 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthSync: Diffusion Guidance-Based Depth Synchronization for Scale- and Geometry-Consistent Video Depth Estimation
Jul 02, 2025
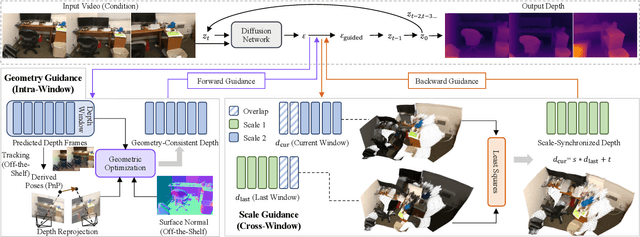

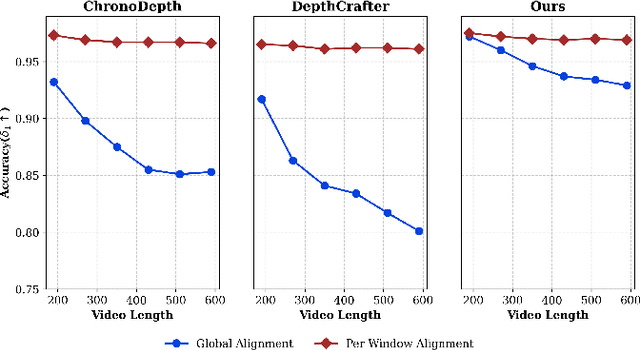
Diffusion-based video depth estimation methods have achieved remarkable success with strong generalization ability. However, predicting depth for long videos remains challenging. Existing methods typically split videos into overlapping sliding windows, leading to accumulated scale discrepancies across different windows, particularly as the number of windows increases. Additionally, these methods rely solely on 2D diffusion priors, overlooking the inherent 3D geometric structure of video depths, which results in geometrically inconsistent predictions. In this paper, we propose DepthSync, a novel, training-free framework using diffusion guidance to achieve scale- and geometry-consistent depth predictions for long videos. Specifically, we introduce scale guidance to synchronize the depth scale across windows and geometry guidance to enforce geometric alignment within windows based on the inherent 3D constraints in video depths. These two terms work synergistically, steering the denoising process toward consistent depth predictions. Experiments on various datasets validate the effectiveness of our method in producing depth estimates with improved scale and geometry consistency, particularly for long videos.
PPEA-Depth: Progressive Parameter-Efficient Adaptation for Self-Supervised Monocular Depth Estimation
Jan 17, 2024



Self-supervised monocular depth estimation is of significant importance with applications spanning across autonomous driving and robotics. However, the reliance on self-supervision introduces a strong static-scene assumption, thereby posing challenges in achieving optimal performance in dynamic scenes, which are prevalent in most real-world situations. To address these issues, we propose PPEA-Depth, a Progressive Parameter-Efficient Adaptation approach to transfer a pre-trained image model for self-supervised depth estimation. The training comprises two sequential stages: an initial phase trained on a dataset primarily composed of static scenes, succeeded by an expansion to more intricate datasets involving dynamic scenes. To facilitate this process, we design compact encoder and decoder adapters to enable parameter-efficient tuning, allowing the network to adapt effectively. They not only uphold generalized patterns from pre-trained image models but also retain knowledge gained from the preceding phase into the subsequent one. Extensive experiments demonstrate that PPEA-Depth achieves state-of-the-art performance on KITTI, CityScapes and DDAD datasets.
ORBBuf: A Robust Buffering Method for Collaborative Visual SLAM
Oct 28, 2020

Collaborative simultaneous localization and mapping (SLAM) approaches provide a solution for autonomous robots based on embedded devices. On the other hand, visual SLAM systems rely on correlations between visual frames. As a result, the loss of visual frames from an unreliable wireless network can easily damage the results of collaborative visual SLAM systems. From our experiment, a loss of less than 1 second of data can lead to the failure of visual SLAM algorithms. We present a novel buffering method, ORBBuf, to reduce the impact of data loss on collaborative visual SLAM systems. We model the buffering problem into an optimization problem. We use an efficient greedy-like algorithm, and our buffering method drops the frame that results in the least loss to the quality of the SLAM results. We implement our ORBBuf method on ROS, a widely used middleware framework. Through an extensive evaluation on real-world scenarios and tens of gigabytes of datasets, we demonstrate that our ORBBuf method can be applied to different algorithms, different sensor data (both monocular images and stereo images), different scenes (both indoor and outdoor), and different network environments (both WiFi networks and 4G networks). Experimental results show that the network interruptions indeed affect the SLAM results, and our ORBBuf method can reduce the RMSE up to 50 times.