 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Implicit Shape Editing using Boundary Sensitivity
Apr 24, 2023



Neural fields are receiving increased attention as a geometric representation due to their ability to compactly store detailed and smooth shapes and easily undergo topological changes. Compared to classic geometry representations, however, neural representations do not allow the user to exert intuitive control over the shape. Motivated by this, we leverage boundary sensitivity to express how perturbations in parameters move the shape boundary. This allows to interpret the effect of each learnable parameter and study achievable deformations. With this, we perform geometric editing: finding a parameter update that best approximates a globally prescribed deformation. Prescribing the deformation only locally allows the rest of the shape to change according to some prior, such as semantics or deformation rigidity. Our method is agnostic to the model its training and updates the NN in-place. Furthermore, we show how boundary sensitivity helps to optimize and constrain objectives (such as surface area and volume), which are difficult to compute without first converting to another representation, such as a mesh.
Localized Latent Updates for Fine-Tuning Vision-Language Models
Dec 13, 2022



Although massive pre-trained vision-language models like CLIP show impressive generalization capabilities for many tasks, still it often remains necessary to fine-tune them for improved performance on specific datasets. When doing so, it is desirable that updating the model is fast and that the model does not lose its capabilities on data outside of the dataset, as is often the case with classical fine-tuning approaches. In this work we suggest a lightweight adapter, that only updates the models predictions close to seen datapoints. We demonstrate the effectiveness and speed of this relatively simple approach in the context of few-shot learning, where our results both on classes seen and unseen during training are comparable with or improve on the state of the art.
Intuitive Shape Editing in Latent Space
Nov 24, 2021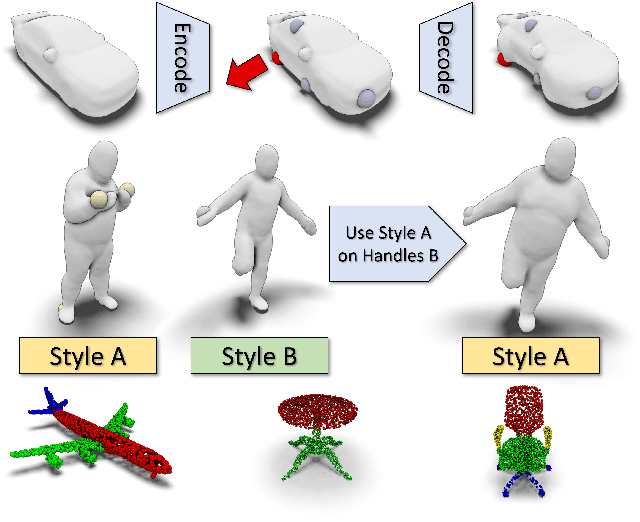
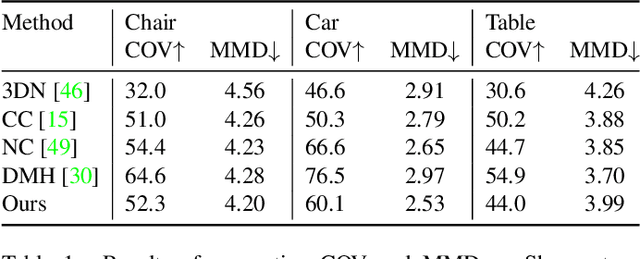
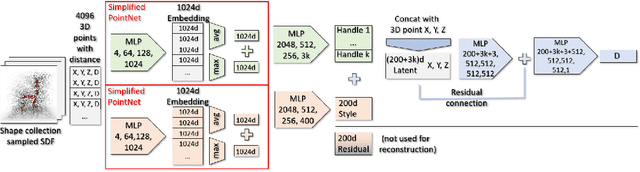
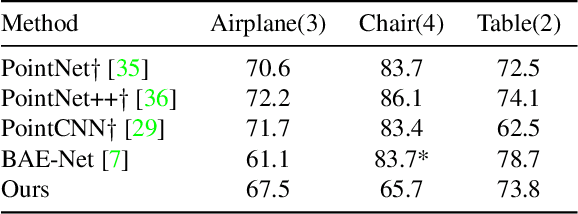
The use of autoencoders for shape generation and editing suffers from manipulations in latent space that may lead to unpredictable changes in the output shape. We present an autoencoder-based method that enables intuitive shape editing in latent space by disentangling latent sub-spaces to obtain control points on the surface and style variables that can be manipulated independently. The key idea is adding a Lipschitz-type constraint to the loss function, i.e. bounding the change of the output shape proportionally to the change in latent space, leading to interpretable latent space representations. The control points on the surface can then be freely moved around, allowing for intuitive shape editing directly in latent space. We evaluate our method by comparing it to state-of-the-art data-driven shape editing methods. Besides shape manipulation, we demonstrate the expressiveness of our control points by leveraging them for unsupervised part segmentation.
Octree Transformer: Autoregressive 3D Shape Generation on Hierarchically Structured Sequences
Nov 24, 2021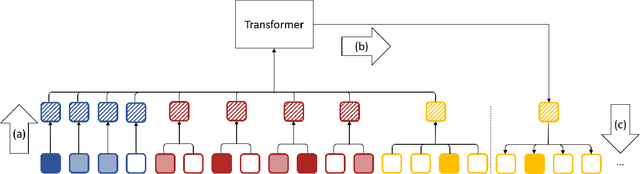
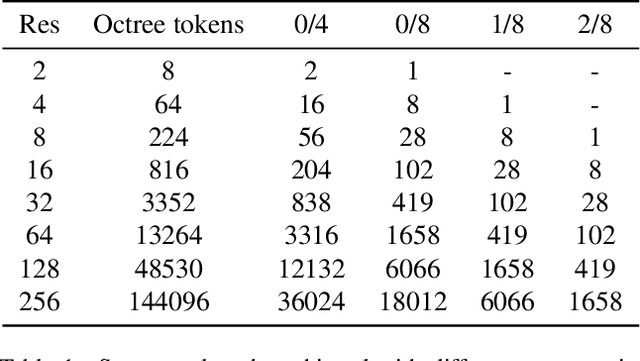
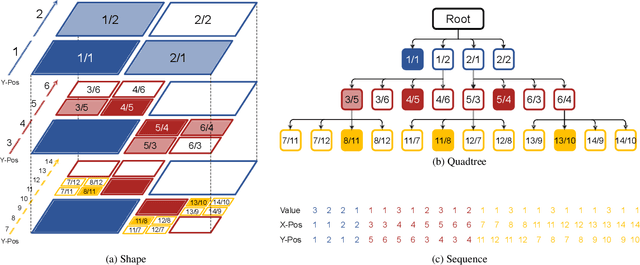
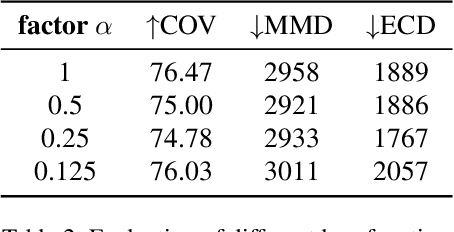
Autoregressive models have proven to be very powerful in NLP text generation tasks and lately have gained popularity for image generation as well. However, they have seen limited use for the synthesis of 3D shapes so far. This is mainly due to the lack of a straightforward way to linearize 3D data as well as to scaling problems with the length of the resulting sequences when describing complex shapes. In this work we address both of these problems. We use octrees as a compact hierarchical shape representation that can be sequentialized by traversal ordering. Moreover, we introduce an adaptive compression scheme, that significantly reduces sequence lengths and thus enables their effective generation with a transformer, while still allowing fully autoregressive sampling and parallel training. We demonstrate the performance of our model by comparing against the state-of-the-art in shape generation.
3D Shape Generation with Grid-based Implicit Functions
Jul 22, 2021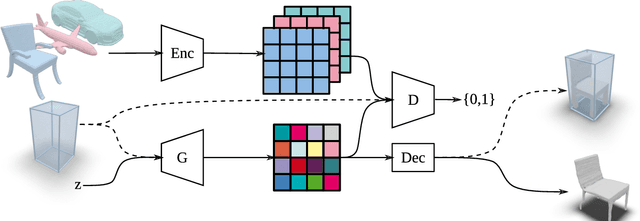
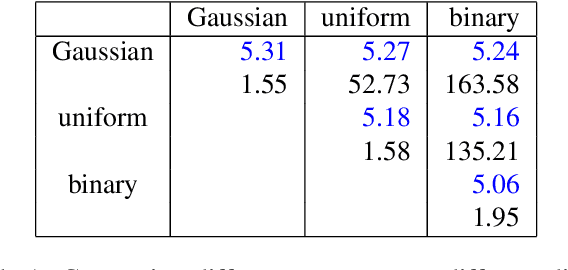
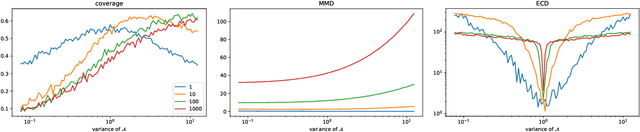
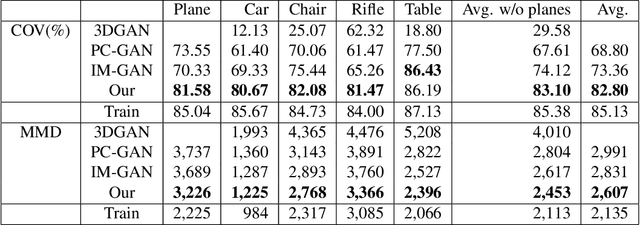
Previous approaches to generate shapes in a 3D setting train a GAN on the latent space of an autoencoder (AE). Even though this produces convincing results, it has two major shortcomings. As the GAN is limited to reproduce the dataset the AE was trained on, we cannot reuse a trained AE for novel data. Furthermore, it is difficult to add spatial supervision into the generation process, as the AE only gives us a global representation. To remedy these issues, we propose to train the GAN on grids (i.e. each cell covers a part of a shape). In this representation each cell is equipped with a latent vector provided by an AE. This localized representation enables more expressiveness (since the cell-based latent vectors can be combined in novel ways) as well as spatial control of the generation process (e.g. via bounding boxes). Our method outperforms the current state of the art on all established evaluation measures, proposed for quantitatively evaluating the generative capabilities of GANs. We show limitations of these measures and propose the adaptation of a robust criterion from statistical analysis as an alternative.
A Convolutional Decoder for Point Clouds using Adaptive Instance Normalization
Jun 27, 2019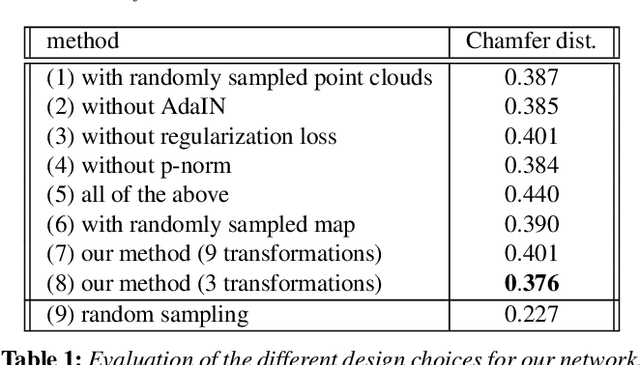
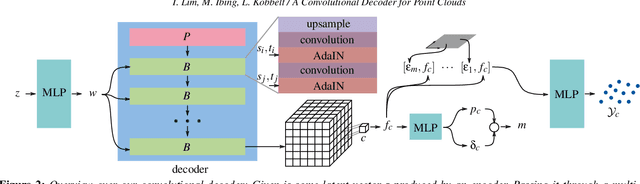

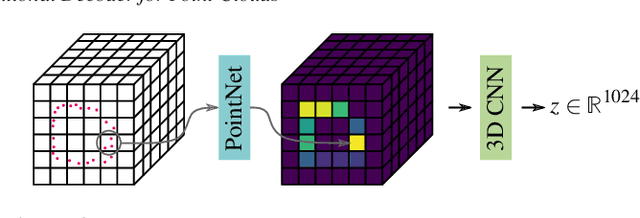
Automatic synthesis of high quality 3D shapes is an ongoing and challenging area of research. While several data-driven methods have been proposed that make use of neural networks to generate 3D shapes, none of them reach the level of quality that deep learning synthesis approaches for images provide. In this work we present a method for a convolutional point cloud decoder/generator that makes use of recent advances in the domain of image synthesis. Namely, we use Adaptive Instance Normalization and offer an intuition on why it can improve training. Furthermore, we propose extensions to the minimization of the commonly used Chamfer distance for auto-encoding point clouds. In addition, we show that careful sampling is important both for the input geometry and in our point cloud generation process to improve results. The results are evaluated in an auto-encoding setup to offer both qualitative and quantitative analysis. The proposed decoder is validated by an extensive ablation study and is able to outperform current state of the art results in a number of experiments. We show the applicability of our method in the fields of point cloud upsampling, single view reconstruction, and shape synthesis.
* Symposium on Geometry Processing 2019