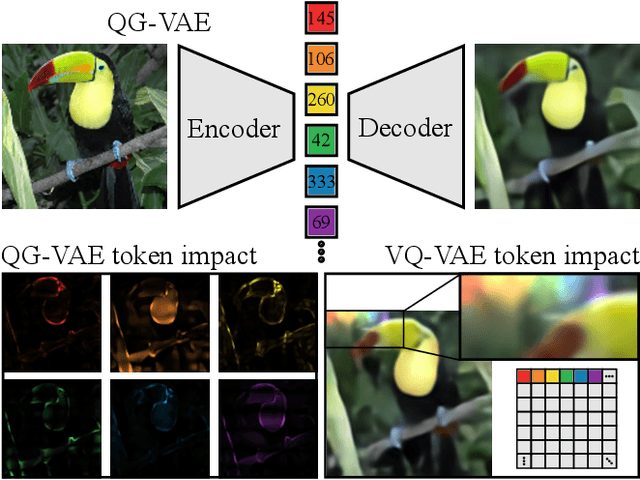
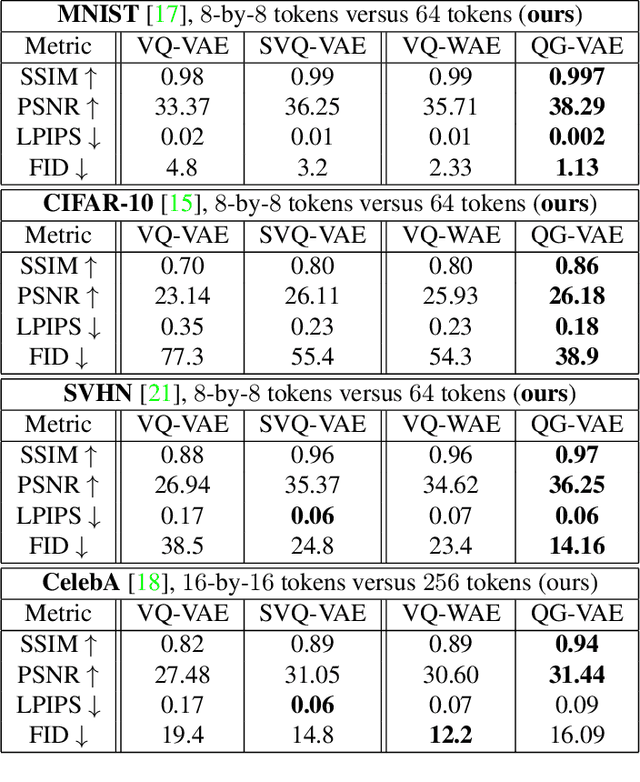
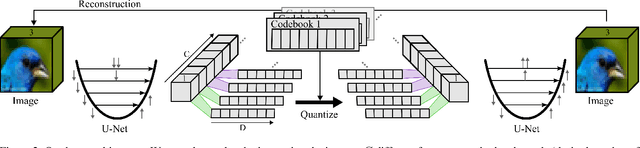
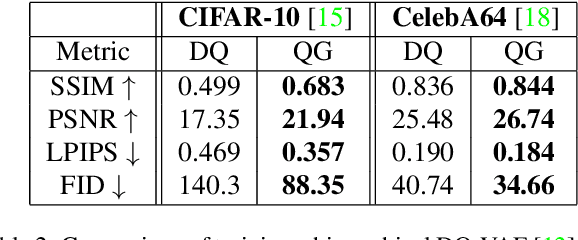
In quantised autoencoders, images are usually split into local patches, each encoded by one token. This representation is redundant in the sense that the same number of tokens is spend per region, regardless of the visual information content in that region. Adaptive discretisation schemes like quadtrees are applied to allocate tokens for patches with varying sizes, but this just varies the region of influence for a token which nevertheless remains a local descriptor. Modern architectures add an attention mechanism to the autoencoder which infuses some degree of global information into the local tokens. Despite the global context, tokens are still associated with a local image region. In contrast, our method is inspired by spectral decompositions which transform an input signal into a superposition of global frequencies. Taking the data-driven perspective, we learn custom basis functions corresponding to the codebook entries in our VQ-VAE setup. Furthermore, a decoder combines these basis functions in a non-linear fashion, going beyond the simple linear superposition of spectral decompositions. We can achieve this global description with an efficient transpose operation between features and channels and demonstrate our performance on compression.